
{kind=link}
[ad_1]
In visible understanding, the Visible Transformer (ViT) and its variants have acquired important consideration lately attributable to their superior efficiency on many core visible functions, reminiscent of picture classification, object detection, and video understanding. The core concept of ViT is to make the most of the ability of self-attention layers to be taught world relationships between small patches of photos. Nonetheless, the variety of connections between patches will increase quadratically with picture dimension. Such a design has been noticed to be information inefficient — though the unique ViT can carry out higher than convolutional networks with tons of of tens of millions of photos for pre-training, such a knowledge requirement is just not all the time sensible, and it nonetheless underperforms in comparison with convolutional networks when given much less information. Many are exploring to seek out extra appropriate architectural re-designs that may be taught visible representations successfully, reminiscent of by including convolutional layers and constructing hierarchical constructions with native self-attention.
The precept of hierarchical construction is without doubt one of the core concepts in imaginative and prescient fashions, the place backside layers be taught extra native object constructions on the high-dimensional pixel house and prime layers be taught extra abstracted and high-level data at low-dimensional characteristic house. Present ViT-based strategies concentrate on designing a wide range of modifications inside self-attention layers to realize such a hierarchy, however whereas these supply promising efficiency enhancements, they typically require substantial architectural re-designs. Furthermore, these approaches lack an interpretable design, so it’s troublesome to clarify the inner-workings of skilled fashions.
To handle these challenges, in “Nested Hierarchical Transformer: In direction of Correct, Information-Environment friendly and Interpretable Visible Understanding”, we current a rethinking of present hierarchical construction–pushed designs, and supply a novel and orthogonal strategy to considerably simplify them. The central concept of this work is to decouple characteristic studying and have abstraction (pooling) parts: nested transformer layers encode visible data of picture patches individually, after which the processed data is aggregated. This course of is repeated in a hierarchical method, leading to a pyramid community construction. The ensuing structure achieves aggressive outcomes on ImageNet and outperforms outcomes on data-efficient benchmarks. We have now proven such a design can meaningfully enhance information effectivity with quicker convergence and supply useful interpretability advantages. Furthermore, we introduce GradCAT, a brand new approach for deciphering the choice means of a skilled mannequin at inference time.
Structure Design
The general structure is easy to implement by including just some strains of Python code to the supply code of the unique ViT. The unique ViT structure divides an enter picture into small patches, tasks pixels of every patch to a vector with predefined dimension, after which feeds the sequences of all vectors to the general ViT structure containing a number of stacked equivalent transformer layers. Whereas each layer in ViT processes data of the entire picture, with this new technique, stacked transformer layers are used to course of solely a area (i.e., block) of the picture containing just a few spatially adjoining picture patches. This step is unbiased for every block and can also be the place characteristic studying happens. Lastly, a brand new computational layer known as block aggregation then combines all the spatially adjoining blocks. After every block aggregation, the options equivalent to 4 spatially adjoining blocks are fed to a different module with a stack of transformer layers, which then course of these 4 blocks collectively. This design naturally builds a pyramid hierarchical construction of the community, the place backside layers can concentrate on native options (reminiscent of textures) and higher layers concentrate on world options (reminiscent of object form) at lowered dimensionality because of the block aggregation.
 |
| A visualization of the community processing a picture: Given an enter picture, the community first partitions photos into blocks, the place every block incorporates 4 picture patches. Picture patches in each block are linearly projected as vectors and processed by a stack of equivalent transformer layers. Then the proposed block aggregation layer aggregates data from every block and reduces its spatial dimension by 4 occasions. The variety of blocks is lowered to 1 on the prime hierarchy and classification is carried out after the output of it. |
Interpretability
This structure has a non-overlapping data processing mechanism, unbiased at each node. This design resembles a resolution tree-like construction, which manifests distinctive interpretability capabilities as a result of each tree node incorporates unbiased data of a picture block that’s being acquired by its dad or mum nodes. We are able to hint the knowledge move by means of the nodes to know the significance of every characteristic. As well as, our hierarchical construction retains the spatial construction of photos all through the community, resulting in discovered spatial characteristic maps which might be efficient for interpretation. Beneath we showcase two sorts of visible interpretability.
First, we current a way to interpret the skilled mannequin on check photos, known as gradient-based class-aware tree-traversal (GradCAT). GradCAT traces the characteristic significance of every block (a tree node) from prime to backside of the hierarchy construction. The primary concept is to seek out probably the most useful traversal from the basis node on the prime layer to a baby node on the backside layer that contributes probably the most to the classification outcomes. Since every node processes data from a sure area of the picture, such traversal will be simply mapped to the picture house for interpretation (as proven by the overlaid dots and features within the picture beneath).
The next is an instance of the mannequin’s top-4 predictions and corresponding interpretability outcomes on the left enter picture (containing 4 animals). As proven beneath, GradCAT highlights the choice path alongside the hierarchical construction in addition to the corresponding visible cues in native picture areas on the photographs.
 |
| Given the left enter picture (containing 4 objects), the determine visualizes the interpretability outcomes of the top-4 prediction lessons. The traversal locates the mannequin resolution path alongside the tree and concurrently locates the corresponding picture patch (proven by the dotted line on photos) that has the best affect to the anticipated goal class. |
Furthermore, the next figures visualize outcomes on the ImageNet validation set and present how this strategy allows some intuitive observations. As an example, the instance of the lighter beneath (higher left panel) is especially fascinating as a result of the bottom reality class — lighter/matchstick — truly defines the bottom-right matchstick object, whereas probably the most salient visible options (with the best node values) are literally from the upper-left pink gentle, which conceptually shares visible cues with a lighter. This may also be seen from the overlaid pink strains, which point out the picture patches with the best affect on the prediction. Thus, though the visible cue is a mistake, the output prediction is right. As well as, the 4 youngster nodes of the wood spoon beneath have comparable characteristic significance values (see numbers visualized within the nodes; increased signifies extra significance), which is as a result of the wood texture of the desk is just like that of the spoon.
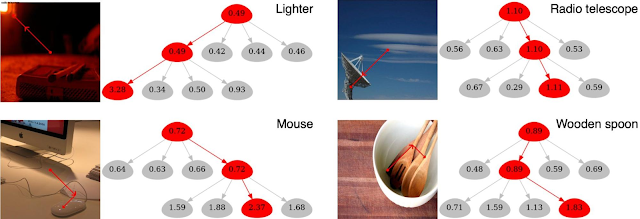 |
| Visualization of the outcomes obtained by the proposed GradCAT. Photos are from the ImageNet validation dataset. |
Second, completely different from the unique ViT, our hierarchical structure retains spatial relationships in discovered representations. The highest layers output low-resolution options maps of enter photos, enabling the mannequin to simply carry out attention-based interpretation by making use of Class Consideration Map (CAM) on the discovered representations on the prime hierarchical stage. This permits high-quality weakly-supervised object localization with simply image-level labels. See the next determine for examples.
 |
| Visualization of CAM-based consideration outcomes. Hotter colours point out increased consideration. Photos are from the ImageNet validation dataset. |
Convergence Benefits
With this design, characteristic studying solely occurs at native areas independently, and have abstraction occurs contained in the aggregation perform. This design and easy implementation is basic sufficient for different forms of visible understanding duties past classification. It additionally improves the mannequin convergence velocity drastically, considerably lowering the coaching time to succeed in the specified most accuracy.
We validate this benefit in two methods. First, we examine the ViT construction on the ImageNet accuracy with a unique variety of whole coaching epochs. The outcomes are proven on the left facet of the determine beneath, demonstrating a lot quicker convergence than the unique ViT, e.g., round 20% enchancment in accuracy over ViT with 30 whole coaching epochs.
Second, we modify the structure to conduct unconditional picture era duties, since coaching ViT-based fashions for picture era duties is difficult attributable to convergence and velocity points. Creating such a generator is simple by transposing the proposed structure: the enter is an embedding vector, the output is a full picture in RGB channels, and the block aggregation is changed by a block de-aggregation element supported by Pixel Shuffling. Surprisingly, we discover our generator is simple to coach and demonstrates quicker convergence velocity, in addition to higher FID rating (which measures how comparable generated photos are to actual ones), than the capacity-comparable SAGAN.
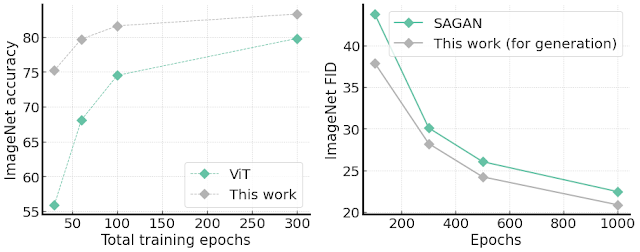 |
| Left: ImageNet accuracy given completely different variety of whole coaching epochs in contrast with normal ViT structure. Proper: ImageNet 64×64 picture era FID scores (decrease is healthier) with single 1000-epoch coaching. On each duties, our technique reveals higher convergence velocity. |
Conclusion
On this work we exhibit the easy concept that decoupled characteristic studying and have data extraction on this nested hierarchy design results in higher characteristic interpretability by means of a brand new gradient-based class-aware tree traversal technique. Furthermore, the structure improves convergence on not solely classification duties but additionally picture era duties. The proposed concept is specializing in aggregation perform and thereby is orthogonal to superior structure design for self-attention. We hope this new analysis encourages future structure designers to discover extra interpretable and data-efficient ViT-based fashions for visible understanding, just like the adoption of this work for high-resolution picture era. We have now additionally launched the supply code for the picture classification portion of this work.
Acknowledgements
We gratefully acknowledge the contributions of different co-authors, together with Han Zhang, Lengthy Zhao, Ting Chen, Sercan Arik, Tomas Pfister. We additionally thank Xiaohua Zhai, Jeremy Kubica, Kihyuk Sohn, and Madeleine Udell for the dear suggestions of the work.
[ad_2]