
{kind=link}
[ad_1]
Machine studying (ML) fashions are getting used extra extensively as we speak than ever earlier than and have gotten more and more impactful. Nonetheless, they typically exhibit surprising conduct when they’re utilized in real-world domains. For instance, pc imaginative and prescient fashions can exhibit shocking sensitivity to irrelevant options, whereas pure language processing fashions can rely unpredictably on demographic correlations circuitously indicated by the textual content. Some causes for these failures are well-known: for instance, coaching ML fashions on poorly curated knowledge, or coaching fashions to unravel prediction issues which might be structurally mismatched with the appliance area. But, even when these identified issues are dealt with, mannequin conduct can nonetheless be inconsistent in deployment, various even between coaching runs.
In “Underspecification Presents Challenges for Credibility in Trendy Machine Studying”, to be printed within the Journal of Machine Studying Analysis, we present {that a} key failure mode particularly prevalent in trendy ML programs is underspecification. The thought behind underspecification is that whereas ML fashions are validated on held-out knowledge, this validation is commonly inadequate to ensure that the fashions can have well-defined conduct when they’re utilized in a brand new setting. We present that underspecification seems in all kinds of sensible ML programs and recommend some methods for mitigation.
Underspecification
ML programs have been profitable largely as a result of they incorporate validation of the mannequin on held-out knowledge to make sure excessive efficiency. Nonetheless, for a hard and fast dataset and mannequin structure, there are sometimes many distinct ways in which a educated mannequin can obtain excessive validation efficiency. However beneath customary follow, fashions that encode distinct options are sometimes handled as equal as a result of their held-out predictive efficiency is roughly equal.
Importantly, the distinctions between these fashions do develop into clear when they’re measured on standards past customary predictive efficiency, comparable to equity or robustness to irrelevant enter perturbations. For instance, amongst fashions that carry out equally properly on customary validations, some could exhibit larger efficiency disparities between social teams than others, or rely extra closely on irrelevant info. These variations, in flip, can translate to actual variations in conduct when the mannequin is utilized in real-world situations.
Underspecification refers to this hole between the necessities that practitioners typically bear in mind after they construct an ML mannequin, and the necessities which might be truly enforced by the ML pipeline (i.e., the design and implementation of a mannequin). An vital consequence of underspecification is that even when the pipeline might in precept return a mannequin that meets all of those necessities, there isn’t a assure that in follow the mannequin will fulfill any requirement past correct prediction on held-out knowledge. Actually, the mannequin that’s returned could have properties that as a substitute rely on arbitrary or opaque selections made within the implementation of the ML pipeline, comparable to these arising from random initialization seeds, knowledge ordering, {hardware}, and so forth. Thus, ML pipelines that don’t embody express defects should still return fashions that behave unexpectedly in real-world settings.
Figuring out Underspecification in Actual Functions
On this work, we investigated concrete implications of underspecification within the sorts of ML fashions which might be utilized in real-world functions. Our empirical technique was to assemble units of fashions utilizing practically an identical ML pipelines, to which we solely utilized small adjustments that had no sensible impact on customary validation efficiency. Right here, we centered on the random seed used to initialize coaching and decide knowledge ordering. If vital properties of the mannequin may be considerably influenced by these adjustments, it signifies that the pipeline doesn’t absolutely specify this real-world conduct. In each area the place we carried out this experiment, we discovered that these small adjustments induced substantial variation on axes that matter in real-world use.
Underspecification in Pc Imaginative and prescient
For instance, think about underspecification and its relationship to robustness in pc imaginative and prescient. A central problem in pc imaginative and prescient is that deep fashions typically undergo from brittleness beneath distribution shifts that people don’t discover difficult. As an illustration, picture classification fashions that carry out properly on the ImageNet benchmark are identified to carry out poorly on benchmarks like ImageNet-C, which apply frequent picture corruptions, comparable to pixelization or movement blur, to the usual ImageNet check set.
In our experiment, we confirmed that mannequin sensitivity to those corruptions is underspecified by customary pipelines. Following the technique mentioned above, we generated fifty ResNet-50 picture classification fashions utilizing the identical pipeline and the identical knowledge. The one distinction between these fashions was the random seed utilized in coaching. When evaluated on the usual ImageNet validation set, these fashions achieved virtually equal efficiency. Nonetheless, when the fashions had been evaluated on totally different check units within the ImageNet-C benchmark (i.e., on corrupted knowledge), efficiency on some assessments assorted by orders of magnitude greater than on customary validations. This sample continued for larger-scale fashions that had been pre-trained on a lot bigger datasets (e.g., a BiT-L mannequin pre-trained on the 300 million picture JFT-300M dataset). For these fashions, various the random seed on the fine-tuning stage of coaching produced an analogous sample of variations.
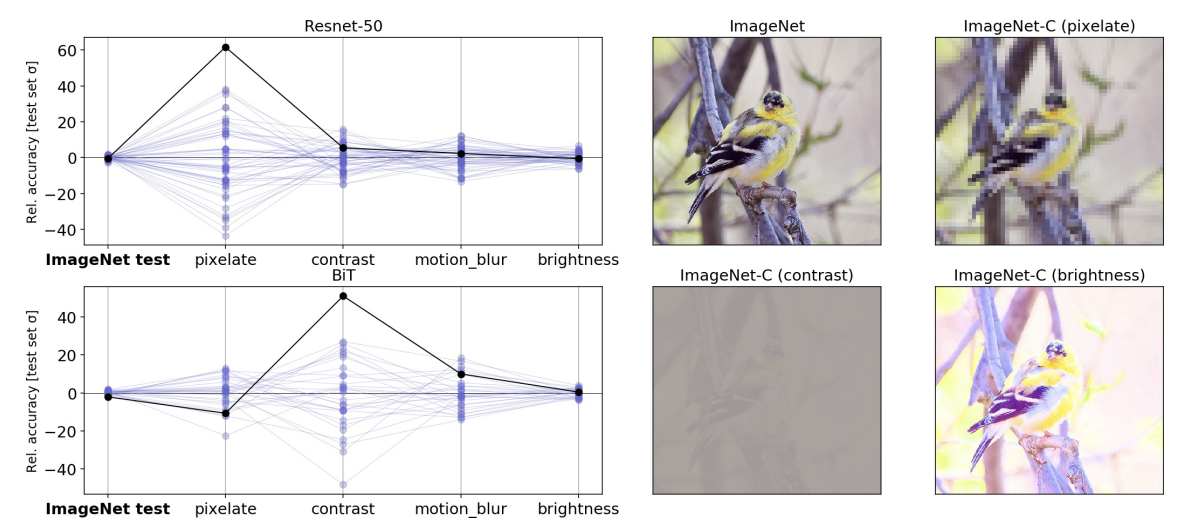 |
| Left: Parallel axis plots exhibiting the variation in accuracy between an identical, randomly initialized ResNet-50 fashions on strongly corrupted ImageNet-C knowledge. Strains signify the efficiency of every mannequin within the ensemble on classification duties utilizing uncorrupted check knowledge, in addition to corrupted knowledge (pixelation, distinction, movement blur, and brightness). Given values are the deviation in accuracy from the ensemble imply, scaled by the usual deviation of accuracies on the “clear” ImageNet check set. The strong black line highlights the efficiency of an arbitrarily chosen mannequin to indicate how efficiency on one check is probably not a very good indication of efficiency on others. Proper: Instance pictures from the usual ImageNet check set, with corrupted variations from the ImageNet-C benchmark. |
We additionally confirmed that underspecification can have sensible implications in special-purpose pc imaginative and prescient fashions constructed for medical imaging, the place deep studying fashions have proven nice promise. We thought-about two analysis pipelines supposed as precursors for medical functions: one ophthalmology pipeline for constructing fashions that detect diabetic retinopathy and referable diabetic macular edema from retinal fundus pictures, and one dermatology pipeline for constructing fashions to acknowledge frequent dermatological situations from pictures of pores and skin. In our experiments, we thought-about pipelines that had been validated solely on randomly held-out knowledge.
We then stress-tested fashions produced by these pipelines on virtually vital dimensions. For the ophthalmology pipeline, we examined how fashions educated with totally different random seeds carried out when utilized to pictures taken from a brand new digital camera sort not encountered throughout coaching. For the dermatology pipeline, the stress check was comparable, however for sufferers with totally different estimated pores and skin sorts (i.e., non-dermatologist analysis of tone and response to daylight). In each circumstances, we discovered that customary validations weren’t sufficient to completely specify the educated mannequin’s efficiency on these axes. Within the ophthalmology utility, the random seed utilized in coaching induced wider variability in efficiency on a brand new digital camera sort than would have been anticipated from customary validations, and within the dermatology utility, the random seed induced comparable variation in efficiency in skin-type subgroups, although the general efficiency of the fashions was steady throughout seeds.
These outcomes reiterate that customary hold-out testing alone isn’t adequate to make sure acceptable mannequin conduct in medical functions, underscoring the necessity for expanded testing protocols for ML programs supposed for utility within the medical area. Within the medical literature, such validations are termed “exterior validation” and have traditionally been a part of reporting pointers comparable to STARD and TRIPOD. These are being emphasised in updates comparable to STARD-AI and TRIPOD-AI. Lastly, as a part of regulated medical system growth processes (see, e.g., US and EU laws), there are different types of security and efficiency associated issues, comparable to obligatory compliance to requirements for threat administration, human components engineering, scientific validations and accredited physique opinions, that purpose to make sure acceptable medical utility efficiency.
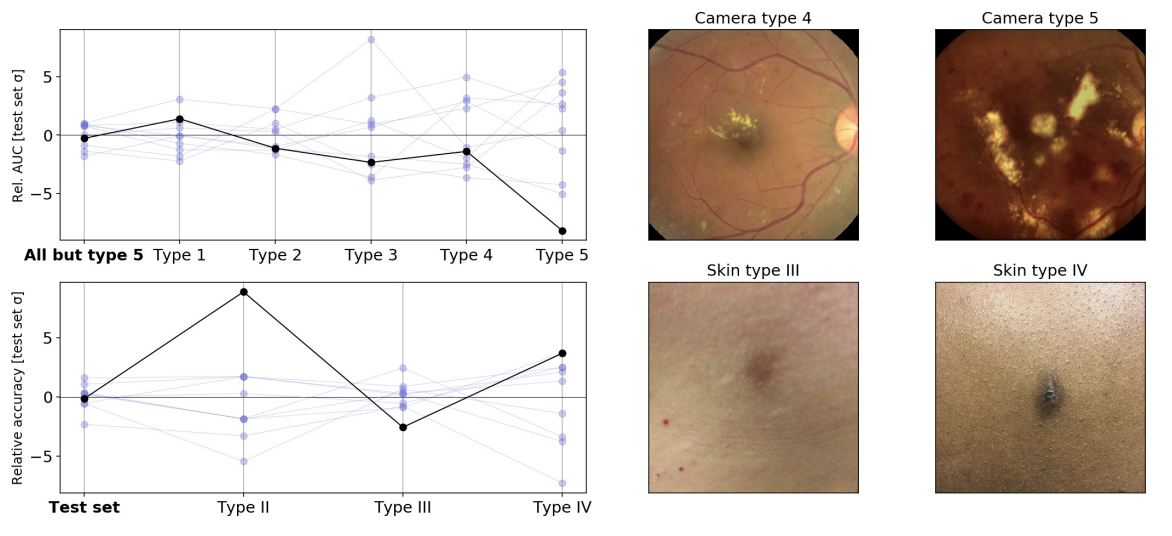 |
| Relative variability of medical imaging fashions on stress assessments, utilizing the identical conventions because the determine above. High left: Variation in AUC between diabetic retinopathy classification fashions educated utilizing totally different random seeds when evaluated on pictures from totally different digital camera sorts. On this experiment, digital camera sort 5 was not encountered throughout coaching. Backside left: Variation in accuracy between pores and skin situation classification fashions educated utilizing totally different random seeds when evaluated on totally different estimated pores and skin sorts (approximated by dermatologist-trained laypersons from retrospective pictures and probably topic to labeling errors). Proper: instance pictures from the unique check set (left) and the stress check set (proper). |
Underspecification in Different Functions
The circumstances mentioned above are a small subset of fashions that we probed for underspecification. Different circumstances we examined embody:
- Pure Language Processing: We confirmed that on a wide range of NLP duties, underspecification affected how fashions derived from BERT-processed sentences. For instance, relying on the random seed, a pipeline might produce a mannequin that relies upon kind of on correlations involving gender (e.g., between gender and occupation) when making predictions.
- Acute Kidney Harm (AKI) prediction: We confirmed that underspecification impacts reliance on operational versus physiological indicators in AKI prediction fashions based mostly on digital well being information.
- Polygenic Threat Scores (PRS): We confirmed that underspecification influences the flexibility for (PRS) fashions, which predict scientific outcomes based mostly on affected person genomic knowledge, to generalize throughout totally different affected person populations.
In every case, we confirmed that these vital properties are left ill-defined by customary coaching pipelines, making them delicate to seemingly innocuous selections.
Conclusion
Addressing underspecification is a difficult downside. It requires full specification and testing of necessities for a mannequin past customary predictive efficiency. Doing this properly wants full engagement with the context through which the mannequin might be used, an understanding of how the coaching knowledge had been collected, and sometimes, incorporation of area experience when the out there knowledge fall quick. These facets of ML system design are sometimes underemphasized in ML analysis as we speak. A key objective of this work is to indicate how underinvestment on this space can manifest concretely, and to encourage the event of processes for fuller specification and testing of ML pipelines.
Some vital first steps on this space are to specify stress testing protocols for any utilized ML pipeline that’s meant to see real-world use. As soon as these standards are codified in measurable metrics, quite a few totally different algorithmic methods could also be helpful for enhancing them, together with knowledge augmentation, pretraining, and incorporation of causal construction. It needs to be famous, nonetheless, that ultimate stress testing and enchancment processes will often require iteration: each the necessities for ML programs, and the world through which they’re used, are continuously altering.
Acknowledgements
We wish to thank all of our co-authors, Dr. Nenad Tomasev (DeepMind), Prof. Finale Doshi-Velez (Harvard SEAS), UK Biobank, and our companions, EyePACS, Aravind Eye Hospital and Sankara Nethralaya.
[ad_2]