
{kind=link}
[ad_1]
Regardless of the success and widespread adoption of smartphones, utilizing them to compose longer items of textual content remains to be fairly cumbersome. As one writes, grammatical errors can typically creep into the textual content (particularly undesirable in formal conditions), and correcting these errors could be time consuming on a small show with restricted controls.
To handle a few of these challenges, we’re launching a grammar correction function that’s immediately constructed into Gboard on Pixel 6 that works totally on-device to protect privateness, detecting and suggesting corrections for grammatical errors whereas the person is typing. Constructing such performance required addressing just a few key obstacles: reminiscence measurement limitations, latency necessities, and dealing with partial sentences. At the moment, the function is able to correcting English sentences (we plan to broaden to extra languages within the close to future) and obtainable on nearly any app with Gboard1.
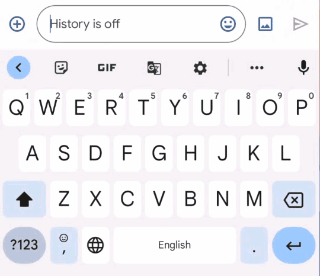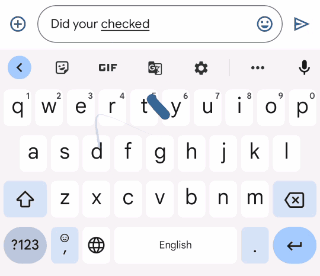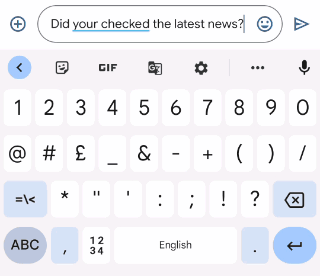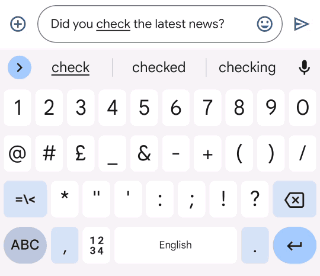 |
| Gboard suggests how you can appropriate an ungrammatical sentence because the person varieties. |
Mannequin Structure
We educated a sequence-to-sequence neural community to take an enter sentence (or a sentence prefix) and output the grammatically appropriate model — if the unique textual content is already grammatically appropriate, the output of the mannequin is similar to its enter, indicating that no corrections are wanted. The mannequin makes use of a hybrid structure that mixes a Transformer encoder with an LSTM decoder, a mixture that gives a great stability of high quality and latency.
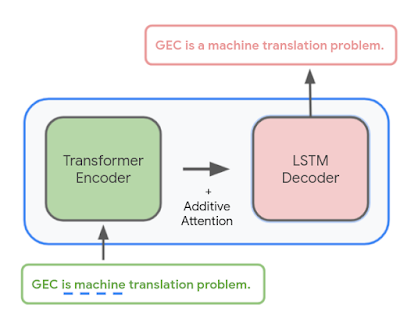 |
| Overview of the grammatical error correction (GEC) mannequin structure. |
Cell gadgets are constrained by restricted reminiscence and computational energy, which make it harder to construct a top quality grammar checking system. There are just a few methods we use to construct a small, environment friendly, and succesful mannequin.
- Shared embedding: As a result of the enter and output of the mannequin are structurally comparable (e.g., each are textual content in the identical language), we share among the mannequin weights between the Transformer encoder and the LSTM decoder, which reduces the mannequin file measurement significantly with out unduly affecting accuracy.
- Factorized embedding: The mannequin splits a sentence right into a sequence of predefined tokens. To realize good high quality, we discover that you will need to use a big vocabulary of predefined tokens, nonetheless, this considerably will increase the mannequin measurement. A factorized embedding separates the scale of the hidden layers from the scale of the vocabulary embedding. This allows us to have a mannequin with a big vocabulary with out considerably growing the variety of complete weights.
- Quantization: To cut back the mannequin measurement additional, we carry out post-training quantization, which permits us to retailer every 32-bit floating level weight utilizing solely 8-bits. Whereas which means every weight is saved with decrease constancy, however, we discover that the standard of the mannequin shouldn’t be materially affected.
By using these methods, the ensuing mannequin takes up solely 20MB of storage and performs inference on 60 enter characters beneath 22ms on the Google Pixel 6 CPU.
Coaching the Mannequin
As a way to prepare the mannequin, we wanted coaching information within the type of <unique, corrected> textual content pairs.
One doable strategy to producing a small on-device mannequin can be to make use of the identical coaching information as a big cloud-based grammar mannequin. Whereas this information produces a fairly top quality on-device mannequin, we discovered that utilizing a method referred to as arduous distillation to generate coaching information that’s better-matched to the on-device area yields even higher high quality outcomes.
Exhausting distillation works as follows: We first collected lots of of thousands and thousands of English sentences from throughout the general public net. We then used the massive cloud-based grammar mannequin to generate grammar corrections for these sentences. This coaching dataset of <unique, corrected> sentence pairs is then used to coach a smaller on-device mannequin that may appropriate full sentences. We discovered that the on-device mannequin constructed from this coaching dataset produces considerably larger high quality options than a similar-sized on-device mannequin constructed on the unique information used to coach the cloud-based mannequin.
Earlier than coaching the mannequin from this information, nonetheless, there may be one other challenge to handle. To allow the mannequin to appropriate grammar because the person varieties (an essential functionality of cell gadgets) it wants to have the ability to deal with sentence prefixes. Whereas this allows grammar correction when the person has solely typed a part of a sentence, this functionality is especially helpful in messaging apps, the place the person typically omits the ultimate interval in a sentence and presses the ship button as quickly as they end typing. If grammar correction is barely triggered on full sentences, it’d miss many errors.
This raises the query of how you can resolve whether or not a given sentence prefix is grammatically appropriate. We used a heuristic to resolve this — if a given sentence prefix could be accomplished to type a grammatically appropriate sentence, we then think about it grammatically appropriate. If not, it’s assumed to be incorrect.
| What the person has typed up to now | Recommended grammar correction | |
| She places rather a lot | ||
| She places plenty of | ||
| She places plenty of effort | ||
| She places plenty of effort yesterday | Substitute “places” with “put in”. |
| GEC on incomplete sentences. There is no such thing as a correction for legitimate sentence prefixes. |
We created a second dataset appropriate for coaching a big cloud-based mannequin, however this time specializing in sentence prefixes. We generated the information utilizing the aforementioned heuristic by taking the <unique, corrected> sentence pairs from the cloud-based mannequin’s coaching dataset and randomly sampling aligned prefixes from them.
For instance, given the <unique, corrected> sentence pair:
Authentic sentence: She places plenty of effort yesterday afternoon.
Corrected sentence: She put in plenty of effort yesterday afternoon.
We would pattern the next prefix pairs:
Authentic prefix: She places
Corrected prefix: She put in
Authentic prefix: She places plenty of effort yesterday
Corrected prefix: She put in plenty of effort yesterday
We then autocompleted every unique prefix to a full sentence utilizing a neural language mannequin (comparable in spirit to that utilized by SmartCompose). If a full-sentence grammar mannequin finds no errors within the full sentence, then which means there may be no less than one doable solution to full this unique prefix with out making any grammatical errors, so we think about the unique prefix to be appropriate and output <unique prefix, unique prefix> as a coaching instance. In any other case, we output <unique prefix, corrected prefix>. We used this coaching information to coach a big cloud-based mannequin that may appropriate sentence prefixes, then used that mannequin for arduous distillation, producing new <unique, corrected> sentence prefix pairs which can be better-matched to the on-device area.
Lastly, we constructed the ultimate coaching information for the on-device mannequin by combining these new sentence prefix pairs with the total sentence pairs. The on-device mannequin educated on this mixed information is then able to correcting each full sentences in addition to sentence prefixes.
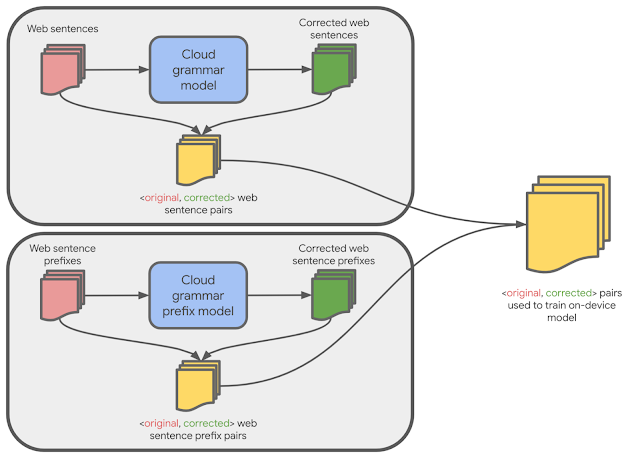 |
| Coaching information for the on-device mannequin is generated from cloud-based fashions. |
Grammar Correction On-Gadget
Gboard sends a request to the on-device grammar mannequin every time the person has typed greater than three phrases, whether or not the sentence is accomplished or not. To supply a top quality person expertise, we underline the grammar errors and supply alternative options when the person interacts with them. Nevertheless, the mannequin outputs solely corrected sentences, so these should be reworked into alternative options. To do that, we align the unique sentence and the corrected sentence by minimizing the Levenshtein distance (i.e., the variety of edits which can be wanted to remodel the unique sentence to the corrected sentence).
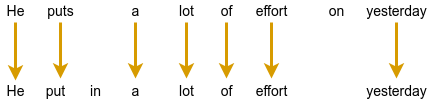 |
| Extracting edits by aligning the corrected sentence to the unique sentence. |
Lastly, we remodel the insertion edits and deletion edits to be alternative edits. Within the above instance, we remodel the advised insertion of “in” to be an edit that means changing “places” with “put in”. And we equally counsel changing “effort on” with “effort”.
Conclusion
We’ve got constructed a small high-quality grammar correction mannequin by designing a compact mannequin structure and leveraging a cloud-based grammar system throughout coaching by way of arduous distillation. This compact mannequin allows customers to appropriate their textual content totally on their very own gadget with out ever needing to ship their keystrokes to a distant server.
Acknowledgements
We gratefully acknowledge the important thing contributions of the opposite crew members, together with Abhanshu Sharma, Akshay Kannan, Bharath Mankalale, Chenxi Ni, Felix Stahlberg, Florian Hartmann, Jacek Jurewicz, Jayakumar Hoskere, Jenny Chin, Kohsuke Yatoh, Lukas Zilka, Martin Sundermeyer, Matt Sharifi, Max Gubin, Nick Pezzotti, Nithi Gupta, Olivia Graham, Qi Wang, Sam Jaffee, Sebastian Millius, Shankar Kumar, Sina Hassani, Vishal Kumawat, and Yuanbo Zhang, Yunpeng Li, Yuxin Dai. We might additionally wish to thank Xu Liu and David Petrou for his or her help.
1The function will finally be obtainable in all apps with Gboard, however is presently unavailable for these in WebView. ↩
[ad_2]