
{kind=link}
[ad_1]
Over the past a number of years, progress has been made on privacy-safe approaches for dealing with delicate information, for instance, whereas discovering insights into human mobility and thru use of federated analytics equivalent to RAPPOR. In 2019, we launched an open supply library to allow builders and organizations to make use of strategies that present differential privateness, a powerful and extensively accepted mathematical notion of privateness. Differentially-private information evaluation is a principled method that permits organizations to be taught and launch insights from the majority of their information whereas concurrently offering a mathematical assure that these outcomes don’t permit any particular person person’s information to be distinguished or re-identified.
On this publish, we contemplate the next primary drawback: Given a database containing a number of attributes about customers, how can one create significant person teams and perceive their traits? Importantly, if the database at hand incorporates delicate person attributes, how can one reveal these group traits with out compromising the privateness of particular person customers?
Such a process falls below the broad umbrella of clustering, a basic constructing block in unsupervised machine studying. A clustering technique partitions the information factors into teams and gives a strategy to assign any new information level to a bunch with which it’s most related. The k-means clustering algorithm has been one such influential clustering technique. Nonetheless, when working with delicate datasets, it will probably doubtlessly reveal important details about particular person information factors, placing the privateness of the corresponding person in danger.
At present, we announce the addition of a brand new differentially personal clustering algorithm to our differential privateness library, which relies on privately producing new consultant information factors. We consider its efficiency on a number of datasets and examine to present baselines, discovering aggressive or higher efficiency.
Ok-means Clustering
Given a set of information factors, the aim of k-means clustering is to determine (at most) ok factors, known as cluster facilities, in order to reduce the loss given by the sum of squared distances of the information factors from their closest cluster middle. This partitions the set of information factors into ok teams. Furthermore, any new information level will be assigned to a bunch based mostly on its closest cluster middle. Nonetheless, releasing the set of cluster facilities has the potential to leak details about specific customers — for instance, contemplate a situation the place a specific information level is considerably removed from the remainder of the factors, so the usual k-means clustering algorithm returns a cluster middle at this single level, thereby revealing delicate details about this single level. To deal with this, we design a brand new algorithm for clustering with the k-means goal throughout the framework of differential privateness.
A Differentially Personal Algorithm
In “Domestically Personal k-Means in One Spherical”, revealed at ICML 2021, we introduced a differentially personal algorithm for clustering information factors. That algorithm had the benefit of being personal within the native mannequin, the place the person’s privateness is protected even from the central server performing the clustering. Nonetheless, any such method essentially incurs a considerably bigger loss than approaches utilizing fashions of privateness that require trusting a central server.1
Right here, we current a equally impressed clustering algorithm that works within the central mannequin of differential privateness, the place the central server is trusted to have full entry to the uncooked information, and the aim is to compute differentially personal cluster facilities, which don’t leak details about particular person information factors. The central mannequin is the usual mannequin for differential privateness, and algorithms within the central mannequin will be extra simply substituted instead of their non-private counterparts since they don’t require modifications to the information assortment course of. The algorithm proceeds by first producing, in a differentially personal method, a core-set that consists of weighted factors that “signify” the information factors effectively. That is adopted by executing any (non-private) clustering algorithm (e.g., k-means++) on this privately generated core-set.
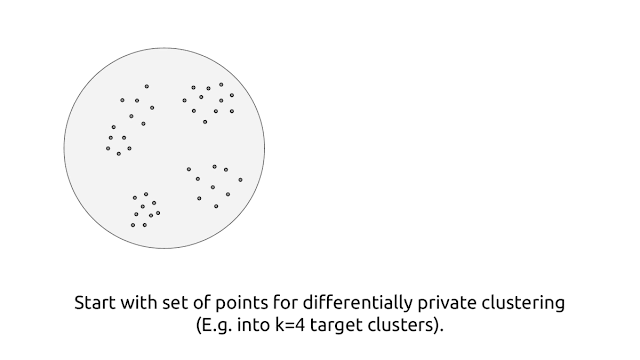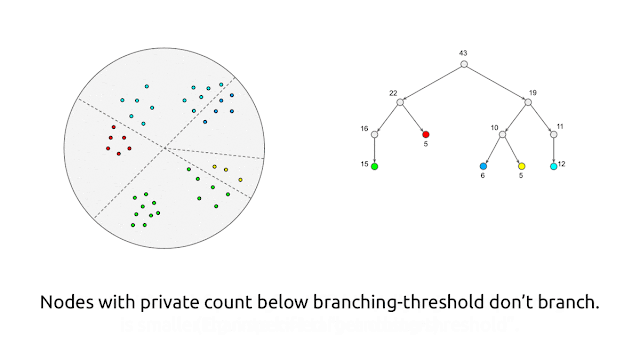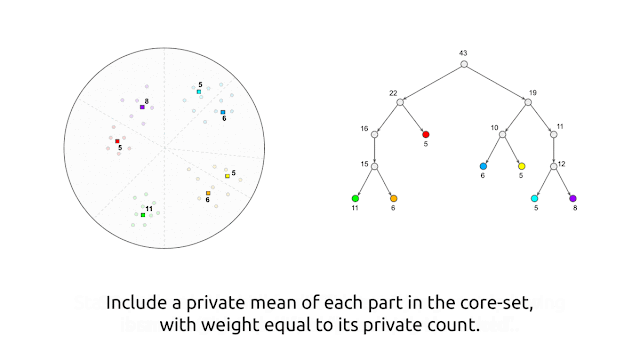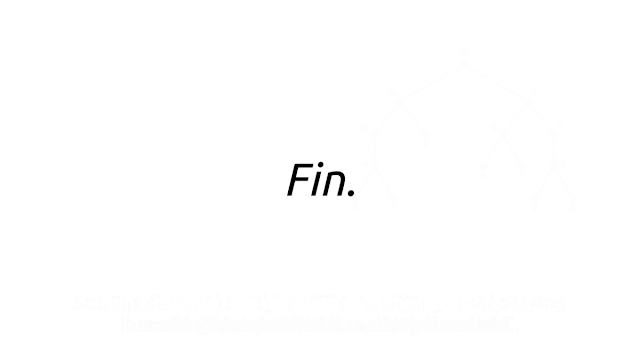
At a excessive degree, the algorithm generates the personal core-set by first utilizing random-projection–based mostly locality-sensitive hashing (LSH) in a recursive method2 to partition the factors into “buckets” of comparable factors, after which changing every bucket by a single weighted level that’s the common of the factors within the bucket, with a weight equal to the variety of factors in the identical bucket. As described thus far, although, this algorithm isn’t personal. We make it personal by performing every operation in a personal method by including noise to each the counts and averages of factors inside a bucket.
This algorithm satisfies differential privateness as a result of every level’s contributions to the bucket counts and the bucket averages are masked by the added noise, so the habits of the algorithm doesn’t reveal details about any particular person level. There’s a tradeoff with this method: if the variety of factors within the buckets is simply too massive, then particular person factors won’t be well-represented by factors within the core-set, whereas if the variety of factors in a bucket is simply too small, then the added noise (to the counts and averages) will change into important compared to the precise values, resulting in poor high quality of the core-set. This trade-off is realized with user-provided parameters within the algorithm that management the variety of factors that may be in a bucket.
 |
| Visible illustration of the algorithm. |
Experimental Analysis
We evaluated the algorithm on a couple of benchmark datasets, evaluating its efficiency to that of the (non-private) k-means++ algorithm, in addition to a couple of different algorithms with out there implementations, specifically diffprivlib and dp-clustering-icml17. We use the next benchmark datasets: (i) an artificial dataset consisting of 100,000 information factors in 100 dimensions sampled from a combination of 64 Gaussians; (ii) neural representations for the MNIST dataset on handwritten digits obtained by coaching a LeNet mannequin; (iii) the UC Irvine dataset on Letter Recognition; and (iv) the UC Irvine dataset on Gasoline Turbine CO and NOx Emissions.3
We analyze the normalized k-means loss (imply squared distance from information factors to the closest middle) whereas various the variety of goal facilities (ok) for these benchmark datasets.4 The described algorithm achieves a decrease loss than the opposite personal algorithms in three out of the 4 datasets we contemplate.
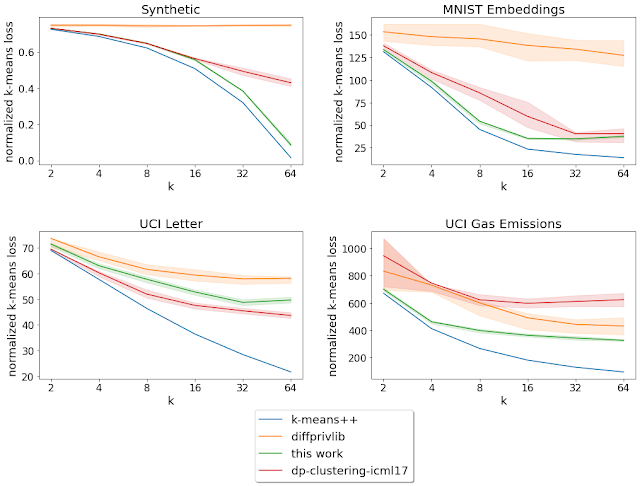 |
| Normalized loss for various ok = variety of goal clusters (decrease is best). The strong curves denote the imply over the 20 runs, and the shaded area denotes the 25-75th percentile vary. |
Furthermore, for datasets with specified ground-truth labels (i.e., recognized groupings), we analyze the cluster label accuracy, which is the accuracy of the labeling obtained by assigning essentially the most frequent ground-truth label in every cluster discovered by the clustering algorithm to all factors in that cluster. Right here, the described algorithm performs higher than different personal algorithms for all of the datasets with pre-specified ground-truth labels that we contemplate.
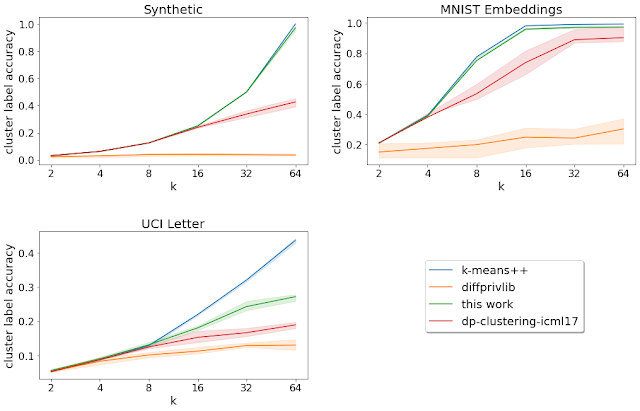 |
| Cluster label accuracy for various ok = variety of goal clusters (larger is best). The strong curves denote the imply over the 20 runs, and the shaded area denotes the 25-75th percentile vary. |
Limitations and Future Instructions
There are a few limitations to contemplate when utilizing this or every other library for personal clustering.
- It is very important individually account for the privateness loss in any preprocessing (e.g., centering the information factors or rescaling the totally different coordinates) performed earlier than utilizing the personal clustering algorithm. So, we hope to supply help for differentially personal variations of generally used preprocessing strategies sooner or later and examine modifications in order that the algorithm performs higher with information that isn’t essentially preprocessed.
- The algorithm described requires a user-provided radius, such that each one information factors lie inside a sphere of that radius. That is used to find out the quantity of noise that’s added to the bucket averages. Observe that this differs from diffprivlib and dp-clustering-icml17 which soak up totally different notions of bounds of the dataset (e.g., a minimal and most of every coordinate). For the sake of our experimental analysis, we calculated the related bounds non-privately for every dataset. Nonetheless, when working the algorithms in follow, these bounds ought to usually be privately computed or offered with out data of the dataset (e.g., utilizing the underlying vary of the information). Though, word that in case of the algorithm described, the offered radius needn’t be precisely appropriate; any information factors exterior of the offered radius are changed with the closest factors which are throughout the sphere of that radius.
Conclusion
This work proposes a brand new algorithm for computing consultant factors (cluster facilities) throughout the framework of differential privateness. With the rise within the quantity of datasets collected world wide, we hope that our open supply software will assist organizations acquire and share significant insights about their datasets, with the mathematical assurance of differential privateness.
Acknowledgements
We thank Christoph Dibak, Badih Ghazi, Miguel Guevara, Sasha Kulankhina, Ravi Kumar, Pasin Manurangsi, Jane Shapiro, Daniel Simmons-Marengo, Yurii Sushko, and Mirac Vuslat Basaran for his or her assist.
1As proven by Uri Stemmer in Domestically personal k-means clustering (SODA 2020). ↩
2That is just like work on LSH Forest, used within the context of similarity-search queries. ↩
3Datasets (iii) and (iv) have been centered to have imply zero earlier than evaluating the algorithms. ↩
4Analysis performed for mounted privateness parameters ε = 1.0 and δ = 1e-6. Observe that dp-clustering-icml17 works within the pure differential privateness mannequin (specifically, with δ = 0); k-means++, after all, has no privateness parameters. ↩
[ad_2]