
{kind=link}
[ad_1]
Video is an ubiquitous supply of media content material that touches on many points of individuals’s day-to-day lives. More and more, real-world video purposes, similar to video captioning, video content material evaluation, and video question-answering (VideoQA), depend on fashions that may join video content material with textual content or pure language. VideoQA is especially difficult, nonetheless, because it requires greedy each semantic data, similar to objects in a scene, in addition to temporal data, e.g., how issues transfer and work together, each of which have to be taken within the context of a natural-language query that holds particular intent. As well as, as a result of movies have many frames, processing all of them to study spatio-temporal data could be computationally costly. Nonetheless, understanding all this data allows fashions to reply complicated questions — for instance, within the video beneath, a query in regards to the second ingredient poured within the bowl requires figuring out objects (the elements), actions (pouring), and temporal ordering (second).
 |
| An instance enter query for the VideoQA job “What’s the second ingredient poured into the bowl?” which requires deeper understanding of each the visible and textual content inputs. The video is an instance from the 50 Salads dataset, used underneath the Artistic Commons license. |
To handle this, in “Video Query Answering with Iterative Video-Textual content Co-Tokenization”, we introduce a brand new strategy to video-text studying known as iterative co-tokenization, which is ready to effectively fuse spatial, temporal and language data for VideoQA. This strategy is multi-stream, processing completely different scale movies with unbiased spine fashions for every to supply video representations that seize completely different options, e.g., these of excessive spatial decision or lengthy temporal durations. The mannequin then applies the co-tokenization module to study environment friendly representations from fusing the video streams with the textual content. This mannequin is very environment friendly, utilizing solely 67 giga-FLOPs (GFLOPs), which is not less than 50% fewer than earlier approaches, whereas giving higher efficiency than different state-of-the-art fashions.
Video-Textual content Iterative Co-tokenization
The primary objective of the mannequin is to supply options from each movies and textual content (i.e., the person query), collectively permitting their corresponding inputs to work together. A second objective is to take action in an environment friendly method, which is very vital for movies since they include tens to a whole bunch of frames as enter.
The mannequin learns to tokenize the joint video-language inputs right into a smaller set of tokens that collectively and effectively symbolize each modalities. When tokenizing, we use each modalities to supply a joint compact illustration, which is fed to a transformer layer to supply the subsequent degree illustration. A problem right here, which can be typical in cross-modal studying, is that always the video body doesn’t correspond on to the related textual content. We handle this by including two learnable linear layers which unify the visible and textual content function dimensions earlier than tokenization. This manner we allow each video and textual content to situation how video tokens are realized.
Furthermore, a single tokenization step doesn’t enable for additional interplay between the 2 modalities. For that, we use this new function illustration to work together with the video enter options and produce one other set of tokenized options, that are then fed into the subsequent transformer layer. This iterative course of permits the creation of recent options, or tokens, which symbolize a continuous refinement of the joint illustration from each modalities. On the final step the options are enter to a decoder that generates the textual content output.
As usually carried out for VideoQA, we pre-train the mannequin earlier than fine-tuning it on the person VideoQA datasets. On this work we use the movies routinely annotated with textual content based mostly on speech recognition, utilizing the HowTo100M dataset as an alternative of pre-training on a big VideoQA dataset. This weaker pre-training information nonetheless allows our mannequin to study video-text options.
 |
| Visualization of the video-text iterative co-tokenization strategy. Multi-stream video inputs, that are variations of the identical video enter (e.g., a excessive decision, low frame-rate video and a low decision, excessive frame-rate video), are effectively fused along with the textual content enter to supply a text-based reply by the decoder. As an alternative of processing the inputs immediately, the video-text iterative co-tokenization mannequin learns a diminished variety of helpful tokens from the fused video-language inputs. This course of is completed iteratively, permitting the present function tokenization to have an effect on the number of tokens on the subsequent iteration, thus refining the choice. |
Environment friendly Video Query-Answering
We apply the video-language iterative co-tokenization algorithm to 3 major VideoQA benchmarks, MSRVTT-QA, MSVD-QA and IVQA, and show that this strategy achieves higher outcomes than different state-of-the-art fashions, whereas having a modest measurement. Moreover, iterative co-tokenization studying yields vital compute financial savings for video-text studying duties. The strategy makes use of solely 67 giga-FLOPs (GFLOPS), which is one sixth the 360 GFLOPS wanted when utilizing the favored 3D-ResNet video mannequin collectively with textual content and is greater than twice as environment friendly because the X3D mannequin. That is all of the whereas producing extremely correct outcomes, outperforming state-of-the-art strategies.
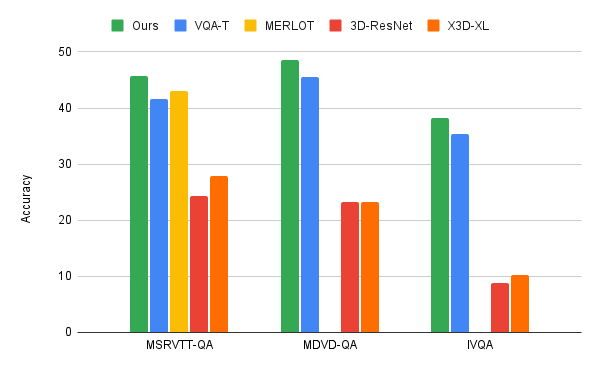 |
| Comparability of our iterative co-tokenization strategy to earlier strategies similar to MERLOT and VQA-T, in addition to, baselines utilizing single ResNet-3D or X3D-XL. |
Multi-stream Video Inputs
For VideoQA, or any of plenty of different duties that contain video inputs, we discover that multi-stream enter is vital to extra precisely reply questions on each spatial and temporal relationships. Our strategy makes use of three video streams at completely different resolutions and frame-rates: a low-resolution excessive frame-rate, enter video stream (with 32 frames-per-second and spatial decision 64×64, which we denote as 32x64x64); a high-resolution, low frame-rate video (8x224x224); and one in-between (16x112x112). Regardless of the apparently extra voluminous data to course of with three streams, we acquire very environment friendly fashions as a result of iterative co-tokenization strategy. On the similar time these further streams enable extraction of essentially the most pertinent data. For instance, as proven within the determine beneath, questions associated to a selected exercise in time will produce greater activations within the smaller decision however excessive frame-rate video enter, whereas questions associated to the overall exercise could be answered from the excessive decision enter with only a few frames. One other advantage of this algorithm is that the tokenization modifications relying on the questions requested.
 |
| Visualization of the eye maps realized per layer in the course of the video-text co-tokenization. The eye maps differ relying on the query requested for a similar video. For instance, if the query is said to the overall exercise (e.g., browsing within the determine above), then the eye maps of the upper decision low frame-rate inputs are extra energetic and appear to contemplate extra world data. Whereas if the query is extra particular, e.g., asking about what occurs after an occasion, the function maps are extra localized and are typically energetic within the excessive frame-rate video enter. Moreover, we see that the low-resolution, high-frame fee video inputs present extra data associated to actions within the video. |
Conclusion
We current a brand new strategy to video-language studying that focuses on joint studying throughout video-text modalities. We handle the vital and difficult job of video question-answering. Our strategy is each extremely environment friendly and correct, outperforming present state-of-the-art fashions, regardless of being extra environment friendly. Our strategy leads to modest mannequin sizes and may achieve additional enhancements with bigger fashions and information. We hope this work provokes extra analysis in vision-language studying to allow extra seamless interplay with vision-based media.
Acknowledgements
This work is performed by AJ Pierviovanni, Kairo Morton, Weicheng Kuo, Michael Ryoo and Anelia Angelova. We thank our collaborators on this analysis, and Soravit Changpinyo for precious feedback and solutions, and Claire Cui for solutions and help. We additionally thank Tom Small for visualizations.
[ad_2]