
{kind=link}
[ad_1]
Many machine studying (ML) fashions usually concentrate on studying one job at a time. For instance, language fashions predict the likelihood of a subsequent phrase given a context of previous phrases, and object detection fashions establish the item(s) which can be current in a picture. Nonetheless, there could also be cases when studying from many associated duties on the identical time would result in higher modeling efficiency. That is addressed within the area of multi-task studying, a subfield of ML by which a number of targets are skilled throughout the identical mannequin on the identical time.
Take into account a real-world instance: the sport of ping-pong. When taking part in ping-pong, it’s typically advantageous to guage the space, spin, and imminent trajectory of the ping-pong ball to regulate your physique and line up a swing. Whereas every of those duties are distinctive — predicting the spin of a ping-pong ball is essentially distinct from predicting its location — bettering your reasoning of the placement and spin of the ball will seemingly enable you higher predict its trajectory and vice-versa. By analogy, throughout the realm of deep studying, coaching a mannequin to foretell three associated duties (i.e., the placement, spin, and trajectory of a ping-pong ball) might lead to improved efficiency over a mannequin that solely predicts a single goal.
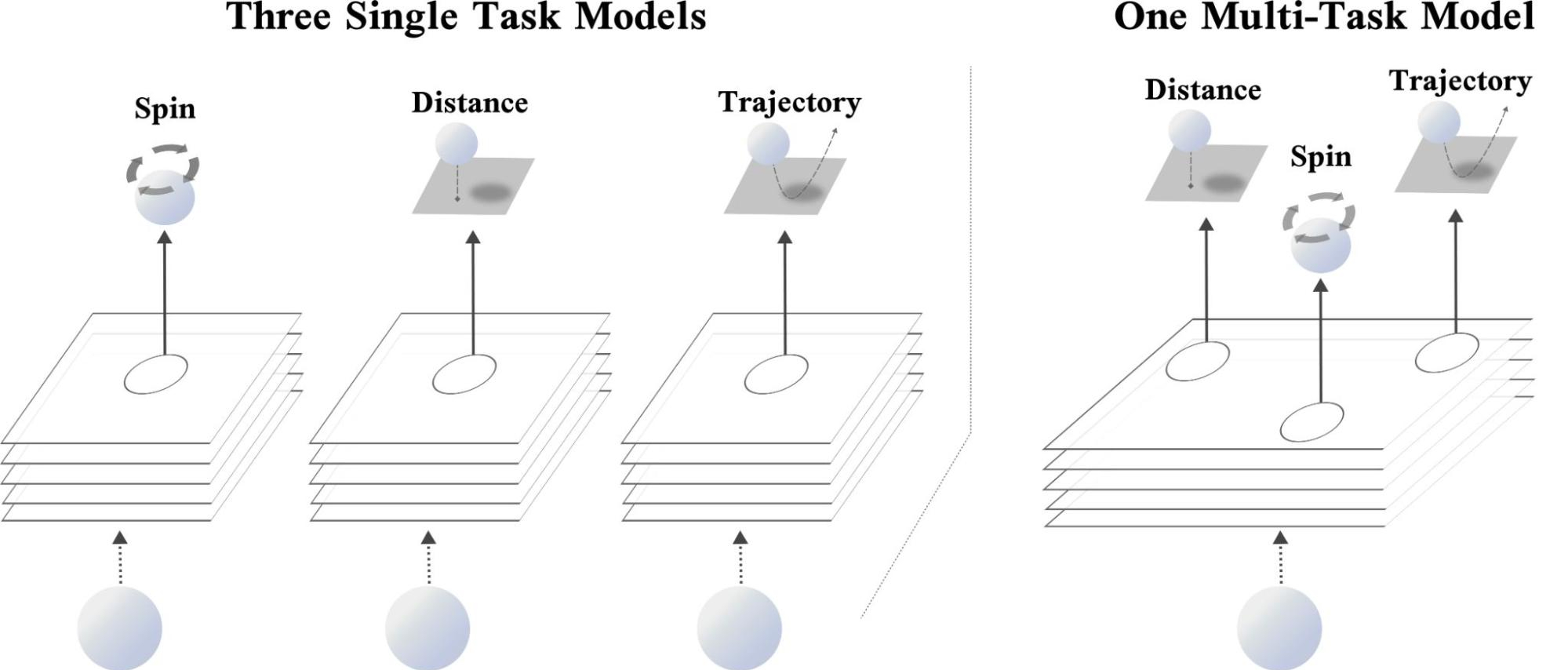 |
| Left: Three single-task networks, every of which makes use of the identical enter to foretell the spin, distance, or trajectory of the ping-pong ball, respectively. Proper: A single multi-task community that concurrently predicts the spin, distance, and trajectory. |
In “Effectively Figuring out Activity Groupings in Multi-Activity Studying”, a highlight presentation at NeurIPS 2021, we describe a way referred to as Activity Affinity Groupings (TAG) that determines which duties must be skilled collectively in multi-task neural networks. Our method makes an attempt to divide a set of duties into smaller subsets such that the efficiency throughout all duties is maximized. To perform this purpose, it trains all duties collectively in a single multi-task mannequin and measures the diploma to which one job’s gradient replace on the mannequin’s parameters would have an effect on the lack of the opposite duties within the community. We denote this amount as inter-task affinity. Our experimental findings point out that choosing teams of duties that maximize inter-task affinity correlates strongly with total mannequin efficiency.
Which Duties Ought to Prepare Collectively?
Within the very best case, a multi-task studying mannequin will apply the data it learns throughout coaching on one job to lower the loss on different duties included in coaching the community. This switch of data results in a single mannequin that may not solely make a number of predictions, however may exhibit improved accuracy for these predictions compared with the efficiency of coaching a special mannequin for every job. However, coaching a single mannequin on many duties might result in competitors for mannequin capability and severely degrade efficiency. This latter state of affairs typically happens when duties are unrelated. Returning to our ping-pong analogy, think about attempting to foretell the placement, spin, and trajectory of the ping-pong ball whereas concurrently recounting the Fibonnaci sequence. Not a enjoyable prospect, and almost definitely detrimental to your development as a ping-pong participant.
One direct method to pick the subset of duties on which a mannequin ought to practice is to carry out an exhaustive search over all potential combos of multi-task networks for a set of duties. Nonetheless, the price related to this search may be prohibitive, particularly when there are a lot of duties, as a result of the variety of potential combos will increase exponentially with respect to the variety of duties within the set. That is additional sophisticated by the truth that the set of duties to which a mannequin is utilized might change all through its lifetime. As duties are added to or dropped from the set of all duties, this expensive evaluation would must be repeated to find out new groupings. Furthermore, as the size and complexity of fashions continues to extend, even approximate job grouping algorithms that consider solely a subset of potential multi-task networks might grow to be prohibitively expensive and time-consuming to judge.
Constructing Activity Affinity Groupings
In analyzing this problem, we drew inspiration from meta-learning, a website of machine studying that trains a neural community that may be shortly tailored to a brand new, and beforehand unseen job. One of many basic meta-learning algorithms, MAML, applies a gradient replace to the fashions’ parameters for a group of duties after which updates its authentic set of parameters to reduce the loss for a subset of duties in that assortment computed on the up to date parameter values. Utilizing this methodology, MAML trains the mannequin to be taught representations that won’t decrease the loss for its present set of weights, however relatively for the weights after a number of steps of coaching. Consequently, MAML trains a fashions’ parameters to have the capability to shortly adapt to a beforehand unseen job as a result of it optimizes for the long run, not the current.
TAG employs an identical mechanism to achieve perception into the coaching dynamics of multi-task neural networks. Specifically, it updates the mannequin’s parameters with respect solely to a single job, seems at how this variation would have an effect on the opposite duties within the multi-task neural community, after which undoes this replace. This course of is then repeated for each different job to assemble info on how every job within the community would work together with some other job. Coaching then continues as regular by updating the mannequin’s shared parameters with respect to each job within the community.
Accumulating these statistics, and taking a look at their dynamics all through coaching, reveals that sure duties constantly exhibit useful relationships, whereas some are antagonistic in the direction of one another. A community choice algorithm can leverage this knowledge as a way to group duties collectively that maximize inter-task affinity, topic to a practitioner’s alternative of what number of multi-task networks can be utilized throughout inference.
 |
| Overview of TAG. First, duties are skilled collectively in the identical community whereas computing inter-task affinities. Second, the community choice algorithm finds job groupings that maximize inter-task affinity. Third, the ensuing multi-task networks are skilled and deployed. |
Outcomes
Our experimental findings point out that TAG can choose very sturdy job groupings. On the CelebA and Taskonomy datasets, TAG is aggressive with the prior state-of-the-art, whereas working between 32x and 11.5x sooner, respectively. On the Taskonomy dataset, this speedup interprets to 2,008 fewer Tesla V100 GPU hours to seek out job groupings.
Conclusion
TAG is an environment friendly methodology to find out which duties ought to practice collectively in a single coaching run. The strategy seems at how duties work together by coaching, notably, the impact that updating the mannequin’s parameters when coaching on one job would have on the loss values of the opposite duties within the community. We discover that choosing teams of duties to maximise this rating correlates strongly with mannequin efficiency.
Acknowledgements
We want to thank Ehsan Amid, Zhe Zhao, Tianhe Yu, Rohan Anil, and Chelsea Finn for his or her basic contributions to this work. We additionally acknowledge Tom Small for designing the animation, and Google Analysis as a complete for fostering a collaborative and uplifting analysis setting.
[ad_2]