
{kind=link}
[ad_1]
Deep neural networks (DNNs) present extra correct outcomes as the dimensions and protection of their coaching knowledge will increase. Whereas investing in high-quality and large-scale labeled datasets is one path to mannequin enchancment, one other is leveraging prior information, concisely known as “guidelines” — reasoning heuristics, equations, associative logic, or constraints. Contemplate a standard instance from physics the place a mannequin is given the duty of predicting the subsequent state in a double pendulum system. Whereas the mannequin could be taught to estimate the overall power of the system at a given cut-off date solely from empirical knowledge, it’ll incessantly overestimate the power until additionally offered an equation that displays the recognized bodily constraints, e.g., power conservation. The mannequin fails to seize such well-established bodily guidelines by itself. How may one successfully educate such guidelines in order that DNNs soak up the related information past merely studying from the information?
In “Controlling Neural Networks with Rule Representations”, revealed at NeurIPS 2021, we current Deep Neural Networks with Controllable Rule Representations (DeepCTRL), an strategy used to offer guidelines for a mannequin agnostic to knowledge kind and mannequin structure that may be utilized to any type of rule outlined for inputs and outputs. The important thing benefit of DeepCTRL is that it doesn’t require retraining to adapt the rule power. At inference, the consumer can regulate rule power primarily based on the specified operation level of accuracy. We additionally suggest a novel enter perturbation technique, which helps generalize DeepCTRL to non-differentiable constraints. In real-world domains the place incorporating guidelines is important — reminiscent of physics and healthcare — we display the effectiveness of DeepCTRL in instructing guidelines for deep studying. DeepCTRL ensures that fashions observe guidelines extra intently whereas additionally offering accuracy good points at downstream duties, thus bettering reliability and consumer belief within the educated fashions. Moreover, DeepCTRL allows novel use circumstances, reminiscent of speculation testing of the foundations on knowledge samples and unsupervised adaptation primarily based on shared guidelines between datasets.
The advantages of studying from guidelines are multifaceted:
- Guidelines can present further info for circumstances with minimal knowledge, bettering the check accuracy.
- A significant bottleneck for widespread use of DNNs is the lack of awareness the rationale behind their reasoning and inconsistencies. By minimizing inconsistencies, guidelines can enhance the reliability of and consumer belief in DNNs.
- DNNs are delicate to slight enter modifications which can be human-imperceptible. With guidelines, the affect of those modifications could be minimized because the mannequin search area is additional constrained to cut back underspecification.
Studying Collectively from Guidelines and Duties
The standard strategy to implementing guidelines incorporates them by together with them within the calculation of the loss. There are three limitations of this strategy that we purpose to handle: (i) rule power must be outlined earlier than studying (thus the educated mannequin can’t function flexibly primarily based on how a lot the information satisfies the rule); (ii) rule power isn’t adaptable to focus on knowledge at inference if there’s any mismatch with the coaching setup; and (iii) the rule-based goal must be differentiable with respect to learnable parameters (to allow studying from labeled knowledge).
DeepCTRL modifies canonical coaching by creating rule representations, coupled with knowledge representations, which is the important thing to allow the rule power to be managed at inference time. Throughout coaching, these representations are stochastically concatenated with a management parameter, indicated by α, right into a single illustration. The power of the rule on the output choice could be improved by growing the worth of α. By modifying α at inference, customers can management the conduct of the mannequin to adapt to unseen knowledge.
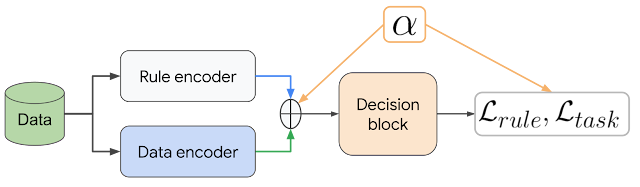 |
| DeepCTRL pairs a knowledge encoder and rule encoder, which produce two latent representations, that are coupled with corresponding aims. The management parameter α is adjustable at inference to manage the relative weight of every encoder. |
Integrating Guidelines by way of Enter Perturbations
Coaching with rule-based aims requires the aims to be differentiable with respect to the learnable parameters of the mannequin. There are a lot of priceless guidelines which can be non-differentiable with respect to enter. For instance, “greater blood strain than 140 is prone to result in heart problems” is a rule that’s onerous to be mixed with standard DNNs. We additionally introduce a novel enter perturbation technique to generalize DeepCTRL to non-differentiable constraints by introducing small perturbations (random noise) to enter options and setting up a rule-based constraint primarily based on whether or not the end result is within the desired course.
Use Instances
We consider DeepCTRL on machine studying use circumstances from physics and healthcare, the place utilization of guidelines is especially essential.
- Improved Reliability Given Identified Rules in Physics
- Adapting to Distribution Shifts in Healthcare
We quantify reliability of a mannequin with the verification ratio, which is the fraction of output samples that fulfill the foundations. Working at a greater verification ratio may very well be useful, particularly if the foundations are recognized to be at all times legitimate, as in pure sciences. By adjusting the management parameter α, the next rule verification ratio, and thus extra dependable predictions, could be achieved.
To display this, we think about the time-series knowledge generated from double pendulum dynamics with friction from a given preliminary state. We outline the duty as predicting the subsequent state of the double pendulum from the present state whereas imposing the rule of power conservation. To quantify how a lot the rule is discovered, we consider the verification ratio.
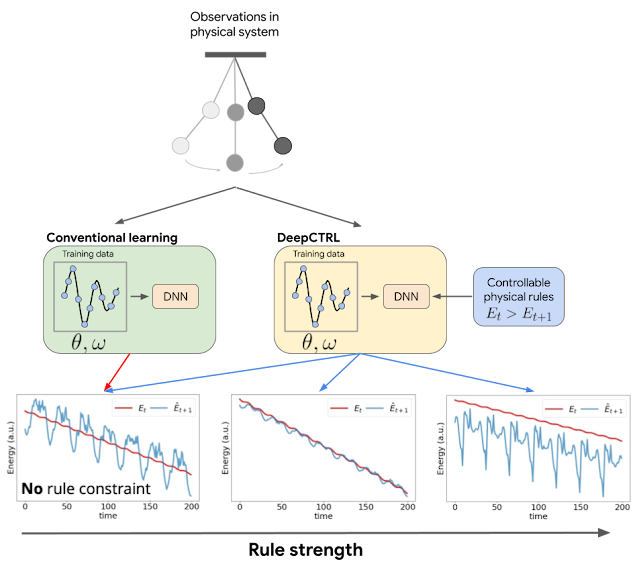 |
| DeepCTRL allows controlling a mannequin’s conduct after studying, however with out retraining. For the instance of a double pendulum, standard studying imposes no constraints to make sure the mannequin follows bodily legal guidelines, e.g., conservation of power. The scenario is analogous for the case of DeepCTRL the place the rule power is low. So, the overall power of the system predicted at time t+1 ( blue) can typically be better than that measured at time t (crimson), which is bodily disallowed (backside left). If rule power in DeepCTRL is excessive, the mannequin could observe the given rule however lose accuracy (discrepancy between crimson and blue is bigger; backside proper). If rule power is between the 2 extremes, the mannequin could obtain greater accuracy (blue curve is near crimson) and observe the rule correctly (blue curve is decrease than crimson one). |
We examine the efficiency of DeepCTRL on this process to standard baselines of coaching with a set rule-based constraint as a regularization time period added to the target, λ. The best of those regularization coefficients gives the best verification ratio (proven by the inexperienced line within the second graph under), nevertheless, the prediction error is barely worse than that of λ = 0.1 (orange line). We discover that the bottom prediction error of the fastened baseline is corresponding to that of DeepCTRL, however the highest verification ratio of the fastened baseline continues to be decrease, which suggests that DeepCTRL may present correct predictions whereas following the regulation of power conservation. As well as, we think about the benchmark of imposing the rule-constraint with Lagrangian Twin Framework (LDF) and display two outcomes the place its hyperparameters are chosen by the bottom imply absolute error (LDF-MAE) and the best rule verification ratio (LDF-Ratio) on the validation set. The efficiency of the LDF technique is very delicate to what the primary constraint is and its output isn’t dependable (black and pink dashed traces).
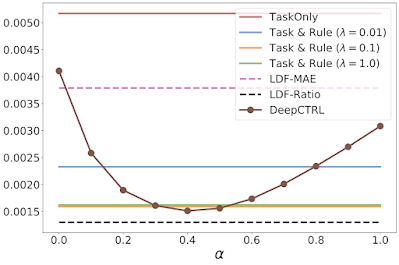 |
| Experimental outcomes for the double pendulum process, displaying the task-based imply absolute error (MAE), which measures the discrepancy between the bottom reality and the mannequin prediction, versus DeepCTRL as a operate of the management parameter α. TaskOnly doesn’t have a rule constraint and Job & Rule has totally different rule power (λ). LDF enforces guidelines by fixing a constraint optimization drawback. |
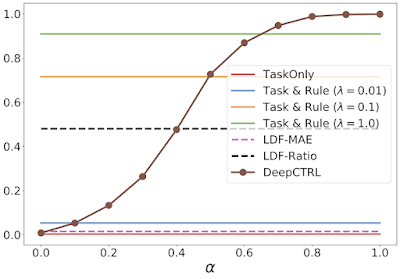 |
| As above, however displaying the verification ratio from totally different fashions. |
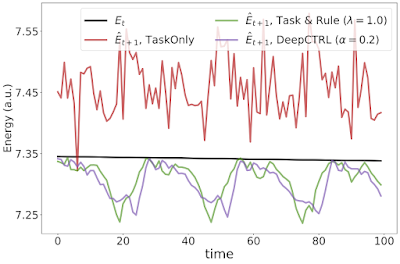 |
| Experimental outcomes for the double pendulum process displaying the present and predicted power at time t and t + 1, respectively. |
Moreover, the figures above illustrate the benefit DeepCTRL has over standard approaches. For instance, growing the rule power λ from 0.1 to 1.0 improves the verification ratio (from 0.7 to 0.9), however doesn’t enhance the imply absolute error. Arbitrarily growing λ will proceed to drive the verification ratio nearer to 1, however will end in worse accuracy. Thus, discovering the optimum worth of λ would require many coaching runs by way of the baseline mannequin, whereas DeepCTRL can discover the optimum worth for the management parameter α rather more rapidly.
The strengths of some guidelines could differ between subsets of the information. For instance, in illness prediction, the correlation between heart problems and better blood strain is stronger for older sufferers than youthful sufferers. In such conditions, when the duty is shared however knowledge distribution and the validity of the rule differ between datasets, DeepCTRL can adapt to the distribution shifts by controlling α.
Exploring this instance, we give attention to the duty of predicting whether or not heart problems is current or not utilizing a heart problems dataset. On condition that greater systolic blood strain is thought to be strongly related to heart problems, we think about the rule: “greater danger if the systolic blood strain is greater”. Primarily based on this, we break up the sufferers into two teams: (1) uncommon, the place a affected person has hypertension, however no illness or decrease blood strain, however has illness; and (2) typical, the place a affected person has hypertension and illness or low blood strain, however no illness.
We display under that the supply knowledge don’t at all times observe the rule, and thus the impact of incorporating the rule can rely on the supply knowledge. The check cross entropy, which signifies classification accuracy (decrease cross entropy is healthier), vs. rule power for supply or goal datasets with various typical / uncommon ratio are visualized under. The error monotonically will increase as α → 1 as a result of the enforcement of the imposed rule, which doesn’t precisely replicate the supply knowledge, turns into extra strict.
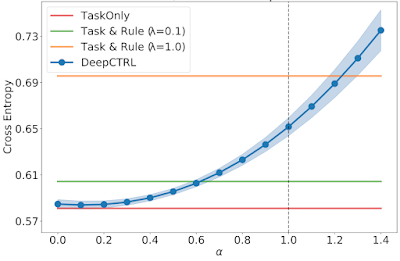 |
| Check cross entropy vs. rule power for a supply dataset with typical / uncommon ratio of 0.30. |
When a educated mannequin is transferred to the goal area, the error could be lowered by controlling α. To display this, we present three domain-specific datasets, which we name Goal 1, 2, and three. In Goal 1, the place nearly all of sufferers are from the typical group, as α is elevated, the rule-based illustration has extra weight and the resultant error decreases monotonically.
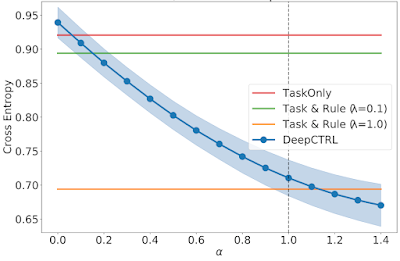 |
| As above, however for a Goal dataset (1) with a typical / uncommon ratio of 0.77. |
When the ratio of typical sufferers is decreased in Goal 2 and three, the optimum α is an intermediate worth between 0 and 1. These display the aptitude to adapt the educated mannequin by way of α.
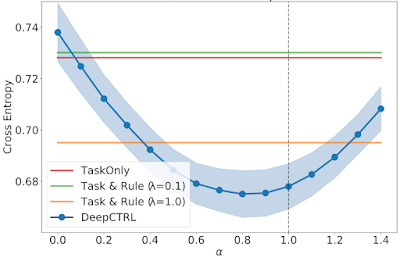 |
| As above, however for Goal 2 with a typical / uncommon ratio of 0.50. |
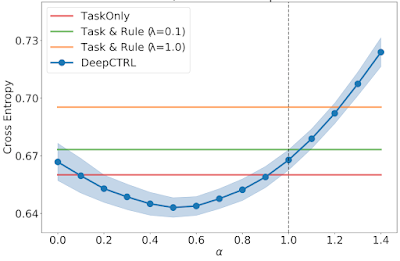 |
| As above, however for Goal 3 with a typical / uncommon ratio of 0.40. |
Conclusions
Studying from guidelines could be essential for setting up interpretable, sturdy, and dependable DNNs. We suggest DeepCTRL, a brand new methodology used to include guidelines into data-learned DNNs. DeepCTRL allows controllability of rule power at inference with out retraining. We suggest a novel perturbation-based rule encoding technique to combine arbitrary guidelines into significant representations. We display three use circumstances of DeepCTRL: bettering reliability given recognized ideas, analyzing candidate guidelines, and area adaptation utilizing the rule power.
Acknowledgements
We significantly respect the contributions of Jinsung Yoon, Xiang Zhang, Kihyuk Sohn and Tomas Pfister.
[ad_2]