

{kind=link}
[ad_1]

Fig. 1: The BRIDGE dataset accommodates 7200 demonstrations of kitchen-themed manipulation duties throughout 71 duties in 10 domains. Word that any GIF compression artifacts on this animation should not current within the dataset itself.
After we apply robotic studying strategies to real-world programs, we should normally gather new datasets for each activity, each robotic, and each surroundings. This isn’t solely pricey and time-consuming, nevertheless it additionally limits the dimensions of the datasets that we are able to use, and this, in flip, limits generalization: if we prepare a robotic to scrub one plate in a single kitchen, it’s unlikely to succeed at cleansing any plate in any kitchen. In different fields, equivalent to pc imaginative and prescient (e.g., ImageNet) and pure language processing (e.g., BERT), the usual method to generalization is to make the most of giant, various datasets, that are collected as soon as after which reused repeatedly. Because the dataset is reused for a lot of fashions, duties, and domains, the up-front value of accumulating such giant reusable datasets is price the advantages. Thus, to acquire really generalizable robotic behaviors, we may have giant and various datasets, and the one technique to make this sensible is to reuse knowledge throughout many various duties, environments, and labs (i.e. totally different background lighting circumstances, and so on.).
Every end-user of such a dataset may need their robotic to study a unique activity, which might be located in a unique area (e.g., a unique laboratory, house, and so on.). Subsequently, any reusable dataset would wish to cowl a enough number of duties and environments to permit the educational algorithm to extract generalizable, reusable options. To this finish, we collected a dataset of 7200 demonstrations for 71 totally different kitchen-themed duties, collected in 10 totally different environments (see the illustration in Determine 1). We confer with this dataset because the BRIDGE dataset (Broad Robotic Interplay Dataset for reinforcing GEneralization)
To review how this dataset may be reused for a number of issues, we take a easy multi-task imitation studying method to coach vision-based management insurance policies on our various multi-task, multi-domain dataset. Our experiments present that by reusing the BRIDGE dataset, we are able to allow a robotic in a brand new scene or surroundings (which was not seen within the bridge knowledge) to extra successfully generalize when studying a brand new activity (which was additionally not seen within the bridge knowledge), in addition to to switch duties from the bridge knowledge to the goal area. Since we use a low-cost robotic arm, the setup can readily be reproduced by different researchers who can use our bridge dataset to spice up the efficiency of their very own robotic insurance policies.
With the proposed dataset and multi-task, multi-domain studying method, we now have proven one potential avenue for making various datasets reusable in robotics, opening up this space for extra refined strategies in addition to offering the arrogance that scaling up this method may result in even higher generalization advantages.
In comparison with current datasets, together with DAML, MIME, Robonet, RoboTurk, and Visible Imitation Made Simple, which primarily deal with a single scene or surroundings, our dataset options a number of domains and a lot of various, semantically significant duties with knowledgeable trajectories, making it nicely fitted to imitation studying and switch studying on new domains.
The environments within the bridge dataset are principally kitchen and sink playsets for youngsters, since they’re comparatively sturdy and low-cost, whereas nonetheless offering settings that resemble typical family scenes. The dataset was collected with 3-5 concurrent viewpoints to offer a type of knowledge augmentation and examine generalization to new viewpoints. Every activity has between 50 and 300 demonstrations. To forestall algorithms from overfitting to sure positions, throughout knowledge assortment, we randomize the kitchen place, the digicam positions, and the positions of distractor objects each 5-25 trajectories.

Fig 2: Demonstration knowledge assortment setup utilizing VR Headset.
We gather our dataset with the 6-dof WidowX250s robotic resulting from its accessibility and affordability, although we welcome contributions of information with totally different robots. The entire value of the setup is lower than US$3600 (excluding the pc). To gather demonstrations, we use an Oculus Quest headset, the place we put the headset on a desk (as illustrated in Determine 2) subsequent to the robotic and monitor the person’s handset whereas making use of the person’s motions to the robotic end-effector through inverse kinematics. This provides the person an intuitive technique for controlling the arm in 6 levels of freedom.
Directions for the way customers can reproduce our setup and gather knowledge in new environments may be discovered on the mission web site.
Switch with Multi-Job Imitation Studying
Whereas a wide range of switch studying strategies have been proposed within the literature for combining datasets from distinct domains, we discover {that a} easy joint coaching method is efficient for deriving appreciable profit from bridge knowledge. We mix the bridge dataset with user-provided demonstrations within the goal area. Because the sizes of those datasets are considerably totally different, we rebalance the datasets (for extra particulars see the paper). Imitation studying then proceeds usually, merely coaching the coverage with supervised studying on the mixed dataset.
Boosting Generalization through Bridge Datasets
We contemplate three varieties of generalization in our experiments:
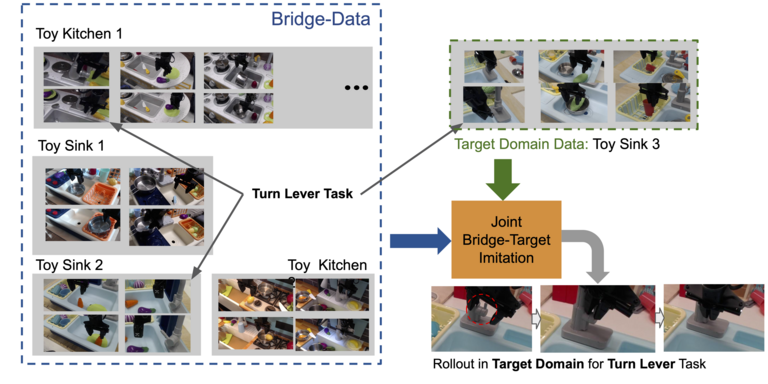
Determine 4: Situation 1, Switch with matching behaviors: Right here, the person collects a small variety of demonstrations within the goal area for a activity that can be current within the bridge knowledge.
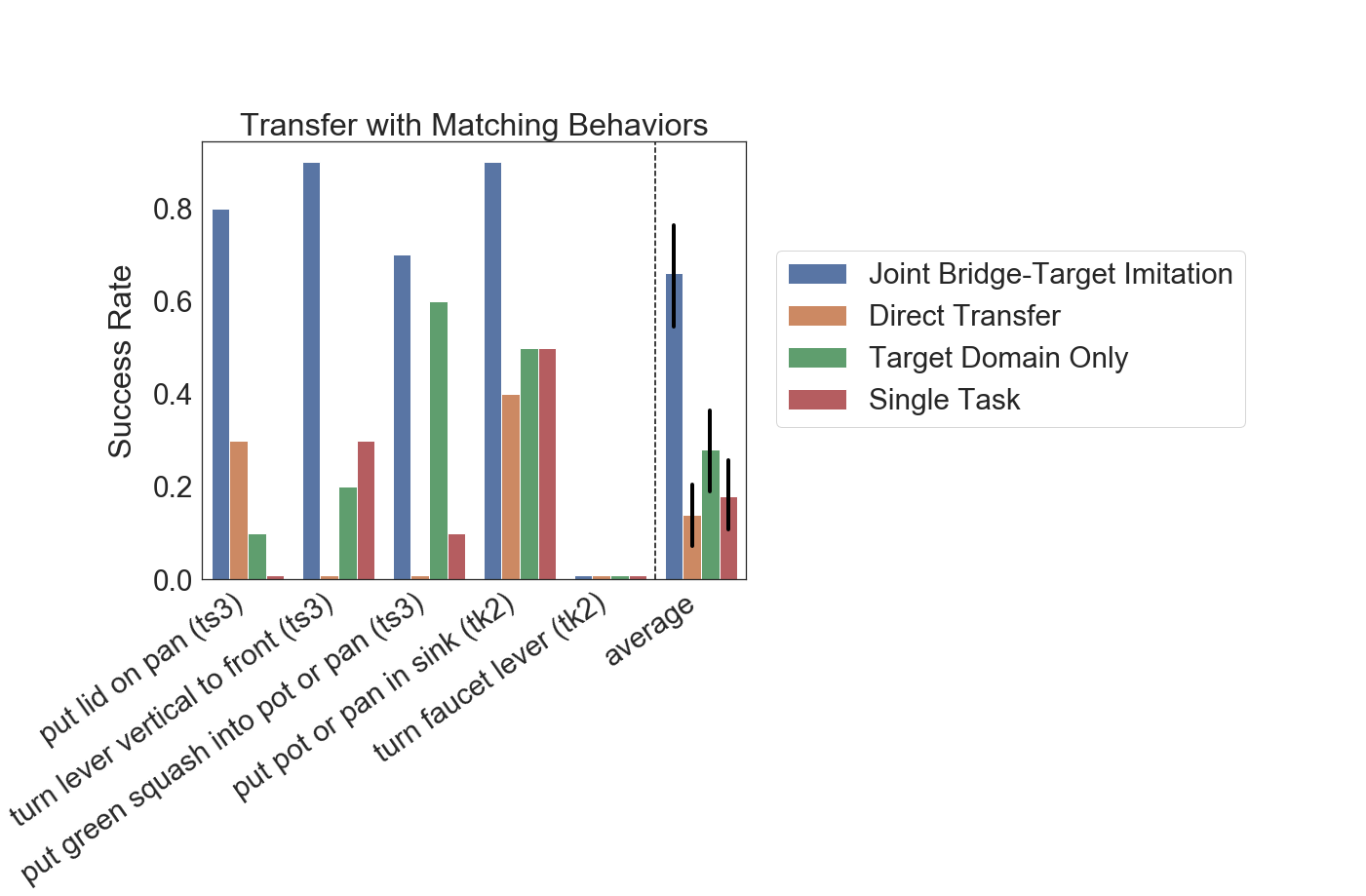
Determine 5: Experiment outcomes for switch with matching behaviors. Collectively coaching with the bridge knowledge drastically improves generalization efficiency.
On this state of affairs (depicted in Determine 4), the person collects some small quantity of information of their goal area for duties which are additionally current within the bridge knowledge (e.g., round 50 demos per activity) and makes use of the bridge knowledge to spice up the efficiency and generalization of those duties. This state of affairs is essentially the most standard and resembles area adaptation in pc imaginative and prescient, however it’s also essentially the most limiting because it requires the specified duties to be current within the bridge knowledge and the person to gather extra knowledge of the identical activity.
Determine 5 reveals outcomes for the switch studying with matching behaviors state of affairs. For comparability, we embody the efficiency of the coverage when educated solely on the goal area knowledge, with out bridge knowledge (Goal Area Solely), a baseline that makes use of solely the bridge knowledge with none goal area knowledge (Direct Switch), in addition to a baseline that trains a single-task coverage on knowledge within the goal area solely (Single Job). As may be seen within the outcomes, collectively coaching with the bridge knowledge results in vital features in efficiency (66% success averaged over duties) in comparison with the direct switch (14% success), goal area solely (28% success), and the one activity (18% success) baseline. This isn’t stunning since this state of affairs immediately augments the coaching set with extra knowledge of the identical duties, nevertheless it nonetheless supplies a validation of the worth of together with bridge knowledge in coaching.
![]()
Determine 6: Situation 2, Zero-shot switch with goal assist: After accumulating knowledge for a small variety of duties (10 in our case) within the goal area, the person is ready to switch different duties from the bridge dataset to the goal area.
![]()
Determine 7: Experiment outcomes for zero-shot switch with goal assist: Joint bridge-target imitation, which is educated with bridge knowledge and knowledge from 10 goal area duties, permits transferring duties to the goal area with considerably larger success charges (blue) than immediately transferring duties (with none goal area knowledge), known as direct switch (orange).
On this state of affairs (depicted in Determine 6), the person makes use of knowledge from a couple of duties of their goal area to “import” different duties which are current within the bridge knowledge with out moreover accumulating new demonstrations for them within the goal area. For instance, the bridge knowledge accommodates the duties of placing a candy potato right into a pot or a pan, the person supplies knowledge of their area for placing brushes in pans, and the robotic is then capable of each put brushes in addition to put candy potatoes in pans. This state of affairs will increase the repertoires of expertise which are out there within the person’s goal surroundings just by together with the bridge knowledge, thus eliminating the necessity to recollect knowledge for each activity in each goal surroundings.
Determine 7 reveals the experiment outcomes for this state of affairs. Since there isn’t a goal area knowledge for these duties, we can’t examine to a baseline that doesn’t use bridge knowledge in any respect since such a baseline would haven’t any knowledge for these duties. Nevertheless, we do embody the “direct switch” baseline, which makes use of a coverage educated solely on the bridge knowledge. The outcomes point out that the collectively educated coverage, which obtains 44% success averaged over duties certainly attains a really vital improve in efficiency over direct switch (30% success), suggesting that the zero-shot switch with goal assist state of affairs provides a viable method for customers to “import” duties from the bridge dataset into their area.
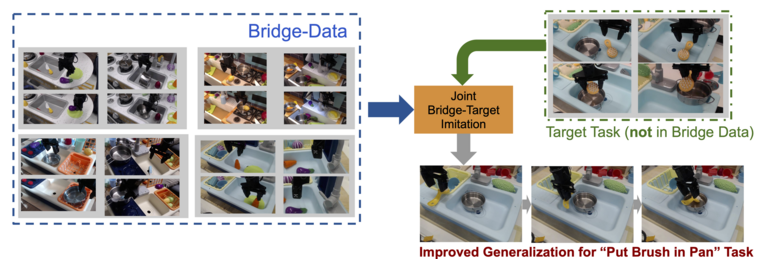
Determine 8:Situation 3, Boosting generalization of latest duties: Collectively coaching with bridge knowledge and a brand new activity in a brand new scene or surroundings (that isn’t current within the bridge knowledge) permits considerably larger success charges than coaching on the goal area knowledge from scratch.
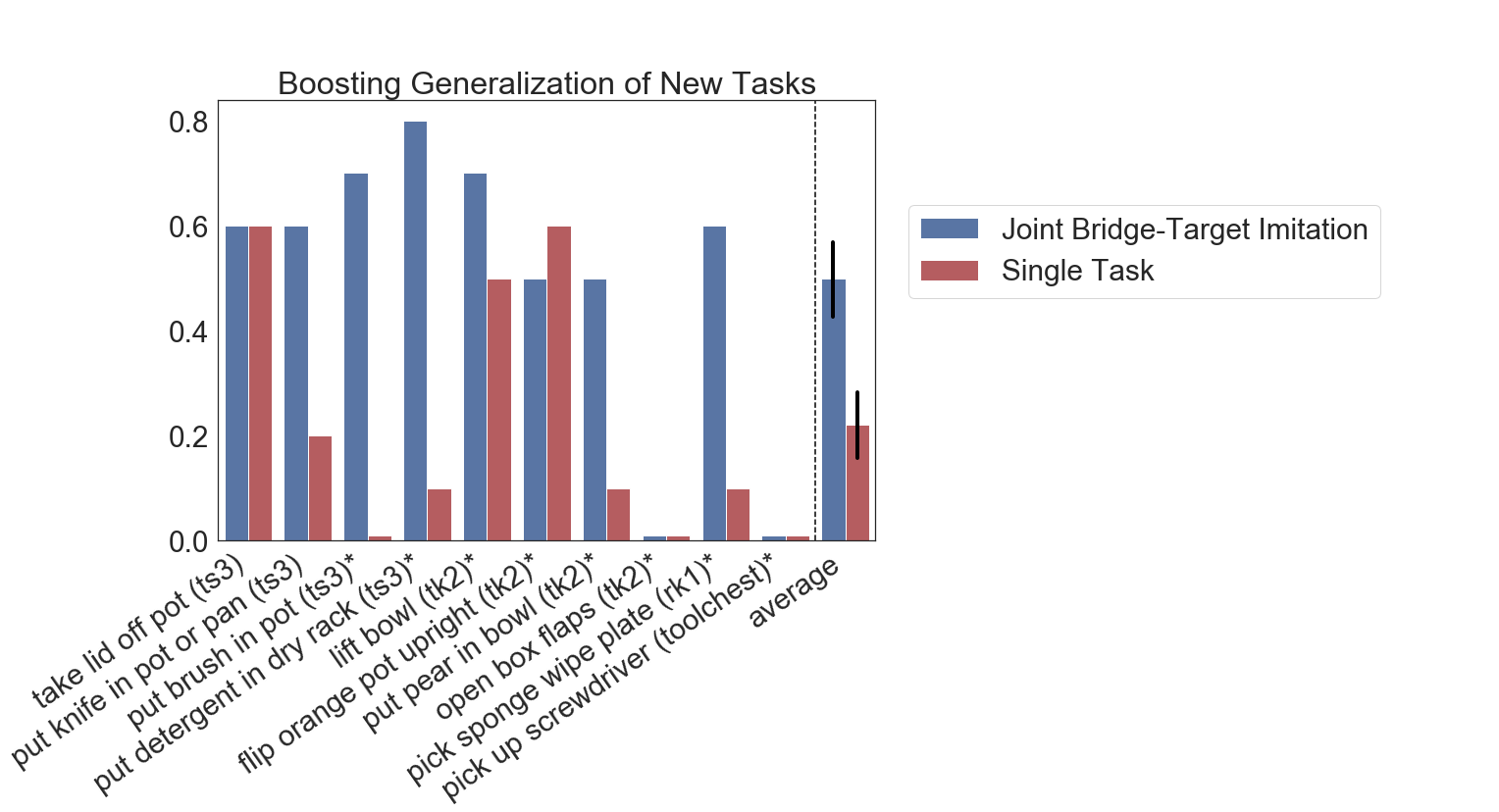
Determine 9: Experiment outcomes for reinforcing generalization of latest duties: Collectively coaching with bridge knowledge (blue) on common results in a 2x acquire in generalization efficiency in comparison with solely coaching on the right track area knowledge (purple).
On this state of affairs (depicted in Determine 8), the person supplies a small quantity of information (50 demonstrations in apply) for a brand new activity that isn’t current within the bridge knowledge after which makes use of the bridge knowledge to spice up the generalization and efficiency of this activity. This state of affairs most immediately displays our major objectives because it makes use of the bridge knowledge with out requiring both the domains or duties to match, leveraging the variety of the info and structural similarity to spice up efficiency and generalization of fully new duties.
To allow this sort of generalization boosting, we conjecture that the important thing options that bridge datasets should have are: (i) a enough number of settings, in order to offer for good generalization; (ii) shared construction between bridge knowledge domains and goal domains (i.e., it’s unreasonable to count on generalization for a building robotic utilizing bridge knowledge of kitchen duties); (iii) a enough vary of duties that breaks undesirable correlations between duties and domains.
The experiment outcomes are introduced in Determine 9, which present that coaching collectively with the bridge knowledge results in vital enchancment on 6 out of 10 duties throughout three analysis environments, resulting in 50% success averaged over duties, whereas single activity insurance policies attain round 22% success – a 2x enchancment in total efficiency (the asterisks denote through which experiments the objects should not contained within the bridge knowledge). The numerous enhancements obtained from together with the bridge knowledge recommend that bridge datasets generally is a highly effective car for reinforcing the generalization of latest expertise and {that a} single shared bridge dataset may be utilized throughout a variety of domains and functions.
In Determine 10 we present instance rollouts for every of the three switch situations.



Determine 10: Instance rollouts of insurance policies collectively educated on the right track area knowledge and bridge knowledge in every of the three switch situations.
Left: switch with matching behaviors, state of affairs 1, put pot in sink;
Center: zero-shot switch with goal assist, state of affairs 2, put carrot on plate;
Proper: boosting generalization of latest duties, state of affairs 3, wipe plate with sponge
We confirmed how a big, various bridge dataset may be leveraged in three alternative ways to enhance generalization in robotic studying. Our experiments show that together with bridge knowledge when coaching expertise in a brand new area can enhance efficiency throughout a variety of situations, each for duties which are current within the bridge knowledge and, maybe surprisingly, fully new duties. Which means that bridge knowledge might present a generic software to enhance generalization in a person’s goal area. As well as, we confirmed that bridge knowledge also can perform as a software to import duties from the prior dataset to a goal area, thus rising the repertoires of expertise a person has at their disposal in a selected goal area. This implies that a big, shared bridge dataset, just like the one we now have launched, may very well be utilized by totally different robotics researchers to spice up the generalization capabilities and the variety of out there expertise of their imitation-trained insurance policies.
We hope that by releasing our dataset to the group, we are able to take a step towards generalizing robotic studying and make it doable for anybody to coach robotic insurance policies that rapidly generalize to different environments with out repeatedly accumulating giant and exhaustive datasets.
We encourage researchers to go to our mission web site for extra data and directions for methods to contribute to our dataset.
Please discover the corresponding paper on arxiv.
We thank Chelsea Finn and Sergey Levine for useful suggestions on the weblog submit.
This submit relies on the next paper:
Bridge Information: Boosting Generalization of Robotic Expertise with Cross-Area Datasets
Frederik Ebert(^*), Yanlai Yang(^*), Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, Sergey Levine
paper, mission web site
[ad_2]