
{kind=link}
[ad_1]
Machine studying (ML) is more and more being utilized in real-world functions, so understanding the uncertainty and robustness of a mannequin is critical to make sure efficiency in observe. For instance, how do fashions behave when deployed on knowledge that differs from the information on which they have been educated? How do fashions sign when they’re more likely to make a mistake?
To get a deal with on an ML mannequin’s conduct, its efficiency is usually measured towards a baseline for the duty of curiosity. With every baseline, researchers should attempt to reproduce outcomes solely utilizing descriptions from the corresponding papers , which leads to severe challenges for replication. Accessing the code for experiments could also be extra helpful, assuming it’s well-documented and maintained. However even this isn’t sufficient, as a result of the baselines should be rigorously validated. For instance, in retrospective analyses over a set of works [1, 2, 3], authors typically discover {that a} easy well-tuned baseline outperforms extra refined strategies. With a view to really perceive how fashions carry out relative to one another, and allow researchers to measure whether or not new concepts actually yield significant progress, fashions of curiosity should be in comparison with a typical baseline.
In “Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Studying”, we introduce Uncertainty Baselines, a set of high-quality implementations of ordinary and state-of-the-art deep studying strategies for quite a lot of duties, with the purpose of constructing analysis on uncertainty and robustness extra reproducible. The gathering spans 19 strategies throughout 9 duties, every with not less than 5 metrics. Every baseline is a self-contained experiment pipeline with simply reusable and extendable parts and with minimal dependencies exterior of the framework through which it’s written. The included pipelines are carried out in TensorFlow, PyTorch, and Jax. Moreover, the hyperparameters for every baseline have been extensively tuned over quite a few iterations in order to supply even stronger outcomes.
Uncertainty Baselines
As of this writing, Uncertainty Baselines gives a complete of 83 baselines, comprising 19 strategies encompassing customary and more moderen methods over 9 datasets. Instance strategies embrace BatchEnsemble, Deep Ensembles, Rank-1 Bayesian Neural Nets, Monte Carlo Dropout, and Spectral-normalized Neural Gaussian Processes. It acts as a successor in merging a number of fashionable benchmarks locally: Can You Belief Your Mannequin’s Uncertainty?, BDL benchmarks, and Edward2’s baselines.
A subset of 5 out of 9 out there datasets for which baselines are supplied. The datasets span tabular, textual content, and picture modalities.
Uncertainty Baselines units up every baseline beneath a selection of base mannequin, coaching dataset, and a set of analysis metrics. Every is then tuned over its hyperparameters to maximise efficiency on such metrics. The out there baselines range amongst these three axes:
- Base fashions (architectures) embrace Vast ResNet 28-10, ResNet-50, BERT, and easy fully-connected networks.
- Coaching datasets embrace customary machine studying datasets (CIFAR, ImageNet, and UCI) in addition to extra real-world issues (Clinc Intent Detection, Kaggle’s Diabetic Retinopathy Detection, and Wikipedia Toxicity).
- Analysis consists of predictive metrics (e.g., accuracy), uncertainty metrics (e.g., selective prediction and calibration error), compute metrics (inference latency), and efficiency on in- and out-of-distribution datasets.
Modularity and Reusability
To ensure that researchers to make use of and construct on the baselines, we intentionally optimized them to be as modular and minimal as potential. As seen within the workflow determine under, Uncertainty Baselines introduces no new class abstractions, as a substitute reusing lessons that pre-exist within the ecosystem (e.g., TensorFlow’s tf.knowledge.Dataset). The practice/analysis pipeline for every of the baselines is contained in a standalone Python file for that experiment, which may run on CPU, GPU, or Google Cloud TPUs. Due to this independence between baselines, we’re in a position to develop baselines in any of TensorFlow, PyTorch or JAX.
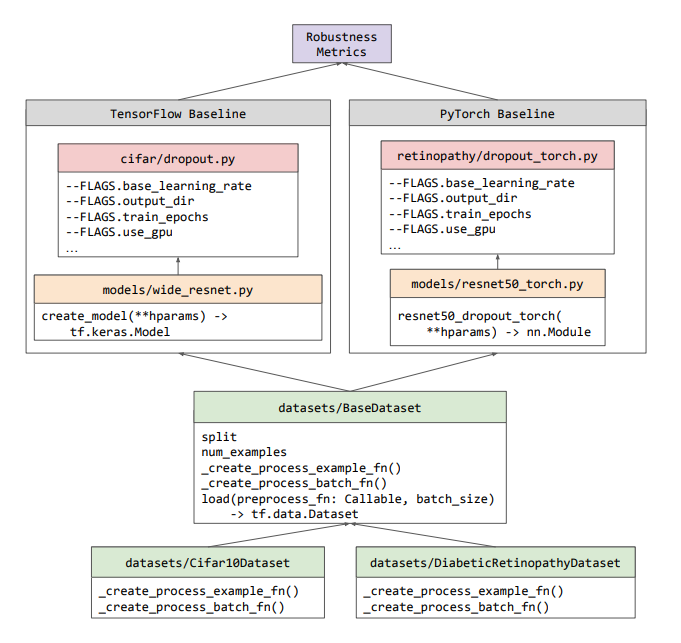 |
| Workflow diagram for a way the completely different parts of Uncertainty Baselines are structured. All datasets are subclasses of the BaseDataset class, which gives a easy API to be used in baselines written with any of the supported frameworks. The outputs from any of the baselines can then be analyzed with the Robustness Metrics library. |
One space of debate amongst analysis engineers is tips on how to handle hyperparameters and different experiment configuration values, which may simply quantity within the dozens. As an alternative of utilizing one of many many frameworks constructed for this, and danger customers having to study yet one more library, we opted to easily use Python flags, i.e., flags outlined utilizing Abseil that comply with Python conventions. This ought to be a well-known method to most researchers, and is simple to increase and plug into different pipelines.
Reproducibility
Along with having the ability to run every of our baselines utilizing the documented instructions and get the identical reported outcomes, we additionally purpose to launch hyperparameter tuning outcomes and closing mannequin checkpoints for additional reproducibility. Proper now we solely have these absolutely open-sourced for the Diabetic Retinopathy baselines, however we’ll proceed to add extra outcomes as we run them. Moreover, we have now examples of baselines which are precisely reproducible as much as {hardware} determinism.
Sensible Affect
Every of the baselines included in our repository has gone by intensive hyperparameter tuning, and we hope that researchers can readily reuse this effort with out the necessity for costly retraining or retuning. Moreover, we hope to keep away from minor variations within the pipeline implementations affecting baseline comparisons.
Uncertainty Baselines has already been utilized in quite a few analysis tasks. If you’re a researcher with different strategies or datasets you wish to contribute, please open a GitHub challenge to begin a dialogue!
Acknowledgements
We wish to thank numerous of us who’re codevelopers, supplied steering, and/or helped evaluate this publish: Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal.
[ad_2]