
{kind=link}
[ad_1]
This weblog publish is the primary of a three-part collection authored by software program builders and designers at IBM and Cloudera. This primary publish focuses on integration factors of the lately introduced joint providing: Cloudera Information Platform for IBM Cloud Pak for Information. The second publish will have a look at how Cloudera Information Platform was put in on IBM Cloud utilizing Ansible. And the third publish will concentrate on classes realized from putting in, sustaining, and verifying the connectivity of the 2 platforms. Let’s get began!
On this publish we might be outlining the principle integration factors between Cloudera Information Platform and IBM Cloud Pak for Information, and explaining how the 2 distinct knowledge and AI platforms can talk with one another. Integrating two platforms is made straightforward with capabilities out there out of the field for each IBM Cloud Pak for Information and Cloudera Information Platform. Establishing a connection between the 2 is just some clicks away.
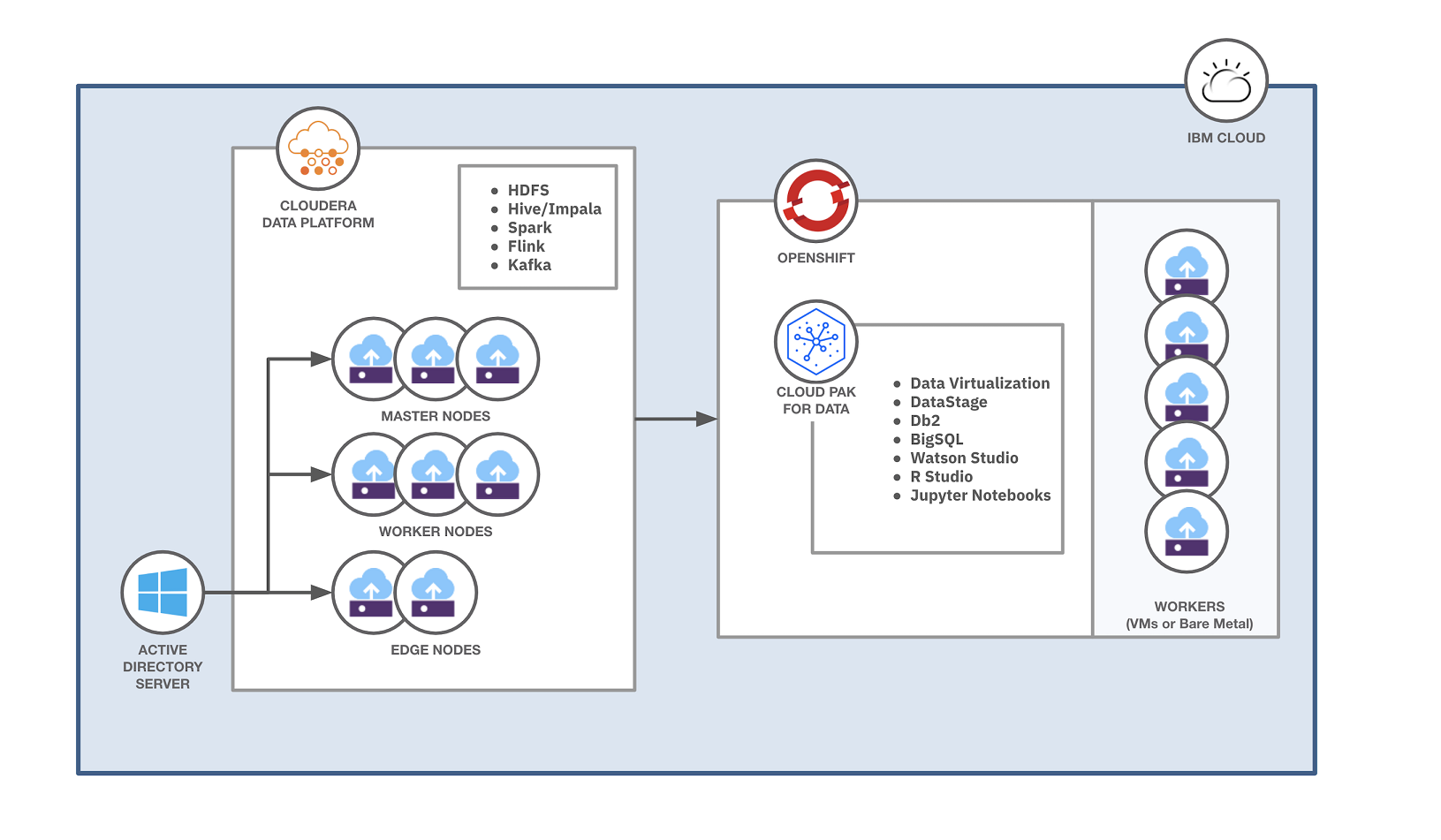
Structure diagram displaying Cloudera Information Plaform for Cloud Pak for Information
In our view, there are three key factors to integrating Cloudera Information Platform and IBM Cloud Pak for Information; all different companies piggyback on one among these:
Learn on for extra details about how every integration level works. For an indication on the best way to use knowledge from Hive and Db2 take a look at the video beneath the place we be a part of the information utilizing Information Virtualization after which show it with IBM Cognos Analytics take a look at the video beneath.
Apache Knox Gateway
To actually be safe, a Hadoop cluster wants Kerberos. Nonetheless, Kerberos requires a client-side library and complicated client-side configuration. That is the place the Apache Knox Gateway (“Knox”) is available in. By encapsulating Kerberos, Knox eliminates the necessity for shopper software program or shopper configuration and, thus, simplifies the entry mannequin. Knox integrates with id administration and SSO methods, corresponding to Energetic Listing and LDAP, to permit identities from these methods for use for entry to Cloudera clusters.
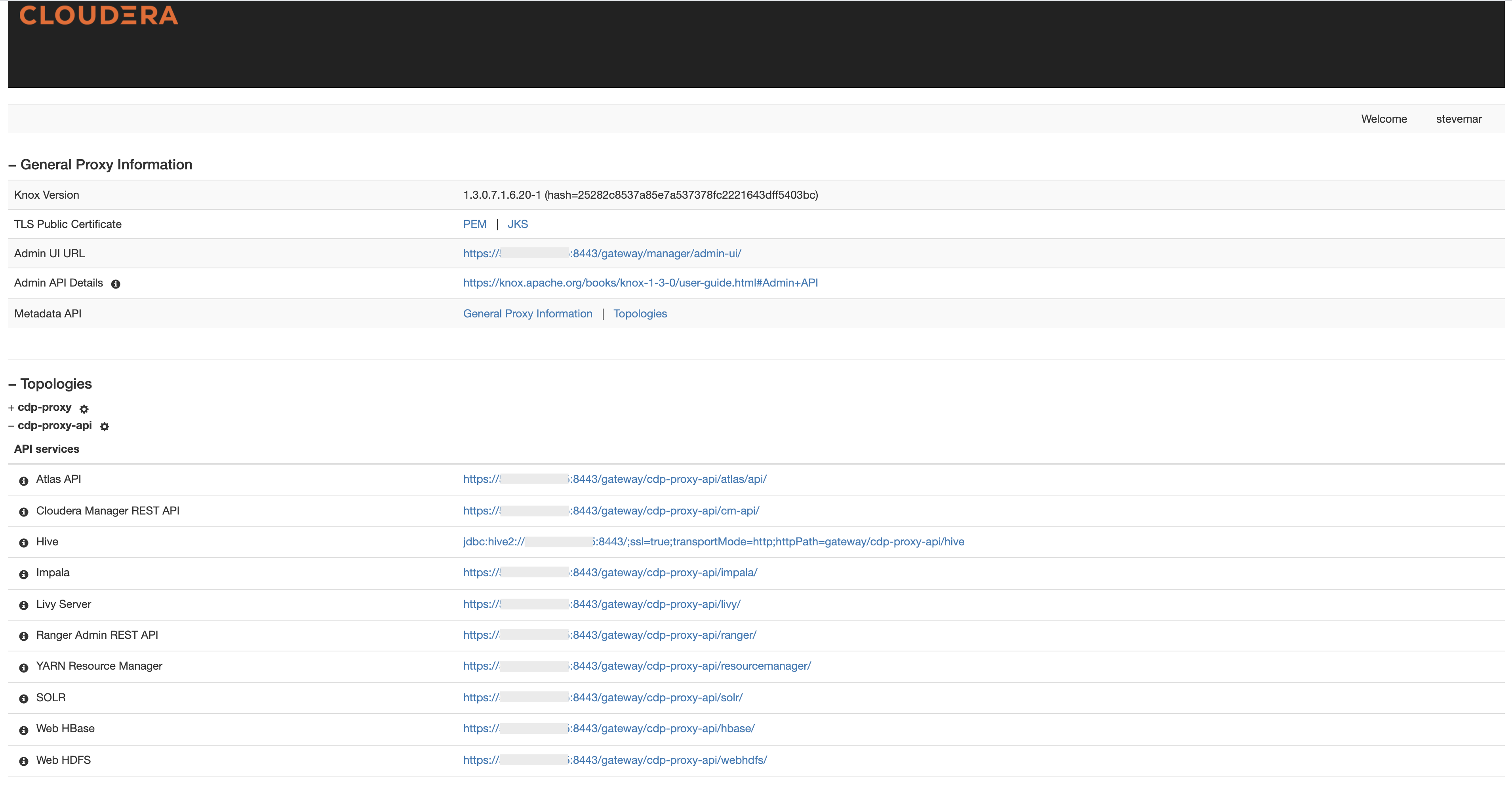
Knox dashboard displaying the checklist of supported companies
Cloudera companies corresponding to Impala, Hive, and HDFS could be configured with Knox, permitting JDBC connections to simply be created in IBM Cloud Pak for Information.
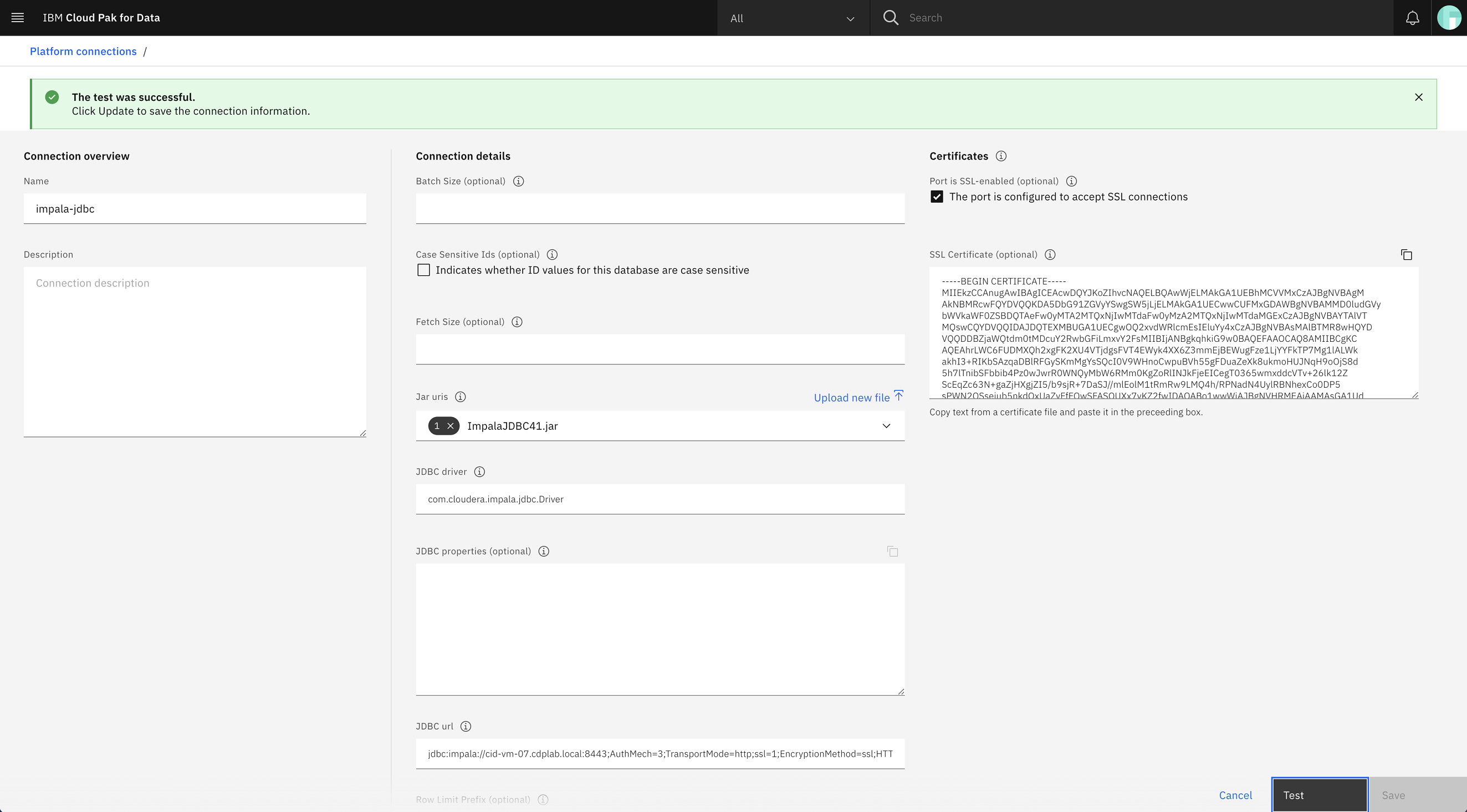
Making a JDBC connection to Impala through Knox
Record of connections on IBM Cloud Pak for Information
Execution Engine for Apache Hadoop
The Execution Engine for Apache Hadoop service is put in on each IBM Cloud Pak for Information and on the employee nodes of a Cloudera Information Platform deployment. Execution Engine for Hadoop permits customers to:
- Browse distant Hadoop knowledge (HDFS, Impala, or Hive) by way of platform-level connections
- Cleanse and form distant Hadoop knowledge (HDFS, Impala, or Hive) with Information Refinery
- Run a Jupyter pocket book session on the distant Hadoop system
- Entry Hadoop methods with fundamental utilities from RStudio and Jupyter notebooks
After putting in and configuring the companies on IBM Cloud Pak for Information and Cloudera Information Platform, you’ll be able to create platform-level connections to HDFS, Impala, and Hive.

Execution Engine for Hadoop connection choices
As soon as a connection has been established, knowledge from HDFS, Impala, or Hive could be browsed and imported.
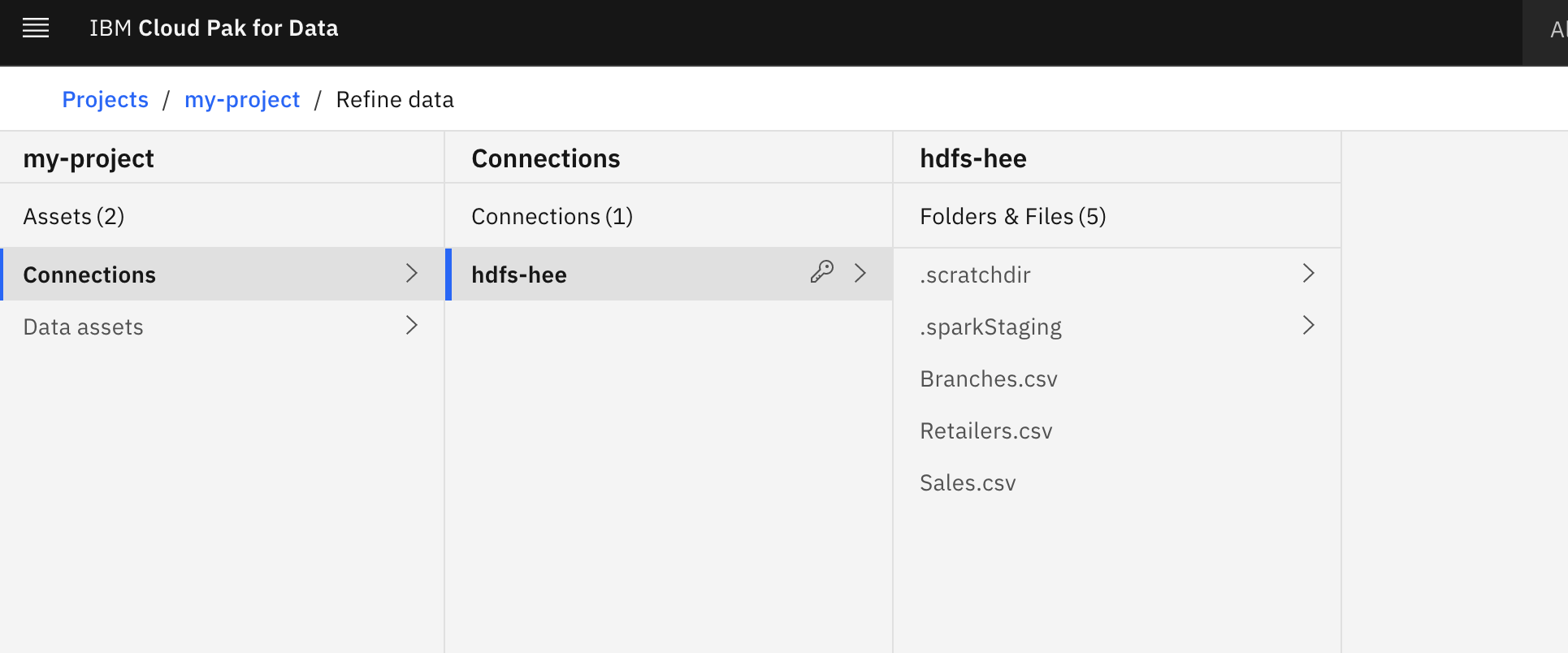
Searching by way of an HDFS connection made through Execution Engine for Hadoop
Information residing in HDFS, Impala or Hive could be cleaned and modified by way of Information Refinery on IBM Cloud Pak for Information.
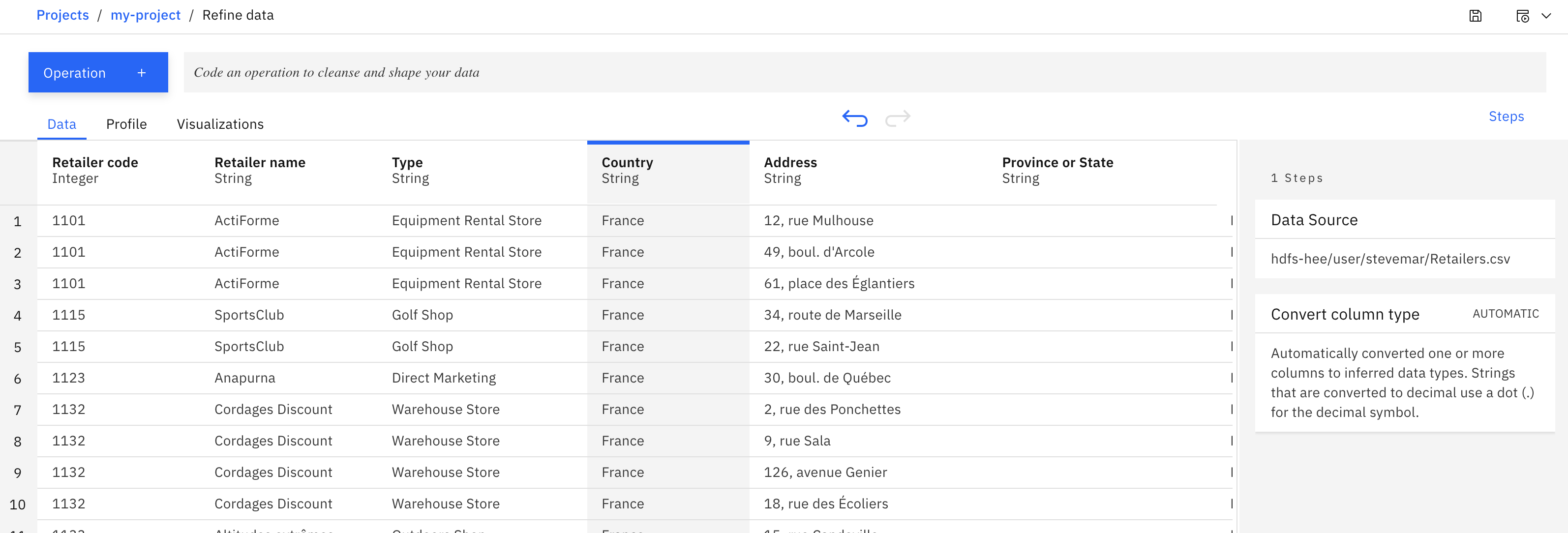
Information Refinery permits for operations to be run on knowledge
The Hadoop Execution Engine additionally permits for Jupyter pocket book classes to hook up with a distant Hadoop system.
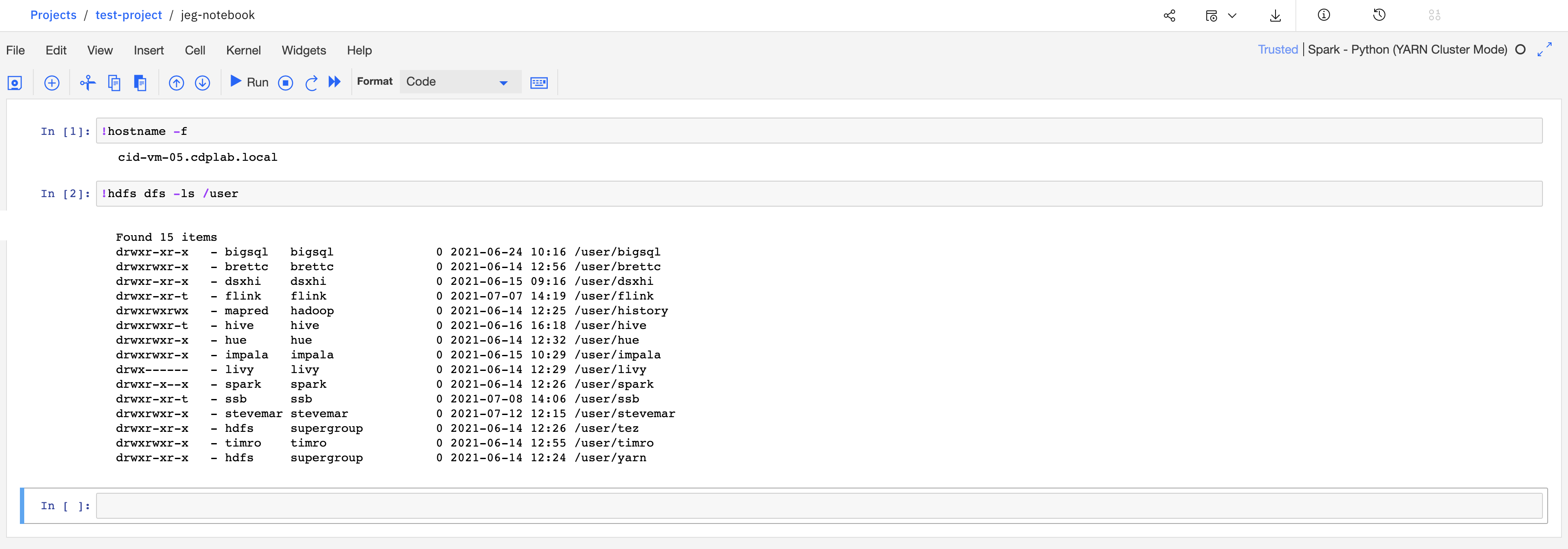
Jupyter pocket book connecting to a distant HDFS
Db2 Huge SQL
The Db2 Huge SQL service is put in on IBM Cloud Pak for Information and is configured to speak with a Cloudera Information Platform deployment. Db2 Huge SQL permits customers to:
- Question knowledge saved on Hadoop companies corresponding to HDFS and Hive
- Question giant quantities of knowledge residing in a secured (Kerberized) or unsecured Hadoop-based platform
As soon as Huge SQL is configured, you’ll be able to select what knowledge to synchronize into tables. As soon as in a desk, it can save you the information to a undertaking, run queries in opposition to it, or browse the information. Ranger, a Cloudera service that can be utilized to enable or deny entry, is critical for use with Huge SQL.
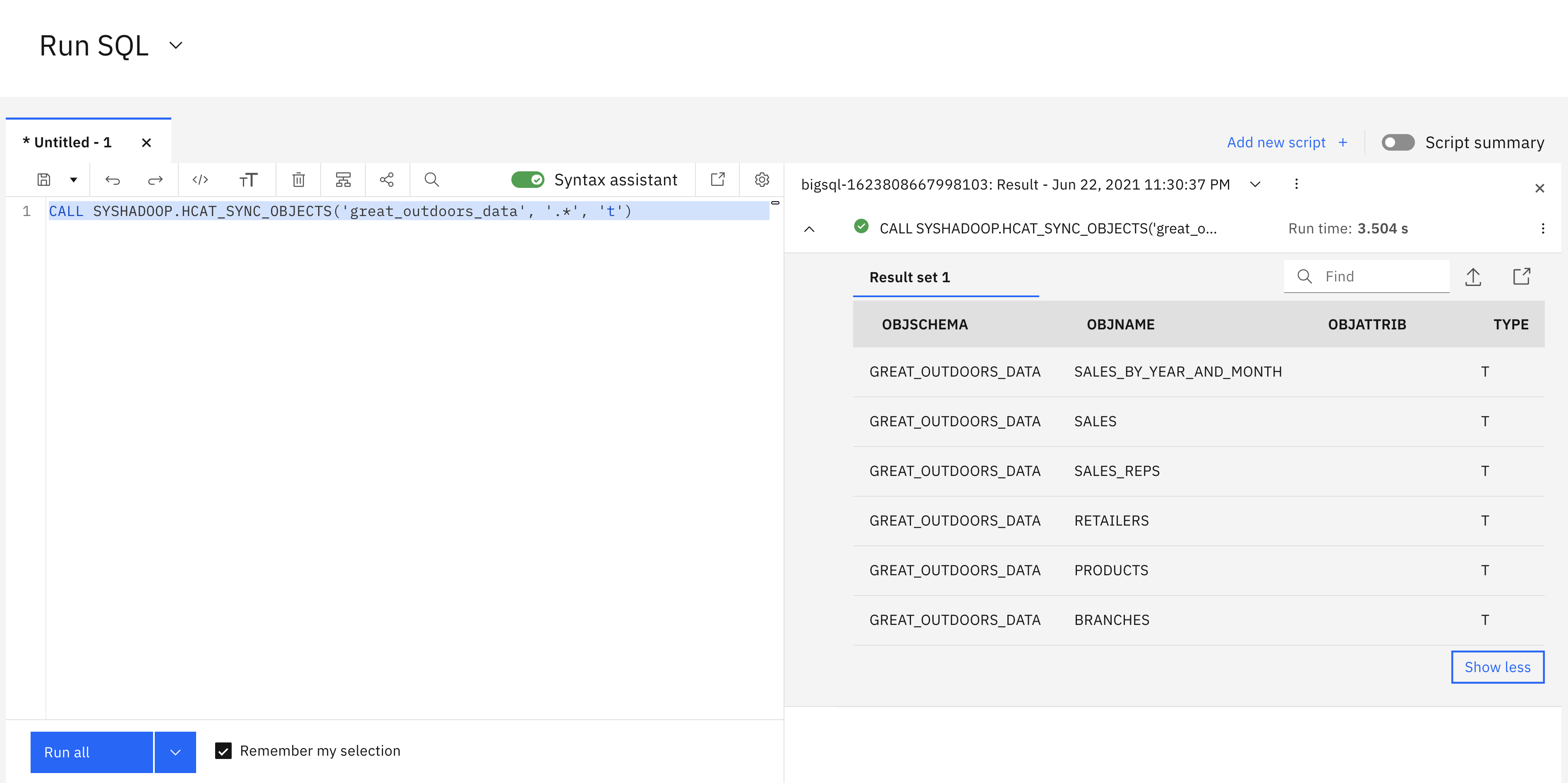
Synchronizing knowledge from Hive to a Db2 desk in Huge SQL
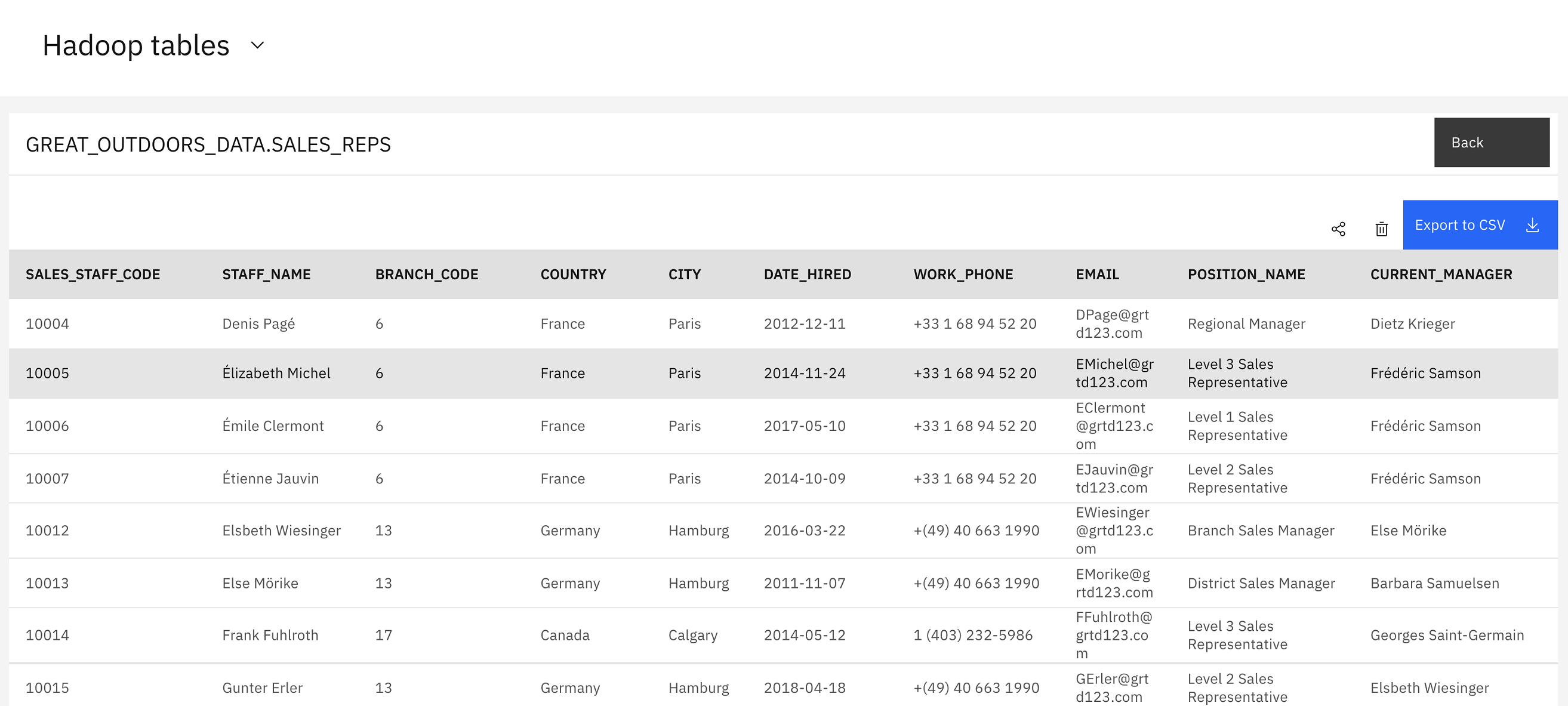
Previewing synchronized knowledge from Hive
One other good thing about configuring Db2 Huge SQL to work together along with your Cloudera cluster is {that a} JDBC connection is created that may be leveraged by many different IBM Cloud Pak for Information companies, corresponding to Information Virtualization, Cognos Analytics, and Watson Data Catalog.
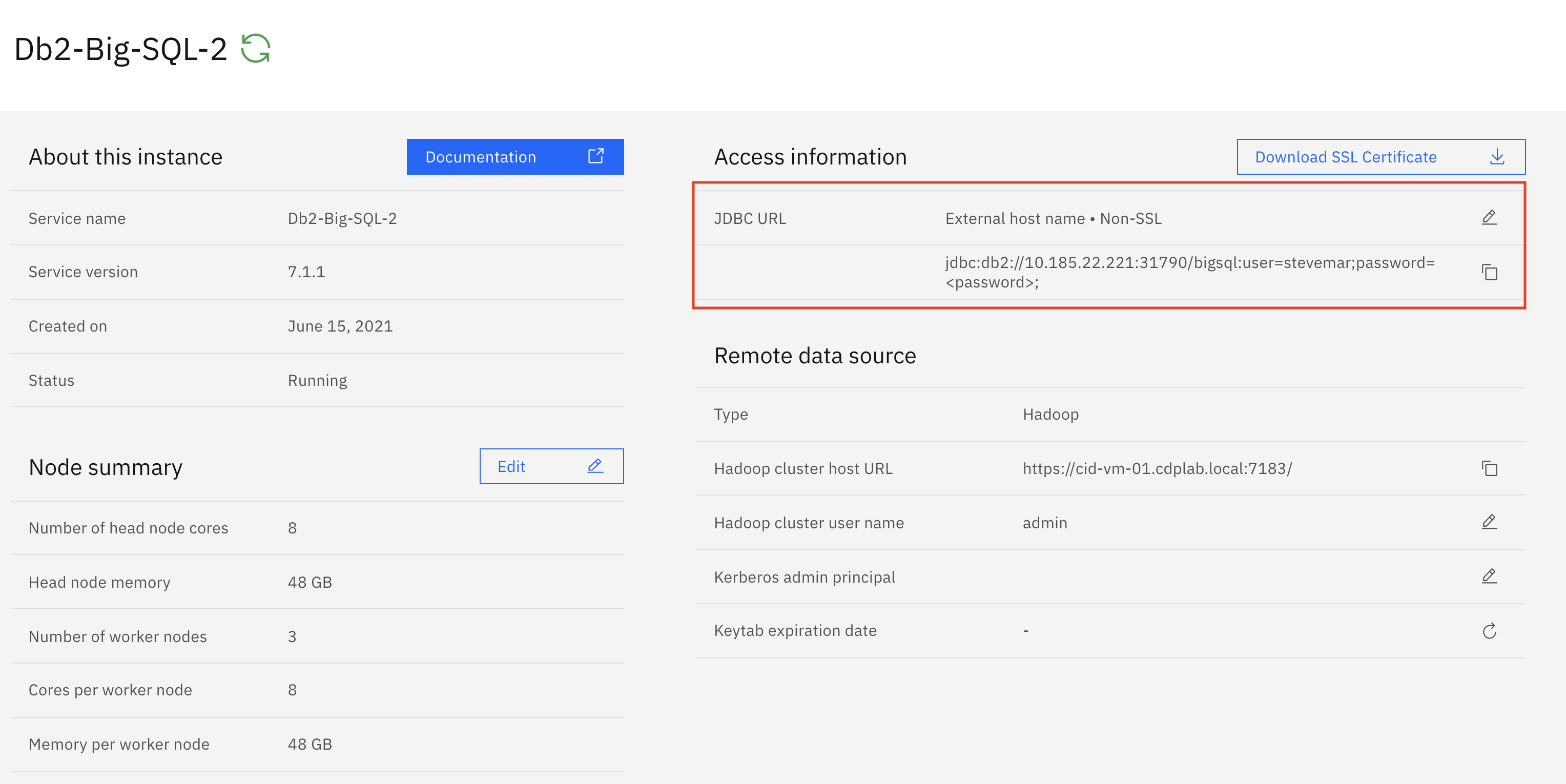
JDBC connection info for an occasion of Huge SQL

The BigSQL JDBC connection being consumed by Cognos Analytics

The BigSQL JDBC connection being consumed by DataStage
Abstract and subsequent steps
We hope you realized extra about how combine IBM Cloud Pak for Information and Cloudera Information Platform. Study extra concerning the Cloudera Information Platform for IBM Cloud Pak for Information by checking our the product web page or go to the IBM Hybrid Information Administration Neighborhood to publish questions and discuss to our consultants.
In case you loved this, take a look at the video beneath the place Omkar Nimbalkar and Nadeem Asghar talk about the IBM and Cloudera partnership.
[ad_2]