
{kind=link}
[ad_1]
The query of tips on how to compile quicker and smaller code arose along with the beginning of modem computer systems. Higher code optimization can considerably scale back the operational value of huge datacenter purposes. The scale of compiled code issues essentially the most to cellular and embedded methods or software program deployed on safe boot partitions, the place the compiled binary should slot in tight code dimension budgets. With advances within the subject, the headroom has been closely squeezed with more and more sophisticated heuristics, impeding upkeep and additional enhancements.
Latest analysis has proven that machine studying (ML) can unlock extra alternatives in compiler optimization by changing sophisticated heuristics with ML insurance policies. Nonetheless, adopting ML in general-purpose, industry-strength compilers stays a problem.
To handle this, we introduce “MLGO: a Machine Studying Guided Compiler Optimizations Framework”, the primary industrial-grade normal framework for integrating ML methods systematically in LLVM (an open-source industrial compiler infrastructure that’s ubiquitous for constructing mission-critical, high-performance software program). MLGO makes use of reinforcement studying (RL) to coach neural networks to make selections that may substitute heuristics in LLVM. We describe two MLGO optimizations for LLVM: 1) lowering code dimension with inlining; and a couple of) enhancing code efficiency with register allocation (regalloc). Each optimizations can be found within the LLVM repository, and have been deployed in manufacturing.
How Does MLGO Work? With Inlining-for-Dimension As a Case Examine
Inlining helps scale back code dimension by making selections that allow the removing of redundant code. Within the instance beneath, the caller operate foo() calls the callee operate bar(), which itself calls baz(). Inlining each callsites returns a easy foo() operate that reduces the code dimension.
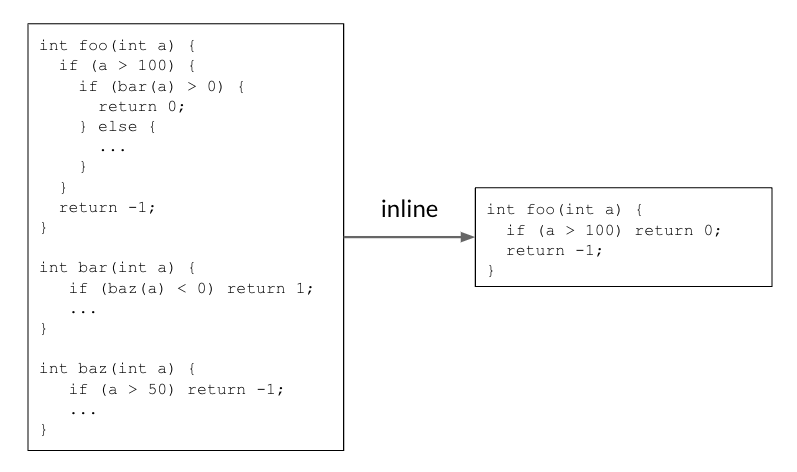 |
| Inlining reduces code dimension by eradicating redundant code. |
In actual code, there are literally thousands of features calling one another, and thus comprise a name graph. In the course of the inlining section, the compiler traverses over the decision graph on all caller-callee pairs, and makes selections on whether or not to inline a caller-callee pair or not. It’s a sequential determination course of as earlier inlining selections will alter the decision graph, affecting later selections and the ultimate outcome. Within the instance above, the decision graph foo() → bar() → baz() wants a “sure” determination on each edges to make the code dimension discount occur.
Earlier than MLGO, the inline / no-inline determination was made by a heuristic that, over time, grew to become more and more tough to enhance. MLGO substitutes the heuristic with an ML mannequin. In the course of the name graph traversal, the compiler seeks recommendation from a neural community on whether or not to inline a specific caller-callee pair by feeding in related options (i.e., inputs) from the graph, and executes the selections sequentially till the entire name graph is traversed.
 |
| Illustration of MLGO throughout inlining. “#bbs”, “#customers”, and “callsite peak” are instance caller-callee pair options. |
MLGO trains the choice community (coverage) with RL utilizing coverage gradient and evolution methods algorithms. Whereas there isn’t a floor fact about greatest selections, on-line RL iterates between coaching and working compilation with the educated coverage to gather knowledge and enhance the coverage. Particularly, given the present mannequin beneath coaching, the compiler consults the mannequin for inline / no-inline determination making in the course of the inlining stage. After the compilation finishes, it produces a log of the sequential determination course of (state, motion, reward). The log is then handed to the coach to replace the mannequin. This course of repeats till we get hold of a passable mannequin.
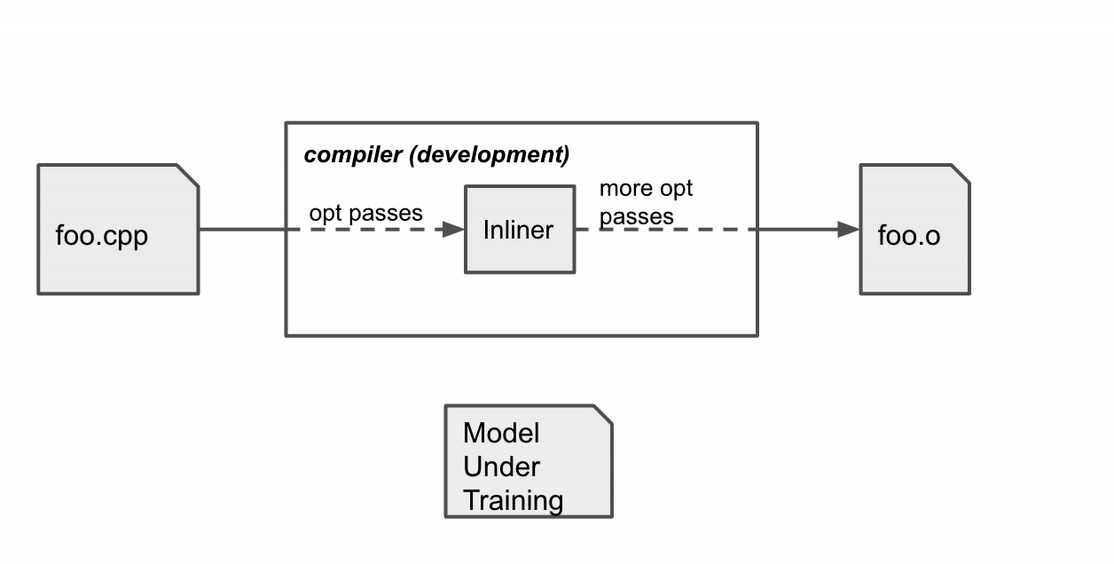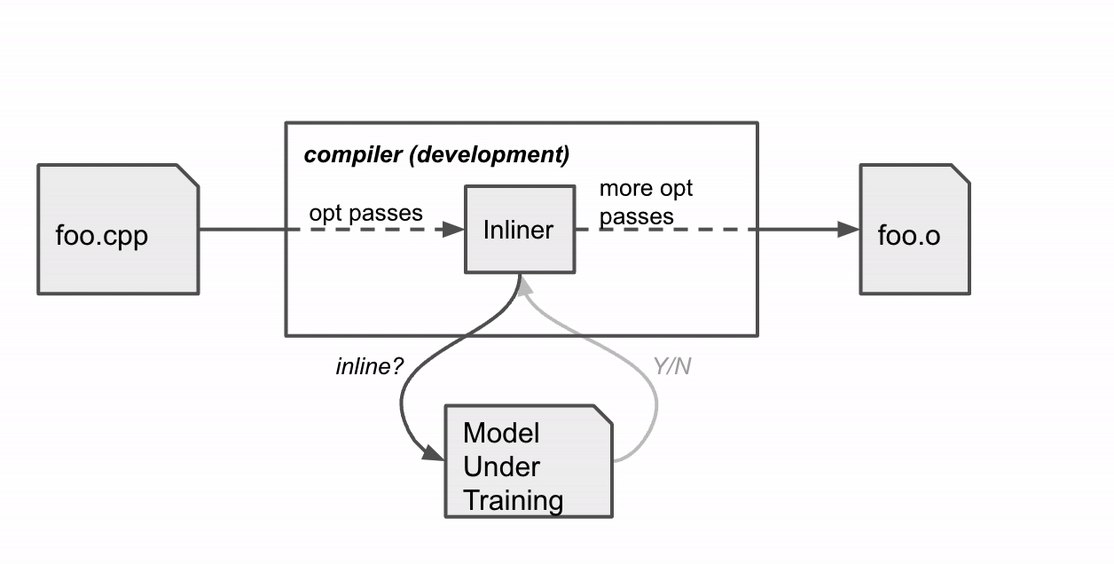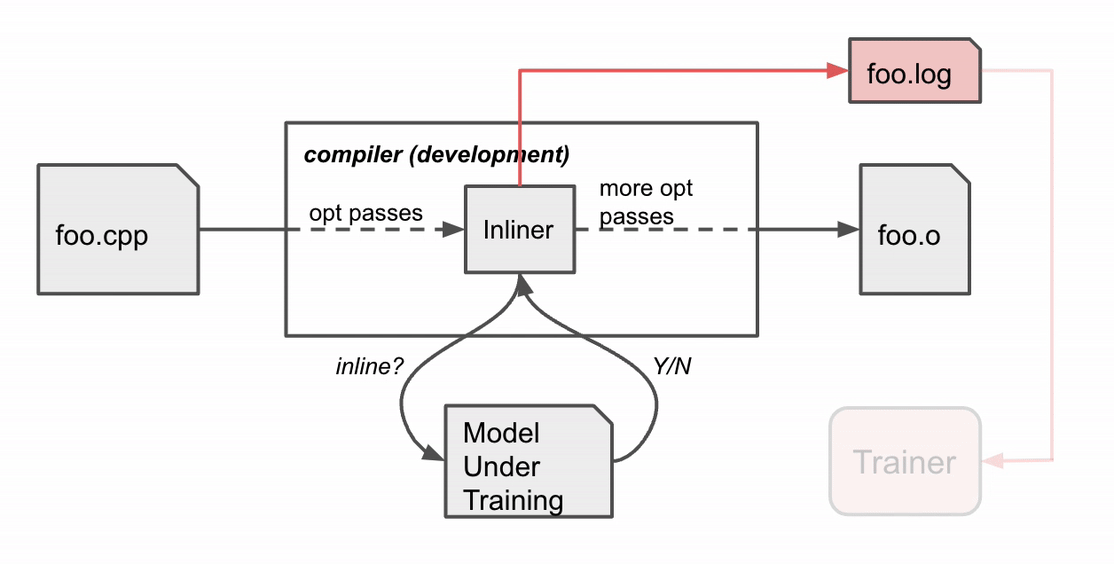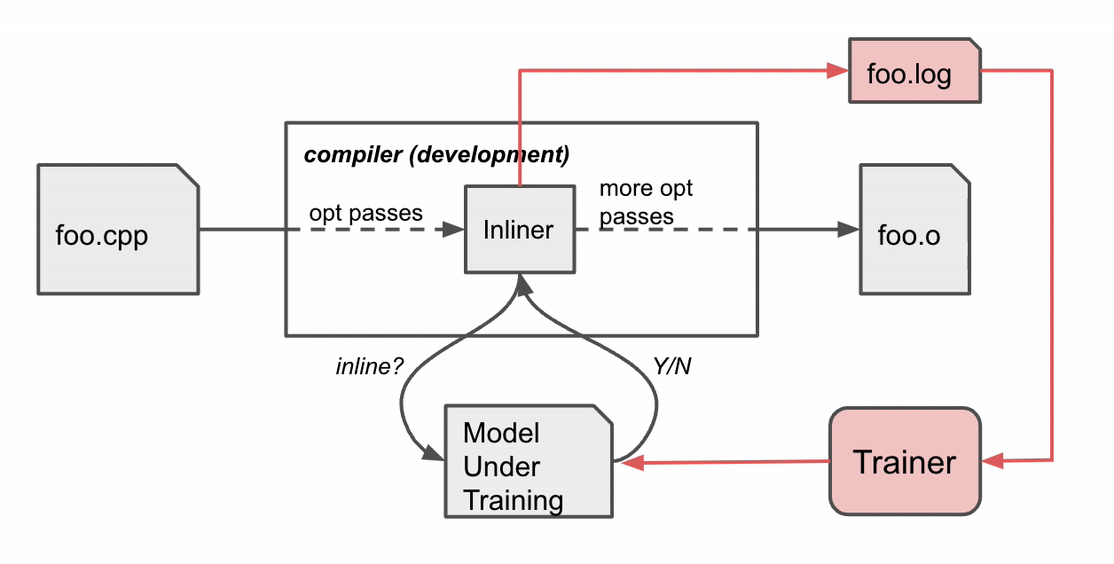 |
Compiler habits throughout coaching. The compiler compiles the supply code foo.cpp to an object file foo.o with a sequence of optimization passes, certainly one of which is the inline move. |
The educated coverage is then embedded into the compiler to offer inline / no-inline selections throughout compilation. In contrast to the coaching state of affairs, the coverage doesn’t produce a log. The TensorFlow mannequin is embedded with XLA AOT, which converts the mannequin into executable code. This avoids TensorFlow runtime dependency and overhead, minimizing the additional time and reminiscence value launched by ML mannequin inference at compilation time.
 |
| Compiler habits in manufacturing. |
We educated the inlining-for-size coverage on a big inner software program package deal containing 30k modules. The educated coverage is generalizable when utilized to compile different software program and achieves a 3% ~ 7% dimension discount. Along with the generalizability throughout software program, generalizability throughout time can be necessary — each the software program and compiler are beneath energetic improvement so the educated coverage must retain good efficiency for an affordable time. We evaluated the mannequin’s efficiency on the identical set of software program three months later and located solely slight degradation.
 |
| Inlining-for-size coverage dimension discount percentages. The x-axis presents completely different software program and the y-axis represents the proportion dimension discount. “Coaching” is the software program on which the mannequin was educated and “Infra[1|2|3]” are completely different inner software program packages. |
The MLGO inlining-for-size coaching has been deployed on Fuchsia — a normal objective open supply working system designed to energy a various ecosystem of {hardware} and software program, the place binary dimension is important. Right here, MLGO confirmed a 6.3% dimension discount for C++ translation models.
Register-Allocation (for efficiency)
As a normal framework, we used MLGO to enhance the register allocation move, which improves the code efficiency in LLVM. Register Allocation solves the issue of assigning bodily registers to dwell ranges (i.e., variables).
Because the code executes, completely different dwell ranges are accomplished at completely different occasions, liberating up registers to be used by subsequent processing levels. Within the instance beneath, every “add” and “multiply” instruction requires all operands and the outcome to be in bodily registers. The dwell vary x is allotted to the inexperienced register and is accomplished earlier than both dwell ranges within the blue or yellow registers. After x is accomplished, the inexperienced register turns into obtainable and is assigned to dwell vary t.
 |
| Register allocation instance. |
When it is time to allocate dwell vary q, there are not any obtainable registers, so the register allocation move should determine which (if any) dwell vary may be “evicted” from its register to make room for q. That is known as the “dwell vary eviction” downside, and is the choice for which we practice the mannequin to interchange unique heuristics. On this explicit instance, it evicts z from the yellow register, and assigns it to q and the primary half of z.
We now contemplate the unassigned second half of dwell vary z. We have now a battle once more, and this time the dwell vary t is evicted and break up, and the primary half of t and the ultimate a part of z find yourself utilizing the inexperienced register. The center a part of z corresponds to the instruction q = t * y, the place z will not be getting used, so it’s not assigned to any register and its worth is saved within the stack from the yellow register, which later will get reloaded to the inexperienced register. The identical occurs to t. This provides further load/retailer directions to the code and degrades efficiency. The purpose of the register allocation algorithm is to cut back such inefficiencies as a lot as doable. That is used because the reward to information RL coverage coaching.
Much like the inlining-for-size coverage, the register allocation (regalloc-for-performance) coverage is educated on a big Google inner software program package deal, and is generalizable throughout completely different software program, with 0.3% ~1.5% enhancements in queries per second (QPS) on a set of inner large-scale datacenter purposes. The QPS enchancment has continued for months after its deployment, exhibiting the mannequin’s generalizability throughout the time horizon.
Conclusion and Future Work
We suggest MLGO, a framework for integrating ML methods systematically in an industrial compiler, LLVM. MLGO is a normal framework that may be expanded to be: 1) deeper, e.g., including extra options, and making use of higher RL algorithms; and a couple of) broader, by making use of it to extra optimization heuristics past inlining and regalloc. We’re enthusiastic in regards to the prospects MLGO can convey to the compiler optimization area and stay up for its additional adoption and to future contributions from the analysis neighborhood.
Strive it Your self
Try the open-sourced end-to-end knowledge assortment and coaching resolution on github and a demo that makes use of coverage gradient to coach an inlining-for-size coverage.
Acknowledgements
We’d prefer to thank MLGO’s contributors and collaborators Eugene Brevdo, Jacob Hegna, Gaurav Jain, David Li, Zinan Lin, Kshiteej Mahajan, Jack Morris, Girish Mururu, Jin Xin Ng, Robert Ormandi, Easwaran Raman, Ondrej Sykora, Maruf Zaber, Weiye Zhao. We’d additionally prefer to thank Petr Hosek, Yuqian Li, Roland McGrath, Haowei Wu for trusting us and deploying MLGO in Fuchsia as MLGO’s very first buyer; thank David Blaikie, Eric Christopher, Brooks Moses, Jordan Rupprecht for serving to to deploy MLGO in Google inner large-scale datacenter purposes; and thank Ed Chi, Tipp Moseley for his or her management help.
[ad_2]