
{kind=link}
[ad_1]
Vector area fashions are to think about the connection between knowledge which can be represented by vectors. It’s standard in data retrieval programs but in addition helpful for different functions. Usually, this permits us to match the similarity of two vectors from a geometrical perspective.
On this tutorial, we are going to see what’s a vector area mannequin and what it will possibly do.
After finishing this tutorial, you’ll know:
- What’s a vector area mannequin and the properties of cosine similarity
- How cosine similarity might help you examine two vectors
- What’s the distinction between cosine similarity and L2 distance
Let’s get began.

A Light Introduction to Vector House Fashions
Picture by liamfletch, some rights reserved.
Tutorial overview
This tutorial is split into 3 components; they’re:
- Vector area and cosine formulation
- Utilizing vector area mannequin for similarity
- Widespread use of vector area fashions and cosine distance
Vector area and cosine formulation
A vector area is a mathematical time period that defines some vector operations. In layman’s time period, we are able to think about it’s a $n$-dimensional metric area the place every level is represented by a $n$-dimensional vector. On this area, we are able to do any vector addition or scalar-vector multiplications.
It’s helpful to think about a vector area as a result of it’s helpful to signify issues as a vector. For instance in machine studying, we often have an information level with a number of options. Due to this fact, it’s handy for us to signify an information level as a vector.
With a vector, we are able to compute its norm. The most typical one is the L2-norm or the size of the vector. With two vectors in the identical vector area, we are able to discover their distinction. Assume it’s a three-d vector area, the 2 vectors are $(x_1, x_2, x_3)$ and $(y_1, y_2, y_3)$. Their distinction is the vector $(y_1-x_1, y_2-x_2, y_3-x_3)$, and the L2-norm of the distinction is the distance or extra exactly the Euclidean distance between these two vectors:
$$
sqrt{(y_1-x_1)^2+(y_2-x_2)^2+(y_3-x_3)^2}
$$
Apart from distance, we are able to additionally think about the angle between two vectors. If we think about the vector $(x_1, x_2, x_3)$ as a line phase from the purpose $(0,0,0)$ to $(x_1,x_2,x_3)$ within the 3D coordinate system, then there’s one other line phase from $(0,0,0)$ to $(y_1,y_2, y_3)$. They make an angle at their intersection:
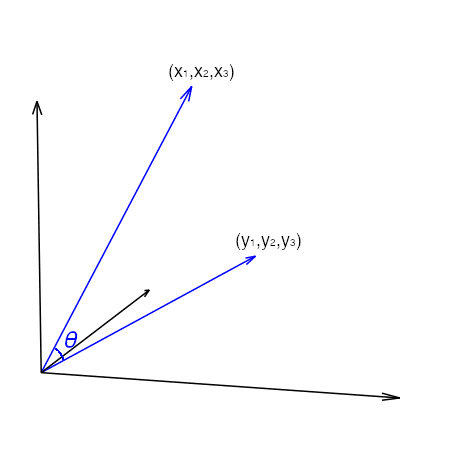
The angle between the 2 line segments could be discovered utilizing the cosine formulation:
$$
cos theta = frac{acdot b} {lVert arVert_2lVert brVert_2}
$$
the place $acdot b$ is the vector dot-product and $lVert arVert_2$ is the L2-norm of vector $a$. This formulation arises from contemplating the dot-product because the projection of vector $a$ onto the course as pointed by vector $b$. The character of cosine tells that, because the angle $theta$ will increase from 0 to 90 levels, cosine decreases from 1 to 0. Generally we’d name $1-costheta$ the cosine distance as a result of it runs from 0 to 1 as the 2 vectors are shifting additional away from one another. This is a crucial property that we’re going to exploit within the vector area mannequin.
Utilizing vector area mannequin for similarity
Let’s have a look at an instance of how the vector area mannequin is helpful.
World Financial institution collects numerous knowledge about international locations and areas on this planet. Whereas each nation is totally different, we are able to attempt to examine international locations underneath vector area mannequin. For comfort, we are going to use the pandas_datareader module in Python to learn knowledge from World Financial institution. Chances are you’ll set up pandas_datareader utilizing pip or conda command:
|
pip set up pandas_datareader |
The info collection collected by World Financial institution are named by an identifier. For instance, “SP.URB.TOTL” is the whole city inhabitants of a rustic. Most of the collection are yearly. Once we obtain a collection, we now have to place within the begin and finish years. Normally the info aren’t up to date on time. Therefore it’s best to have a look at the info a couple of years again slightly than the latest yr to keep away from lacking knowledge.
In beneath, we attempt to gather some financial knowledge of each nation in 2010:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from pandas_datareader import wb import pandas as pd pd.choices.show.width = 0
names = [ “NE.EXP.GNFS.CD”, # Exports of goods and services (current US$) “NE.IMP.GNFS.CD”, # Imports of goods and services (current US$) “NV.AGR.TOTL.CD”, # Agriculture, forestry, and fishing, value added (current US$) “NY.GDP.MKTP.CD”, # GDP (current US$) “NE.RSB.GNFS.CD”, # External balance on goods and services (current US$) ]
df = wb.obtain(nation=“all”, indicator=names, begin=2010, finish=2010).reset_index() international locations = wb.get_countries() non_aggregates = international locations[countries[“region”] != “Aggregates”].title df_nonagg = df[df[“country”].isin(non_aggregates)].dropna() print(df_nonagg) |
|
nation yr NE.EXP.GNFS.CD NE.IMP.GNFS.CD NV.AGR.TOTL.CD NY.GDP.MKTP.CD NE.RSB.GNFS.CD 50 Albania 2010 3.337089e+09 5.792189e+09 2.141580e+09 1.192693e+10 -2.455100e+09 51 Algeria 2010 6.197541e+10 5.065473e+10 1.364852e+10 1.612073e+11 1.132067e+10 54 Angola 2010 5.157282e+10 3.568226e+10 5.179055e+09 8.379950e+10 1.589056e+10 55 Antigua and Barbuda 2010 9.142222e+08 8.415185e+08 1.876296e+07 1.148700e+09 7.270370e+07 56 Argentina 2010 8.020887e+10 6.793793e+10 3.021382e+10 4.236274e+11 1.227093e+10 .. … … … … … … … 259 Venezuela, RB 2010 1.121794e+11 6.922736e+10 2.113513e+10 3.931924e+11 4.295202e+10 260 Vietnam 2010 8.347359e+10 9.299467e+10 2.130649e+10 1.159317e+11 -9.521076e+09 262 West Financial institution and Gaza 2010 1.367300e+09 5.264300e+09 8.716000e+08 9.681500e+09 -3.897000e+09 264 Zambia 2010 7.503513e+09 6.256989e+09 1.909207e+09 2.026556e+10 1.246524e+09 265 Zimbabwe 2010 3.569254e+09 6.440274e+09 1.157187e+09 1.204166e+10 -2.871020e+09
[174 rows x 7 columns] |
Within the above we obtained some financial metrics of every nation in 2010. The perform wb.obtain() will obtain the info from World Financial institution and return a pandas dataframe. Equally wb.get_countries() will get the title of the international locations and areas as recognized by World Financial institution, which we are going to use this to filter out the non-countries aggregates resembling “East Asia” and “World”. Pandas permits filtering rows by boolean indexing, which df["country"].isin(non_aggregates) offers a boolean vector of which row is within the record of non_aggregates and based mostly on that, df[df["country"].isin(non_aggregates)] selects solely these. For numerous causes not all international locations may have all knowledge. Therefore we use dropna() to take away these with lacking knowledge. In follow, we might wish to apply some imputation methods as an alternative of merely eradicating them. However for example, we proceed with the 174 remaining knowledge factors.
To raised illustrate the thought slightly than hiding the precise manipulation in pandas or numpy capabilities, we first extract the info for every nation as a vector:
|
... vectors = {} for rowid, row in df_nonagg.iterrows(): vectors[row[“country”]] = row[names].values
print(vectors) |
|
{‘Albania’: array([3337088824.25553, 5792188899.58985, 2141580308.0144, 11926928505.5231, -2455100075.33431], dtype=object), ‘Algeria’: array([61975405318.205, 50654732073.2396, 13648522571.4516, 161207310515.42, 11320673244.9655], dtype=object), ‘Angola’: array([51572818660.8665, 35682259098.1843, 5179054574.41704, 83799496611.2004, 15890559562.6822], dtype=object), … ‘West Financial institution and Gaza’: array([1367300000.0, 5264300000.0, 871600000.0, 9681500000.0, -3897000000.0], dtype=object), ‘Zambia’: array([7503512538.82554, 6256988597.27752, 1909207437.82702, 20265559483.8548, 1246523941.54802], dtype=object), ‘Zimbabwe’: array([3569254400.0, 6440274000.0, 1157186600.0, 12041655200.0, -2871019600.0], dtype=object)} |
The Python dictionary we created has the title of every nation as a key and the financial metrics as a numpy array. There are 5 metrics, therefore every is a vector of 5 dimensions.
What this helps us is that, we are able to use the vector illustration of every nation to see how related it’s to a different. Let’s strive each the L2-norm of the distinction (the Euclidean distance) and the cosine distance. We choose one nation, resembling Australia, and examine it to all different international locations on the record based mostly on the chosen financial metrics.
|
... import numpy as np
euclid = {} cosine = {} goal = “Australia”
for nation in vectors: vecA = vectors[target] vecB = vectors[country] dist = np.linalg.norm(vecA – vecB) cos = (vecA @ vecB) / (np.linalg.norm(vecA) * np.linalg.norm(vecB)) euclid[country] = dist # Euclidean distance cosine[country] = 1–cos # cosine distance |
Within the for-loop above, we set vecA because the vector of the goal nation (i.e., Australia) and vecB as that of the opposite nation. Then we compute the L2-norm of their distinction because the Euclidean distance between the 2 vectors. We additionally compute the cosine similarity utilizing the formulation and minus it from 1 to get the cosine distance. With greater than 100 international locations, we are able to see which one has the shortest Euclidean distance to Australia:
|
... import pandas as pd
df_distance = pd.DataFrame({“euclid”: euclid, “cos”: cosine}) print(df_distance.sort_values(by=“euclid”).head()) |
|
euclid cos Australia 0.000000e+00 -2.220446e-16 Mexico 1.533802e+11 7.949549e-03 Spain 3.411901e+11 3.057903e-03 Turkey 3.798221e+11 3.502849e-03 Indonesia 4.083531e+11 7.417614e-03 |
By sorting the outcome, we are able to see that Mexico is the closest to Australia underneath Euclidean distance. Nonetheless, with cosine distance, it’s Colombia the closest to Australia.
|
... df_distance.sort_values(by=“cos”).head() |
|
euclid cos Australia 0.000000e+00 -2.220446e-16 Colombia 8.981118e+11 1.720644e-03 Cuba 1.126039e+12 2.483993e-03 Italy 1.088369e+12 2.677707e-03 Argentina 7.572323e+11 2.930187e-03 |
To grasp why the 2 distances give totally different outcome, we are able to observe how the three international locations’ metric examine to one another:
|
... print(df_nonagg[df_nonagg.country.isin([“Mexico”, “Colombia”, “Australia”])]) |
|
nation yr NE.EXP.GNFS.CD NE.IMP.GNFS.CD NV.AGR.TOTL.CD NY.GDP.MKTP.CD NE.RSB.GNFS.CD 59 Australia 2010 2.270501e+11 2.388514e+11 2.518718e+10 1.146138e+12 -1.180129e+10 91 Colombia 2010 4.682683e+10 5.136288e+10 1.812470e+10 2.865631e+11 -4.536047e+09 176 Mexico 2010 3.141423e+11 3.285812e+11 3.405226e+10 1.057801e+12 -1.443887e+10 |
From this desk, we see that the metrics of Australia and Mexico are very shut to one another in magnitude. Nonetheless, in case you examine the ratio of every metric inside the identical nation, it’s Colombia that match Australia higher. In truth from the cosine formulation, we are able to see that
$$
cos theta = frac{acdot b} {lVert arVert_2lVert brVert_2} = frac{a}{lVert arVert_2} cdot frac{b} {lVert brVert_2}
$$
which suggests the cosine of the angle between the 2 vector is the dot-product of the corresponding vectors after they have been normalized to size of 1. Therefore cosine distance is nearly making use of a scaler to the info earlier than computing the gap.
Placing these altogether, the next is the whole code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
from pandas_datareader import wb import numpy as np import pandas as pd pd.choices.show.width = 0
# Obtain knowledge from World Financial institution names = [ “NE.EXP.GNFS.CD”, # Exports of goods and services (current US$) “NE.IMP.GNFS.CD”, # Imports of goods and services (current US$) “NV.AGR.TOTL.CD”, # Agriculture, forestry, and fishing, value added (current US$) “NY.GDP.MKTP.CD”, # GDP (current US$) “NE.RSB.GNFS.CD”, # External balance on goods and services (current US$) ] df = wb.obtain(nation=“all”, indicator=names, begin=2010, finish=2010).reset_index()
# We take away aggregates and hold solely international locations with no lacking knowledge international locations = wb.get_countries() non_aggregates = international locations[countries[“region”] != “Aggregates”].title df_nonagg = df[df[“country”].isin(non_aggregates)].dropna()
# Extract vector for every nation vectors = {} for rowid, row in df_nonagg.iterrows(): vectors[row[“country”]] = row[names].values
# Compute the Euclidean and cosine distances euclid = {} cosine = {}
goal = “Australia” for nation in vectors: vecA = vectors[target] vecB = vectors[country] dist = np.linalg.norm(vecA – vecB) cos = (vecA @ vecB) / (np.linalg.norm(vecA) * np.linalg.norm(vecB)) euclid[country] = dist # Euclidean distance cosine[country] = 1–cos # cosine distance
# Print the outcomes df_distance = pd.DataFrame({“euclid”: euclid, “cos”: cosine}) print(“Closest by Euclidean distance:”) print(df_distance.sort_values(by=“euclid”).head()) print() print(“Closest by Cosine distance:”) print(df_distance.sort_values(by=“cos”).head())
# Print the element metrics print() print(“Element metrics:”) print(df_nonagg[df_nonagg.country.isin([“Mexico”, “Colombia”, “Australia”])]) |
Widespread use of vector area fashions and cosine distance
Vector area fashions are frequent in data retrieval programs. We will current paperwork (e.g., a paragraph, a protracted passage, a ebook, or perhaps a sentence) as vectors. This vector could be so simple as counting of the phrases that the doc accommodates (i.e., a bag-of-word mannequin) or an advanced embedding vector (e.g., Doc2Vec). Then a question to seek out essentially the most related doc could be answered by rating all paperwork by the cosine distance. Cosine distance ought to be used as a result of we don’t wish to favor longer or shorter paperwork, however to deal with what it accommodates. Therefore we leverage the normalization comes with it to think about how related are the paperwork to the question slightly than what number of occasions the phrases on the question are talked about in a doc.
If we think about every phrase in a doc as a function and compute the cosine distance, it’s the “arduous” distance as a result of we don’t care about phrases with related meanings (e.g. “doc” and “passage” have related meanings however not “distance”). Embedding vectors resembling word2vec would enable us to think about the ontology. Computing the cosine distance with the that means of phrases thought-about is the “smooth cosine distance“. Libraries resembling gensim offers a approach to do that.
One other use case of the cosine distance and vector area mannequin is in laptop imaginative and prescient. Think about the duty of recognizing hand gesture, we are able to make sure components of the hand (e.g. 5 fingers) the important thing factors. Then with the (x,y) coordinates of the important thing factors lay out as a vector, we are able to examine with our current database to see which cosine distance is the closest and decide which hand gesture it’s. We want cosine distance as a result of everybody’s hand has a special dimension. We don’t need that to have an effect on our choice on what gesture it’s exhibiting.
As it’s possible you’ll think about, there are far more examples you need to use this method.
Additional studying
This part offers extra sources on the subject in case you are seeking to go deeper.
Books
Software program
Articles
Abstract
On this tutorial, you found the vector area mannequin for measuring the similarities of vectors.
Particularly, you discovered:
- Tips on how to assemble a vector area mannequin
- Tips on how to compute the cosine similarity and therefore the cosine distance between two vectors within the vector area mannequin
- Tips on how to interpret the distinction between cosine distance and different distance metrics resembling Euclidean distance
- What are the usage of the vector area mannequin
Get a Deal with on Linear Algebra for Machine Studying!

Develop a working perceive of linear algebra
…by writing traces of code in python
Uncover how in my new E book:
Linear Algebra for Machine Studying
It offers self-study tutorials on matters like:
Vector Norms, Matrix Multiplication, Tensors, Eigendecomposition, SVD, PCA and far more…
Lastly Perceive the Arithmetic of Information
Skip the Lecturers. Simply Outcomes.
[ad_2]