
{kind=link}
[ad_1]
Feelings are a key side of social interactions, influencing the way in which folks behave and shaping relationships. That is very true with language — with only some phrases, we’re capable of specific all kinds of delicate and sophisticated feelings. As such, it’s been a long-term objective among the many analysis group to allow machines to know context and emotion, which might, in flip, allow a wide range of functions, together with empathetic chatbots, fashions to detect dangerous on-line habits, and improved buyer help interactions.
Prior to now decade, the NLP analysis group has made out there a number of datasets for language-based emotion classification. The vast majority of these are constructed manually and canopy focused domains (information headlines, film subtitles, and even fairy tales) however are usually comparatively small, or focus solely on the six primary feelings (anger, shock, disgust, pleasure, worry, and unhappiness) that had been proposed in 1992. Whereas these emotion datasets enabled preliminary explorations into emotion classification, additionally they highlighted the necessity for a large-scale dataset over a extra intensive set of feelings that would facilitate a broader scope of future potential functions.
In “GoEmotions: A Dataset of Effective-Grained Feelings”, we describe GoEmotions, a human-annotated dataset of 58k Reddit feedback extracted from fashionable English-language subreddits and labeled with 27 emotion classes . As the biggest totally annotated English language fine-grained emotion dataset thus far, we designed the GoEmotions taxonomy with each psychology and information applicability in thoughts. In distinction to the fundamental six feelings, which embrace just one optimistic emotion (pleasure), our taxonomy consists of 12 optimistic, 11 unfavorable, 4 ambiguous emotion classes and 1 “impartial”, making it extensively appropriate for dialog understanding duties that require a delicate differentiation between emotion expressions.
We’re releasing the GoEmotions dataset together with a detailed tutorial that demonstrates the method of coaching a neural mannequin structure (out there on TensorFlow Mannequin Backyard) utilizing GoEmotions and making use of it for the duty of suggesting emojis primarily based on conversational textual content. Within the GoEmotions Mannequin Card we discover further makes use of for fashions constructed with GoEmotions, in addition to issues and limitations for utilizing the information.
 |
| This textual content expresses a number of feelings without delay, together with pleasure, approval and gratitude. |
 |
| This textual content expresses reduction, a posh emotion conveying each optimistic and unfavorable sentiment. |
 |
| This textual content conveys regret, a posh emotion that’s expressed regularly however isn’t captured by easy fashions of emotion. |
Constructing the Dataset
Our objective was to construct a big dataset, centered on conversational information, the place emotion is a important part of the communication. As a result of the Reddit platform presents a big, publicly out there quantity of content material that features direct user-to-user dialog, it’s a worthwhile useful resource for emotion evaluation. So, we constructed GoEmotions utilizing Reddit feedback from 2005 (the beginning of Reddit) to January 2019, sourced from subreddits with not less than 10k feedback, excluding deleted and non-English feedback.
To allow constructing broadly consultant emotion fashions, we utilized information curation measures to make sure the dataset doesn’t reinforce normal, nor emotion-specific, language biases. This was notably essential as a result of Reddit has a identified demographic bias leaning in the direction of younger male customers, which isn’t reflective of a globally various inhabitants. The platform additionally introduces a skew in the direction of poisonous, offensive language. To handle these considerations, we recognized dangerous feedback utilizing predefined phrases for offensive/grownup and vulgar content material, and for identification and faith, which we used for information filtering and masking. We moreover filtered the information to cut back profanity, restrict textual content size, and steadiness for represented feelings and sentiments. To keep away from over-representation of fashionable subreddits and to make sure the feedback additionally replicate much less lively subreddits, we additionally balanced the information amongst subreddit communities.
We created a taxonomy looking for to collectively maximize three targets: (1) present the best protection of the feelings expressed in Reddit information; (2) present the best protection of sorts of emotional expressions; and (3) restrict the general variety of feelings and their overlap. Such a taxonomy permits data-driven fine-grained emotion understanding, whereas additionally addressing potential information sparsity for some feelings.
Establishing the taxonomy was an iterative course of to outline and refine the emotion label classes. In the course of the information labeling levels, we thought-about a complete of 56 emotion classes. From this pattern, we recognized and eliminated feelings that had been scarcely chosen by raters, had low interrater settlement as a result of similarity to different feelings, or had been troublesome to detect from textual content. We additionally added feelings that had been regularly advised by raters and had been effectively represented within the information. Lastly, we refined emotion class names to maximise interpretability, resulting in excessive interrater settlement, with 94% of examples having not less than two raters agreeing on not less than 1 emotion label.
The revealed GoEmotions dataset consists of the taxonomy introduced beneath, and was totally collected by a closing spherical of information labeling the place each the taxonomy and score requirements had been pre-defined and glued.
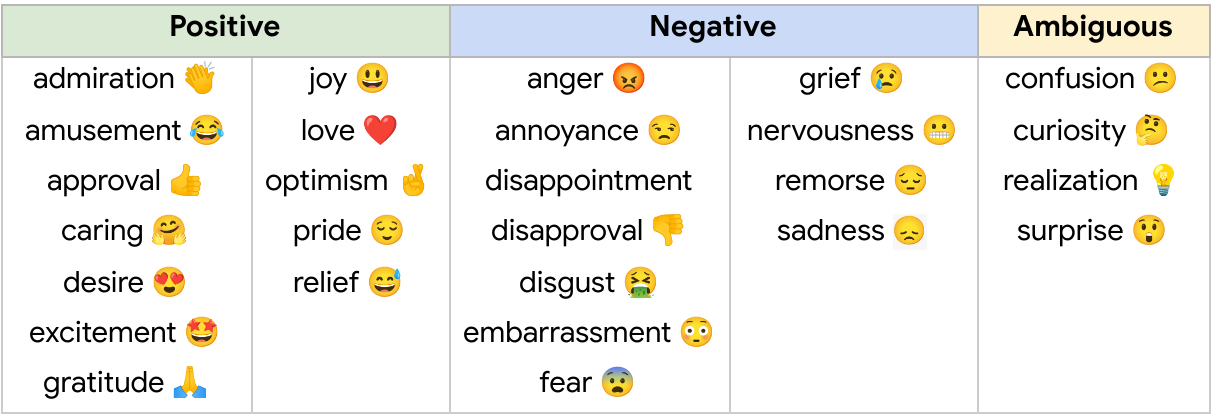 |
| GoEmotions taxonomy: Contains 28 emotion classes, together with “impartial”. |
Knowledge Evaluation and Outcomes
Feelings aren’t distributed uniformly within the GoEmotions dataset. Importantly, the excessive frequency of optimistic feelings reinforces our motivation for a extra various emotion taxonomy than that supplied by the canonical six primary feelings.

To validate that our taxonomic decisions match the underlying information, we conduct principal preserved part evaluation (PPCA), a way used to check two datasets by extracting linear mixtures of emotion judgments that exhibit the best joint variability throughout two units of raters. It subsequently helps us uncover dimensions of emotion which have excessive settlement throughout raters. PPCA was used earlier than to know principal dimensions of emotion recognition in video and speech, and we use it right here to know the principal dimensions of emotion in textual content.
We discover that every part is critical (with p-values < 1.5e-6 for all dimensions), indicating that every emotion captures a novel a part of the information. This isn’t trivial, since in earlier work on emotion recognition in speech, solely 12 out of 30 dimensions of emotion had been discovered to be important.
We look at the clustering of the outlined feelings primarily based on correlations amongst rater judgments. With this strategy, two feelings will cluster collectively when they’re regularly co-selected by raters. We discover that feelings which are associated by way of their sentiment (unfavorable, optimistic and ambiguous) cluster collectively, regardless of no predefined notion of sentiment in our taxonomy, indicating the standard and consistency of the rankings. For instance, if one rater selected “pleasure” as a label for a given remark, it’s extra possible that one other rater would select a correlated sentiment, resembling “pleasure”, slightly than, say, “worry”. Maybe surprisingly, all ambiguous feelings clustered collectively, they usually clustered extra intently with optimistic feelings.

Equally, feelings which are associated by way of their depth, resembling pleasure and pleasure, nervousness and worry, unhappiness and grief, annoyance and anger, are additionally intently correlated.

Our paper gives further analyses and modeling experiments utilizing GoEmotions.
Future Work: Alternate options to Human-Labeling
Whereas GoEmotions presents a big set of human-annotated emotion information, further emotion datasets exist that use heuristics for computerized weak-labeling. The dominant heuristic makes use of emotion-related Twitter tags as emotion classes, which permits one to inexpensively generate giant datasets. However this strategy is proscribed for a number of causes: the language used on Twitter is demonstrably completely different than many different language domains, thus limiting the applicability of the information; tags are human generated, and, when used immediately, are vulnerable to duplication, overlap, and different taxonomic inconsistencies; and the specificity of this strategy to Twitter limits its functions to different language corpora.
We suggest another, and extra simply out there heuristic through which emojis embedded in person dialog function a proxy for emotion classes. This strategy may be utilized to any language corpora containing an inexpensive occurence of emojis, together with many which are conversational. As a result of emojis are extra standardized and fewer sparse than Twitter-tags, they current fewer inconsistencies.
Notice that each of the proposed approaches — utilizing Twitter tags and utilizing emojis — aren’t immediately geared toward emotion understanding, however slightly at variants of conversational expression. For instance, within the dialog beneath, 🙏 conveys gratitude, 🎂 conveys a celebratory expression, and 🎁 is a literal alternative for ‘current’. Equally, whereas many emojis are related to emotion-related expressions, feelings are delicate and multi-faceted, and in lots of instances nobody emoji can actually seize the complete complexity of an emotion. Furthermore, emojis seize various expressions past feelings. For these causes, we contemplate them as expressions slightly than feelings.

Any such information may be worthwhile for constructing expressive conversational brokers, in addition to for suggesting contextual emojis, and is a very fascinating space of future work.
Conclusion
The GoEmotions dataset gives a big, manually annotated, dataset for fine-grained emotion prediction. Our evaluation demonstrates the reliability of the annotations and excessive protection of the feelings expressed in Reddit feedback. We hope that GoEmotions will likely be a worthwhile useful resource to language-based emotion researchers, and can permit practitioners to construct inventive emotion-driven functions, addressing a variety of person feelings.
Acknowledgements
This weblog presents analysis achieved by Dora Demszky (whereas interning at Google), Dana Alon (beforehand Movshovitz-Attias), Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. We thank Peter Younger for his infrastructure and open sourcing contributions. We thank Erik Vee, Ravi Kumar, Andrew Tomkins, Patrick Mcgregor, and the Learn2Compress group for help and sponsorship of this analysis undertaking.
[ad_2]