

{kind=link}
[ad_1]
Genomic applied sciences are driving the creation of latest therapeutics, from RNA vaccines to gene enhancing and diagnostics. Progress in these areas motivated us to construct Glow, an open-source toolkit for genomics machine studying and knowledge analytics. The toolkit is natively constructed on Apache Spark™, the main engine for giant knowledge processing, enabling population-scale genomics.
The undertaking began as an business collaboration between Databricks and the Regeneron Genetics Heart. The purpose is to advance analysis by constructing the following technology of genomics knowledge evaluation instruments for the neighborhood. We took inspiration from bioinformatics libraries comparable to Hail, Plink and bedtools, married with best-in-class strategies for large-scale knowledge processing. Glow is now 10x extra computationally environment friendly than business main instruments for genetic affiliation research..
The imaginative and prescient for Glow and genomic evaluation at scale
The first bottleneck slowing the expansion in genomics is the complexity of knowledge administration and analytics. Our purpose is to make it easy for knowledge engineers and knowledge scientists who usually are not skilled in bioinformatics to contribute to genomics knowledge processing in distributed cloud computing environments. Easing this bottleneck will in flip drive up the demand for extra sequencing knowledge in a optimistic suggestions loop.
When to make use of Glow
Glow’s area of applicability falls in aggregation and mining of genetic variant knowledge. Significantly for knowledge analyses which might be run many occasions iteratively or that take quite a lot of hours to finish, comparable to:
- Annotation pipelines
- Genetic affiliation research
- GPU-based deep studying algorithms
- Reworking knowledge into and out of bioinformatics instruments.
For instance, Glow features a distributed implementation of the Regenie technique. You may run Regenie on a single node, which is advisable for educational scientists. However for industrial purposes, Glow is the world’s most price efficient and scalable technique of operating hundreds of affiliation assessments. Let’s stroll by how this works.
Benchmarking Glow towards Hail
We targeted on genetic affiliation research for benchmarks as a result of they’re probably the most computationally intensive steps in any analytics pipeline. Glow is >10x extra performant for Firth regression relative to Hail with out buying and selling off accuracy (Determine 1). We have been in a position to obtain this efficiency as a result of we apply an approximate technique first, proscribing the total technique to variants with a suggestive affiliation with illness (P Glow documentation.
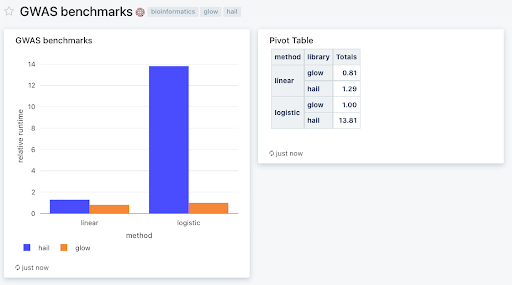
Determine 1: Databricks SQL dashboard exhibiting Glow and Hail benchmarks on a simulated dataset of 500k samples, and 250k variants (1% of UK Biobank scale) run throughout a 768 core cluster with 48 memory-optimized digital machines. We used Glow v1.1.0 and Hail v0.2.76. Relative runtimes are proven. To breed these benchmarks, please obtain the notebooks from the Glow Github repository and use the related docker containers to arrange the surroundings.
Glow on the Databricks Lakehouse Platform
We had a small crew of engineers engaged on a decent schedule to develop Glow. So how have been we in a position to meet up with the world’s main biomedical analysis institute, the mind energy behind Hail? We did it by creating Glow on the Databricks Lakehouse Platform in collaboration with business companions. Databricks supplies infrastructure that makes you productive with genomics knowledge analytics. For instance, you need to use Databricks Jobs to construct advanced pipelines with a number of dependencies (Determine 2).
Moreover, Databricks is a safe platform trusted by each Fortune 100 and healthcare organizations with their most delicate knowledge, adhering to ideas of knowledge governance (FAIR), safety and compliance (HIPAA and GDPR).

Determine 2: Glow on the Databricks Lakehouse Platform
What lies in retailer for the long run?
Glow is now at a v1 stage of maturity, and we need to the neighborhood to assist contribute to construct and lengthen it. There’s a number of thrilling issues in retailer.
Genomics datasets are so massive that batch processing with Apache Spark can hit capability limits of sure cloud areas. This drawback shall be solved by the open Delta Lake format, which unifies batch and stream processing. By leveraging streaming, Delta Lake allows incremental processing of latest samples or variants, with edge circumstances quarantined for additional evaluation. Combining Glow with Delta Lake will clear up the “n+1 drawback” in genomics.
An extra drawback in genomics analysis is knowledge explosion. There are over 50 copies of the Most cancers Genome Atlas on Amazon Internet Companies alone. The answer proposed right this moment is a walled backyard, managing datasets inside genomics area platforms. This solves knowledge duplication, however then locks knowledge into platforms.
This friction shall be eased by Delta Sharing, an open protocol for safe real-time trade of enormous datasets, which can allow safe knowledge sharing between organizations, clouds and area platforms. Unity Catalog will then make it simple to find, audit and govern these knowledge property.
We’re simply firstly of the industrialization of genomics knowledge analytics. To be taught extra, please see the Glow documentation, tech talks on YouTube, and workshops.
[ad_2]