
{kind=link}
[ad_1]
Amazon QuickSight is a scalable enterprise intelligence (BI) service constructed for the cloud, which permits insights to be shared with all customers within the group. QuickSight affords SPICE, an in-memory, cloud-native knowledge retailer that enables end-users to interactively discover knowledge. SPICE supplies constantly quick question efficiency and robotically scales for prime concurrency. With SPICE, you save time and value since you don’t must retrieve knowledge from the information supply (whether or not a database or knowledge warehouse) each time you modify an evaluation or replace a visible, and also you take away the load of concurrent entry or analytical complexity off the underlying knowledge supply with the information.
At this time, we’re introducing incremental refresh in SPICE, with a refresh charge of quarter-hour (4 occasions quicker than earlier than), which improves freshness of information in SPICE. As well as, we’re doubling SPICE limits on a per dataset foundation to 500 million rows (twice that of our earlier 250 million row restrict). On this submit, we stroll by these new capabilities and the way you need to use them to create SPICE datasets that may show you how to scale your knowledge to all of your customers.
What’s new with QuickSight SPICE?
We’ve added the next capabilities to QuickSight:
- Incremental refresh – QuickSight now helps incrementally loading new knowledge to SPICE datasets without having to refresh the total set of information. With incremental refresh, you’ll be able to replace SPICE datasets in a fraction of the time a full refresh would take, enabling entry to the newest insights a lot sooner. You may schedule incremental refresh to run as much as each quarter-hour on a dataset on SQL-based knowledge sources, akin to Amazon Redshift, Amazon Athena, PostgreSQL, Microsoft SQL Server, or Snowflake.
- 500 million row SPICE capability – The QuickSight SPICE engine now helps datasets as much as 500 million rows or 500 GB in measurement. This variation permits you to use SPICE for datasets twice as giant than earlier than.
Within the subsequent sections, we present you the right way to get began with incremental refresh and 500 million row SPICE capability.
Create giant datasets
Let’s say you’re a part of the central knowledge crew that has entry to knowledge tables in knowledge sources. You wish to create a central dataset for analysts. SPICE can now scale to double the capability, so you’ll be able to create a big scaled dataset slightly than create and preserve a number of unconnected datasets. You may herald as much as 32 tables (from totally different knowledge sources) in a single dataset to a complete of 500 million rows. You may benefit from the double capability of SPICE with no additional step—it’s robotically out there. To create a dataset, merely select New Dataset on the Knowledge web page. On the Knowledge Prep web page for the brand new dataset, select Add knowledge so as to add tables to a single dataset.

Arrange incremental refresh
With incremental refresh, QuickSight now permits you to ingest knowledge incrementally on your SQL-based sources (akin to Amazon Redshift, Athena, PostgreSQL, or Snowflake) in a specified time interval. On the Datasets web page, select the dataset, and select Refresh now or Schedule a refresh.
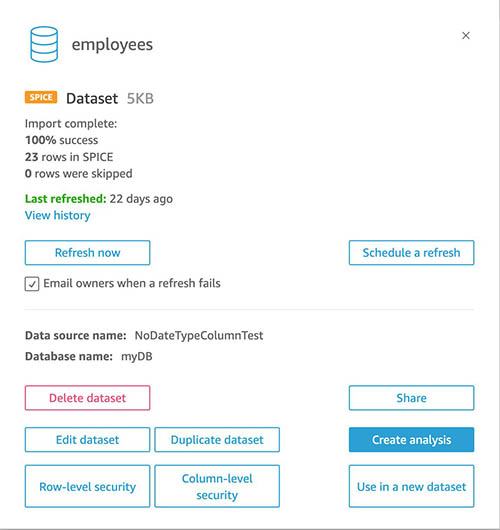
For Refresh sort, choose Incremental refresh.
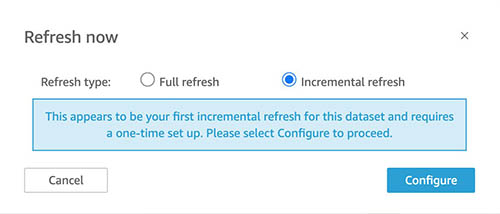
Configure look-back window
Whereas organising incremental refresh, you need to specify a look-back window (for instance, 1 day, 1 week, 6 hours) wherein new rows are discovered, and modified and deleted rows sync. Because of this much less knowledge must be queried and transferred for every refresh, thereby rising the pace at which ingestions can full.
Let’s stroll by an instance as an instance the idea. We now have a dataset that comprises 6 months’ value of gross sales data: 180,000 data (1,000 data per day). Proper now, the dataset comprises knowledge from January 1 to June 30, and at present is July 1. I run an incremental refresh with a look-back window of seven days. QuickSight queries the database asking for all knowledge since June 24 (7 days in the past): 7,000 data. All of the modifications since June 24, together with deleted, up to date, and added knowledge, are propagated into SPICE. The subsequent day, July 2, QuickSight does the identical, however querying from June 25 (7,000 data). The top result’s that slightly than having to ingest 180,000 data on daily basis, you solely must course of 7,000 data.
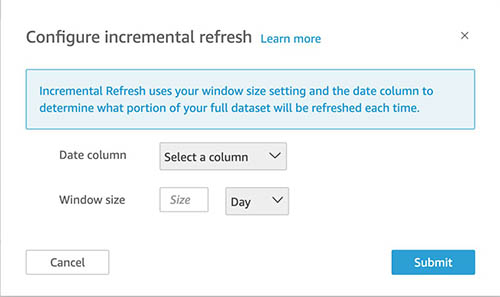
You may arrange a look-back window as a part of organising your incremental refresh. After you choose Incremental refresh from the steps within the previous part, select Configure.
You may select all eligible date columns to make use of for look-back and the window measurement, which QuickSight makes use of to question for that vary. Then select Submit.
Schedule an incremental refresh
A scheduled SQL incremental refresh permits you to usually ingest knowledge from an information supply to SPICE, incrementally. To arrange a scheduled SQL incremental refresh, just like handbook incremental refresh, if it is a first-time setup, you’re prompted to arrange a look-back window. After configuration, select the time zone, repetition interval, and beginning time and select Create.
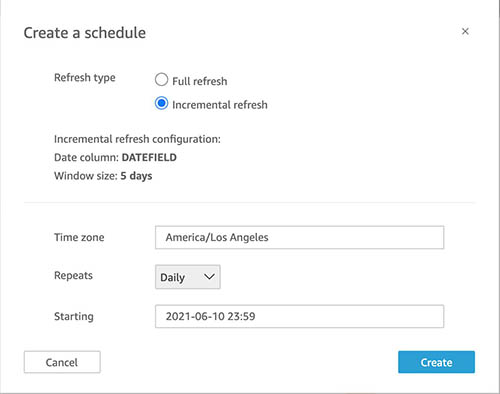
The scheduled refresh begins on the time you specified.
Arrange full ingestion
Beforehand, for SPICE datasets, the one replace mechanism in QuickSight was a full refresh. All the information outlined by the dataset was queried and transferred into the dataset from its supply, totally changing what beforehand existed. With incremental refresh, you’ll be able to replace your knowledge each quarter-hour. Nonetheless, we nonetheless advocate a full refresh to verify your dataset is in sync with the supply. You may arrange a full ingestion each week on a weekend to not disrupt any enterprise workflows.
Conclusion
With incremental refresh and double SPICE capability, QuickSight lets you create datasets to cater to your scaling enterprise wants within the following methods:
- Quicker and dependable refreshes – Incremental refreshes are quicker as a result of solely the newest knowledge must be refreshed and never your entire dataset. Moreover, the refreshes are additionally extra dependable since you don’t must spend time on long-running queries or any potential community disruptions.
- Giant datasets – SPICE can now scale as much as 500 million rows, however you don’t must spend time updating, as a result of you’ll be able to replace incrementally and don’t must refresh your entire dataset.
- Simple setup with fewer sources – With incremental refresh, you’ve much less knowledge to refresh. This reduces total consumption of sources wanted. The setup course of can be a lot less complicated with scheduled incremental refresh.
QuickSight’s SPICE incremental refresh and 500 million row SPICE capability may help you create scalable and dependable datasets with out placing a pressure on underlying knowledge sources. These options are actually usually out there in QuickSight Enterprise Editions in all Areas. Go forward and check out it out! To be taught extra about refreshing knowledge in QuickSight, see Refreshing Knowledge.
Concerning the Authors
 Shailesh Chauhan is a Product Supervisor at Amazon QuickSight, AWS’ cloud-native, totally managed BI service. Earlier than QuickSight, Shailesh was world product lead at Uber for all knowledge purposes constructed from ground-up. Earlier, he was a founding crew member at ThoughtSpot, the place he created world’s first analytics search engine. Shailesh is captivated with constructing significant and impactful merchandise from scratch. He appears ahead to serving to prospects whereas working with individuals with nice thoughts and massive coronary heart.
Shailesh Chauhan is a Product Supervisor at Amazon QuickSight, AWS’ cloud-native, totally managed BI service. Earlier than QuickSight, Shailesh was world product lead at Uber for all knowledge purposes constructed from ground-up. Earlier, he was a founding crew member at ThoughtSpot, the place he created world’s first analytics search engine. Shailesh is captivated with constructing significant and impactful merchandise from scratch. He appears ahead to serving to prospects whereas working with individuals with nice thoughts and massive coronary heart.
 Anilkumar Senesetti is a Software program Improvement Supervisor at AWS QuickSight. He leads the Knowledge Ingestion (DI) crew that delivers options to speed up ingestion of consumers knowledge into SPICE making certain correctness, sturdiness, consistency and safety of the information. With 15 years of trade expertise in enterprise intelligence area, he supplies invaluable insights throughout layers to ship options that enhance buyer expertise. He’s captivated with predictive analytics and outdoors of the work, he enjoys constructing options on astrological web site that he owns.
Anilkumar Senesetti is a Software program Improvement Supervisor at AWS QuickSight. He leads the Knowledge Ingestion (DI) crew that delivers options to speed up ingestion of consumers knowledge into SPICE making certain correctness, sturdiness, consistency and safety of the information. With 15 years of trade expertise in enterprise intelligence area, he supplies invaluable insights throughout layers to ship options that enhance buyer expertise. He’s captivated with predictive analytics and outdoors of the work, he enjoys constructing options on astrological web site that he owns.
[ad_2]