
{kind=link}
[ad_1]
This put up was co-written with Alcuin Weidus, Principal Architect from GE Aviation.
GE Aviation, an working unit of GE, is a world-leading supplier of jet and turboprop engines, in addition to built-in programs for industrial, army, enterprise, and common aviation plane. GE Aviation has a world service community to help these choices.
From the turbosupercharger to the world’s strongest industrial jet engine, GE’s historical past of powering the world’s plane options greater than 90 years of innovation.
On this put up, we share how GE Aviation constructed cloud-native knowledge pipelines at enterprise scale utilizing the AWS platform.
A give attention to the muse
At GE Aviation, we’ve been invested within the knowledge area for a few years. Witnessing the client worth and enterprise insights that might be extracted from knowledge at scale has propelled us ahead. We’re all the time searching for new methods to evolve, develop, and modernize our knowledge and analytics stack. In 2019, this meant transferring from a standard on-premises knowledge footprint (with some specialised AWS use circumstances) to a totally AWS Cloud-native design. We understood the duty was difficult, however we had been dedicated to its success. We noticed the large potential in AWS, and had been desperate to companion carefully with an organization that has over a decade of cloud expertise.
Our objective from the outset was clear: construct an enterprise-scale knowledge platform to speed up and join the enterprise. Utilizing the perfect of cloud expertise would set us as much as ship on our objective and prioritize efficiency and reliability within the course of. From an early level within the construct, we knew that if we needed to realize true scale, we needed to begin with stable foundations. This meant first specializing in our knowledge pipelines and storage layer, which function the ingest level for tons of of supply programs. Our workforce selected Amazon Easy Storage Service (Amazon S3) as our foundational knowledge lake storage platform.
Amazon S3 was the primary selection because it gives an optimum basis for a knowledge lake retailer delivering nearly limitless scalability and 11 9s of sturdiness. Along with its scalable efficiency, it has ease-of-use options, native encryption, and entry management capabilities. Equally vital, Amazon S3 integrates with a broad portfolio of AWS companies, akin to Amazon Athena, the AWS Glue Information Catalog, AWS Glue ETL (extract, remodel, and cargo) Amazon Redshift, Amazon Redshift Spectrum, and lots of third-party instruments, offering a rising ecosystem of knowledge administration instruments.
How we began
The journey began with an inside hackathon that introduced cross-functional workforce members collectively. We organized round an preliminary design and established an structure to begin the construct utilizing serverless patterns. A mix of Amazon S3, AWS Glue ETL, and the Information Catalog had been central to our resolution. These three companies particularly aligned to our broader technique to be serverless wherever attainable and construct on prime of AWS companies that had been experiencing heavy innovation in the best way of recent options.
We felt good about our strategy and promptly started working.
Resolution overview
Our cloud knowledge platform constructed on Amazon S3 is fed from a mixture of enterprise ELT programs. We now have an on-premises system that handles change knowledge seize (CDC) workloads and one other that works extra in a standard batch method.
Our design has the on-premises ELT programs dropping information into an S3 bucket set as much as obtain uncooked knowledge for each conditions. We made the choice to standardize our processed knowledge layer into Apache Parquet format for our cataloged S3 knowledge lake in preparation for extra environment friendly serverless consumption.
Our enterprise CDC system can already land information natively in Parquet; nonetheless, our batch information are restricted to CSV, so the touchdown of CSV information triggers one other serverless course of to transform these information to Parquet utilizing AWS Glue ETL.
The next diagram illustrates this workflow.
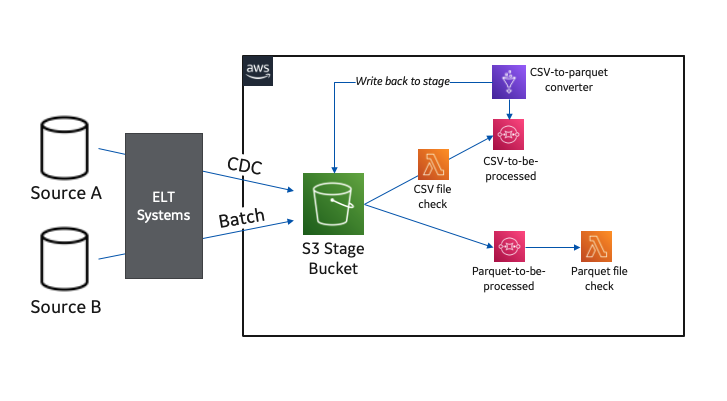
When uncooked knowledge is current and prepared in Apache Parquet format, now we have an event-triggered resolution that processes the information and masses it to a different mirror S3 bucket (that is the place our customers entry and devour the information).
Pipelines are developed to help loading at a desk degree. We now have particular AWS Lambda capabilities to determine schema errors by evaluating every file’s schema in opposition to the final profitable run. One other perform validates {that a} essential main key file is current for any CDC tables.
Information partitioning and CDC updates
When our preprocessing Lambda capabilities are full, the information are processed in one among two distinct paths based mostly on the desk sort. Batch desk masses are by far the easier of the 2 and are dealt with by way of a single Lambda perform.
For CDC tables, we use AWS Glue ETL to load and carry out the updates in opposition to our tables saved within the mirror S3 bucket. The AWS Glue job makes use of Apache Spark knowledge frames to mix historic knowledge, filter out deleted information, and union with any information inserted. For our course of, updates are handled as delete-then-insert. After performing the union, the whole dataset is written out to the mirror S3 bucket in a newly created bucket partition.
The next diagram illustrates this workflow.

We write knowledge into a brand new partition for every desk load, so we will present learn consistency in a approach that is sensible to our consuming enterprise companions.
Constructing the Information Catalog
When every Amazon S3 mirror knowledge load is full, one other separate serverless department is triggered to deal with catalog administration.
The department updates the placement property inside the catalog for pre-existing tables, indicating every newly added partition. When loading a desk for the primary time, we set off a collection of purpose-built Lambda capabilities to create the AWS Glue Information Catalog database (solely required when it’s a wholly new supply schema), create an AWS Glue crawler, begin the crawler, and delete the crawler when it’s full.
The next diagram illustrates this workflow.

These event-driven design patterns permit us to completely automate the catalog administration piece of our structure, which grew to become an enormous win for our workforce as a result of it lowered the operational overhead related to onboarding new supply tables. Each achievement like this mattered as a result of it realized the potential the cloud needed to remodel how we construct and help merchandise throughout our expertise group.
Ultimate implementation structure and greatest practices
The answer developed a number of occasions all through the event cycle, usually because of studying one thing new by way of serverless and cloud-native growth, and additional working with AWS Options Architect and AWS Skilled Providers groups. Alongside the best way, we’ve found many cloud-native greatest practices and accelerated our serverless knowledge journey to AWS.
The next diagram illustrates our closing structure.

We strategically added Amazon Easy Queue Service (Amazon SQS) between purpose-built Lambda capabilities to decouple the structure. Amazon SQS gave our system a degree of resiliency and operational observability that in any other case would have been a problem.
One other greatest apply arose from utilizing Amazon DynamoDB as a state desk to assist guarantee our total serverless integration sample was writing to our mirror bucket with ACID ensures.
On the subject of operational observability, we use Amazon EventBridge to seize and report on operational metadata like desk load standing, time of the final load, and row counts.
Bringing all of it collectively
On the time of writing, we’ve had manufacturing workloads operating via our resolution for the higher a part of 14 months.
Manufacturing knowledge is built-in from greater than 30 supply programs at current and totals a number of hundred tables. This resolution has given us an awesome start line for constructing our cloud knowledge ecosystem. The pliability and extensibility of AWS’s many companies have been key to our success.
Appreciation for the AWS Glue Information Catalog has been a vital factor. With out understanding it on the time we began constructing a knowledge lake, we’ve been embracing a contemporary knowledge structure sample and organizing round our transactionally constant and cataloged mirror storage layer.
The introduction of a extra seamless Apache Hudi expertise inside AWS has been an enormous win for our workforce. We’ve been busy incorporating Hudi into our CDC transaction pipeline and are thrilled with the outcomes. We’re capable of spend much less time writing code managing the storage of our knowledge, and extra time specializing in the reliability of our system. This has been vital in our capacity to scale. Our growth pipeline has grown past 10,000 tables and greater than 150 supply programs as we strategy one other main manufacturing cutover.
Trying forward, we’re intrigued by the potential for AWS Lake Formation goverened tables to additional speed up our momentum and administration of CDC desk masses.
Conclusion
Constructing our cloud-native integration pipeline has been a journey. What began as an thought and has became way more in a short time. It’s exhausting to understand how far we’ve come when there’s all the time extra to be executed. That being stated, the whole course of has been extraordinary. We constructed deep and trusted partnerships with AWS, realized extra about our inside worth assertion, and aligned extra of our group to a cloud-centric approach of working.
The power to construct options in a serverless method opens up many doorways for our knowledge perform and, most significantly, our prospects. Velocity to supply and the tempo of innovation is instantly associated to our capacity to focus our engineering groups on business-specific issues whereas trusting a companion like AWS to do the heavy lifting of knowledge heart operations like racking, stacking, and powering servers. It additionally removes the operational burden of managing working programs and functions with managed companies. Lastly, it permits us to give attention to our prospects and enterprise course of enablement somewhat than on IT infrastructure.
The breadth and depth of knowledge and analytics companies on AWS make it attainable to unravel our enterprise issues through the use of the precise assets to run no matter evaluation is most acceptable for a particular want. AWS Information and Analytics has deep integrations throughout all layers of the AWS ecosystem, giving us the instruments to investigate knowledge utilizing any strategy shortly. We respect AWS’s continuous innovation on behalf of its prospects.
Concerning the Authors
 Alcuin Weidus is a Principal Information Architect for GE Aviation. Serverless advocate, perpetual knowledge administration pupil, and cloud native strategist, Alcuin is a knowledge expertise chief on a workforce chargeable for accelerating technical outcomes throughout GE Aviation. Join him on Linkedin.
Alcuin Weidus is a Principal Information Architect for GE Aviation. Serverless advocate, perpetual knowledge administration pupil, and cloud native strategist, Alcuin is a knowledge expertise chief on a workforce chargeable for accelerating technical outcomes throughout GE Aviation. Join him on Linkedin.
 Suresh Patnam is a Sr Options Architect at AWS; He works with prospects to construct IT technique, making digital transformation via the cloud extra accessible, specializing in huge knowledge, knowledge lakes, and AI/ML. In his spare time, Suresh enjoys taking part in tennis and spending time along with his household. Join him on LinkedIn.
Suresh Patnam is a Sr Options Architect at AWS; He works with prospects to construct IT technique, making digital transformation via the cloud extra accessible, specializing in huge knowledge, knowledge lakes, and AI/ML. In his spare time, Suresh enjoys taking part in tennis and spending time along with his household. Join him on LinkedIn.
[ad_2]