
{kind=link}
[ad_1]
This publish is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics.
Cynamics offers a brand new paradigm of cybersecurity — predicting assaults lengthy earlier than they hit by accumulating small community samples (lower than 1%), inferring from them how the complete community (100%) behaves, and predicting threats utilizing distinctive AI breakthroughs. The pattern strategy permits Cynamics to be generic, agnostic, and work for any shopper’s community structure, regardless of how messy the combo between legacy, personal, and public clouds. Moreover, the answer is scalable and offers full cowl to the shopper’s community, regardless of how giant it’s in quantity and dimension. Furthermore, as a result of any community gateway (bodily or digital, legacy or cloud) helps one of many customary sampling protocols and APIs, Cynamics doesn’t require any set up of home equipment nor brokers, in addition to no community modifications and modifications, and the onboarding often takes lower than an hour.
Within the crowded cybersecurity market, Cynamics is the first-ever answer based mostly on small community samples, which has been thought of a tough and unsolved problem in academia (our educational paper “Community anomaly detection utilizing switch studying based mostly on auto-encoders loss normalization” was lately introduced in ACM CCS AISec 2021) and business to today.
The issue Cynamics confronted
Early within the course of, with the expansion of our buyer base, we have been required to seamlessly help the elevated scale and community throughput by our distinctive AI algorithms. We confronted a number of completely different challenges:
- How can we carry out near-real-time evaluation on our streaming purchasers’ incoming knowledge into our AI inference system to foretell threats and assaults?
- How can we seamlessly auto scale our answer to be cost-efficient with no influence on the platform ingestion price?
- As a result of a lot of our clients are from the general public sector, how can we do that whereas supporting each AWS business and authorities environments (GovCloud)?
This publish exhibits how we used AWS managed providers and specifically Amazon Kinesis Information Streams and Amazon EMR to construct a near-real-time streaming AI inference system serving lots of of manufacturing clients in each AWS business and authorities environments, whereas seamlessly auto scaling.
Overview of answer
The next diagram illustrates our answer structure:
To offer a cost-efficient, extremely accessible answer that scales simply with consumer development, whereas having no influence on near-real-time efficiency, we turned to Amazon EMR.
We presently course of over 50 million information per day, which interprets to simply over 5 billion flows, and retains rising every day. Utilizing Amazon EMR together with Kinesis Information Streams supplied the scalability we wanted to attain inference instances of only a few seconds.
Though this know-how was new to us, we minimized our studying curve by turning to the accessible guides from AWS for finest practices on scale, partitioning, and useful resource administration.
Workflow
Our workflow incorporates the next steps:
- Circulate samples are despatched by the shopper’s community gadgets on to the Cynamics cloud. A community movement (or connection) is a set of packets with the identical five-tuple ID:
source-IP-address,destination-IP-address,source-port,destination-port, andprotocol. - The samples are analyzed by Community Load Balancers, which ahead them into an auto scaling group of stateless movement transformers operating on Graviton-powered Amazon Elastic Compute Cloud (Amazon EC2) situations. With Graviton-based processors within the movement transformers, we lowered our operational prices by over 30%.
- The flows are reworked to the Cynamics knowledge format and enriched with further info from Cynamics’ databases and in-house sources resembling IP resolutions, intelligence, and status.
The next figures present the community scale for a single movement transformer machine over every week. The primary determine illustrates incoming community packets for a single movement transformer machine.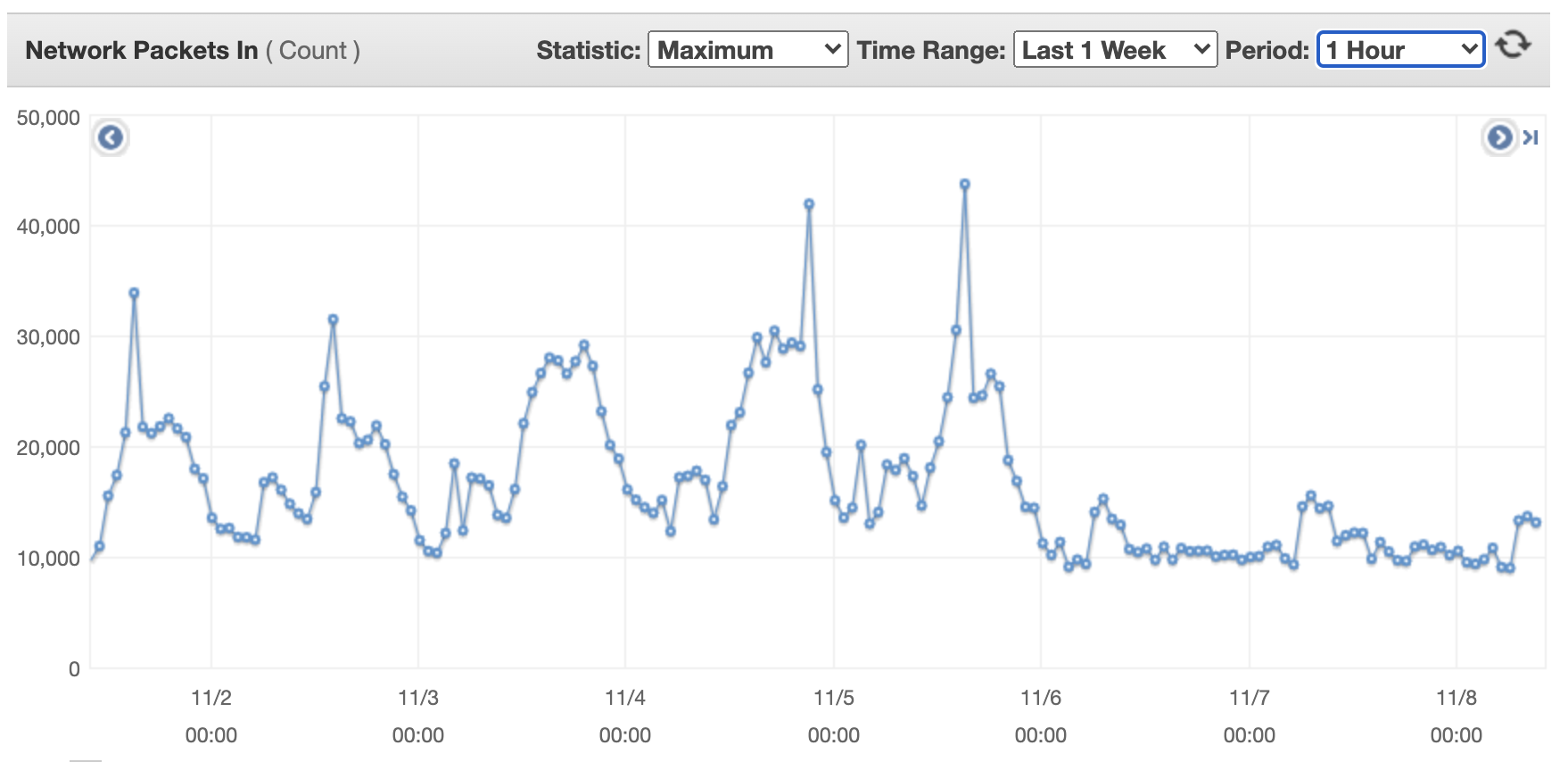
The next exhibits outcoming community packets for a single movement transformer machine.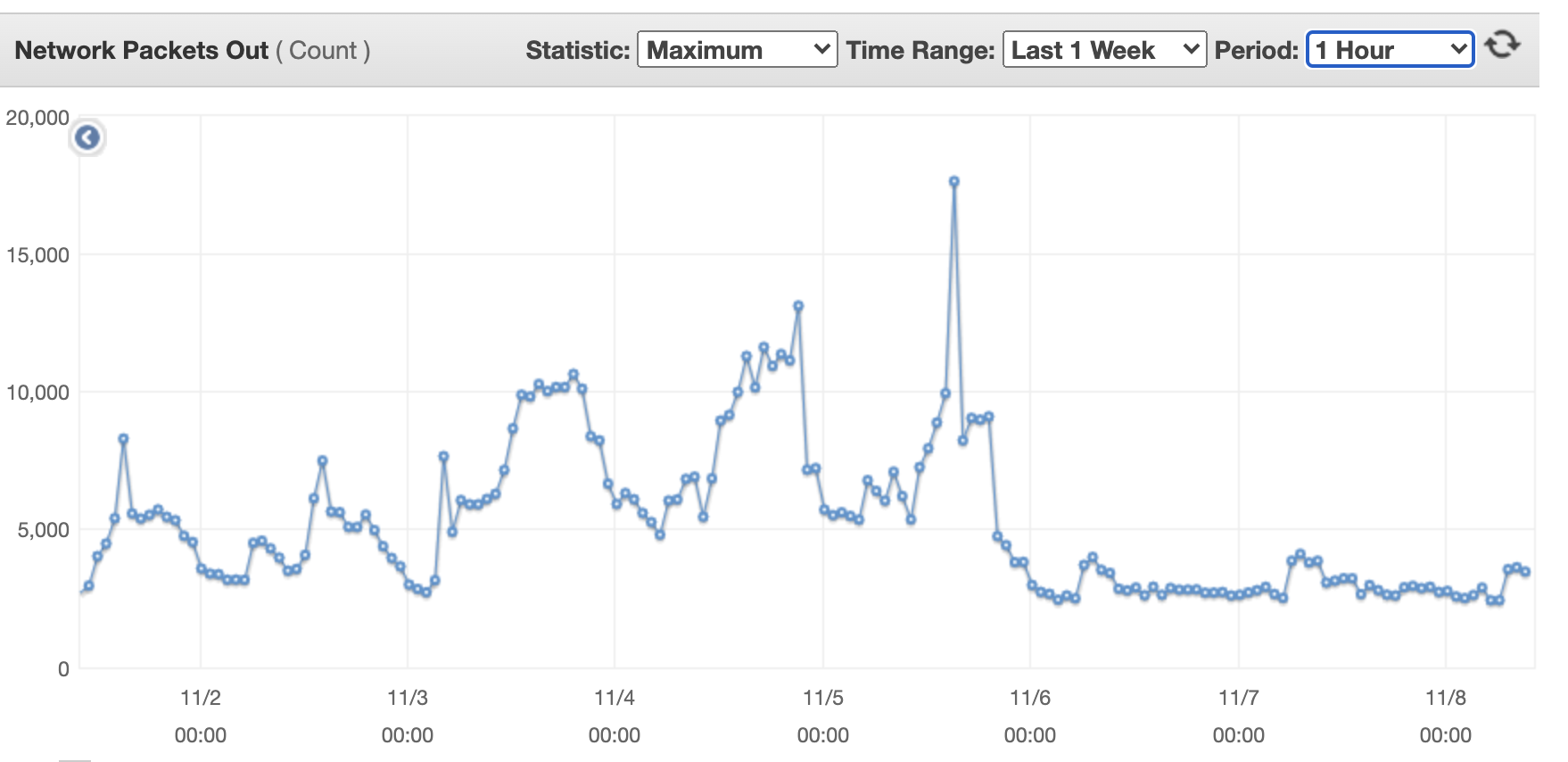
The next exhibits incoming community bytes for a single movement transformer machine.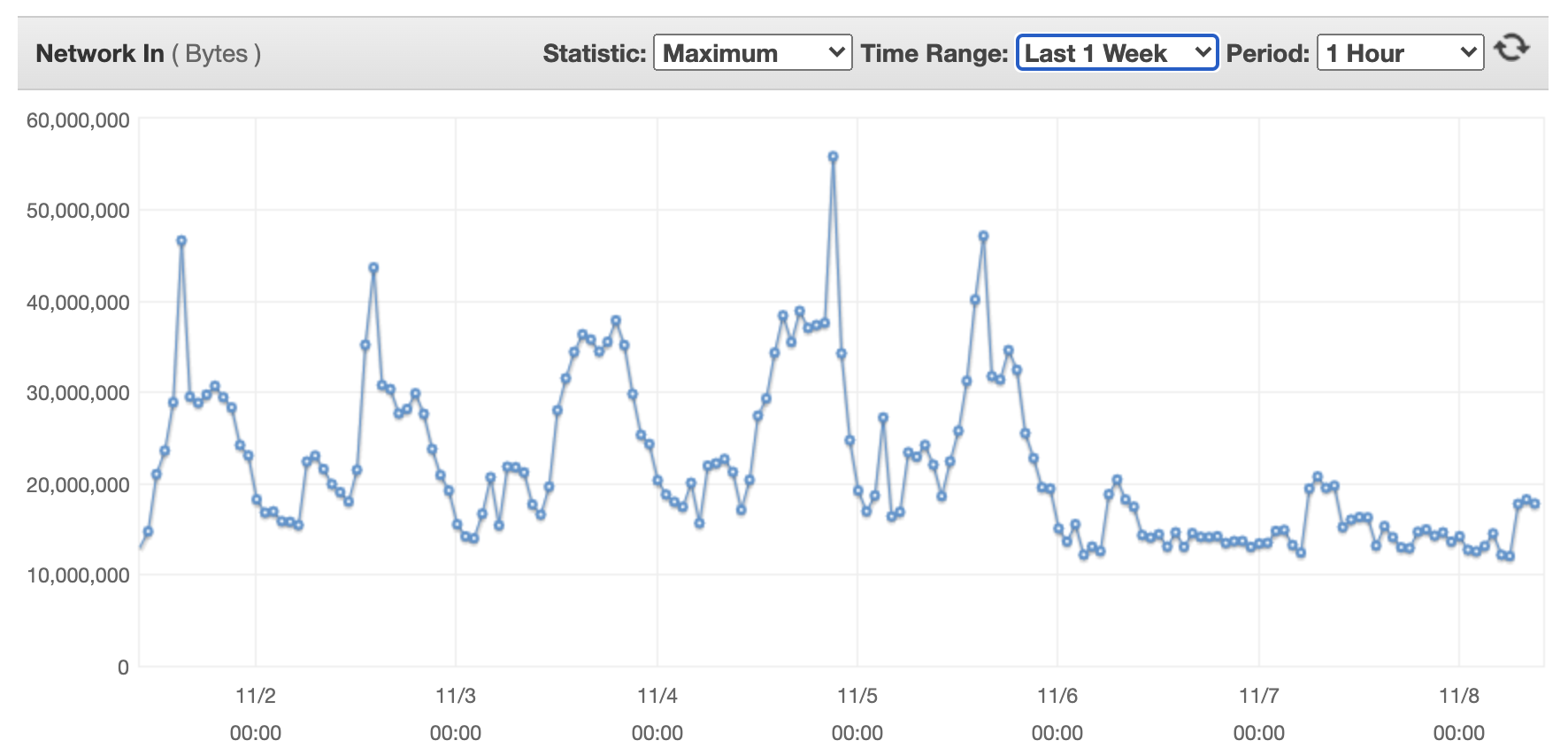
The next exhibits outcoming community bytes for a single movement transformer machine.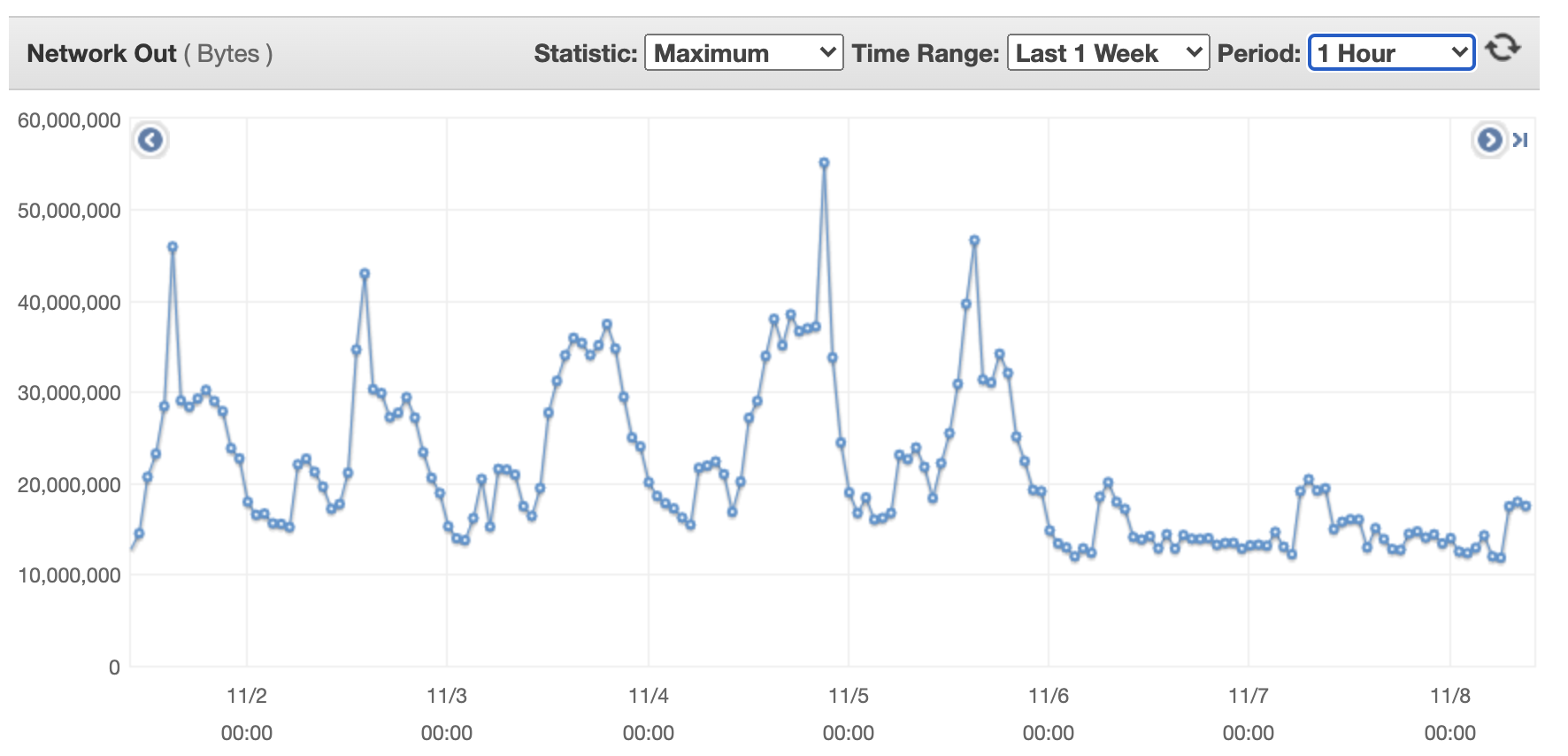
- The flows are despatched utilizing Kinesis Information Streams to the real-time evaluation engine.
- The Amazon EMR-based real-time engine consumes information in a number of seconds batches utilizing Yarn/Spark. The sampling price of every shopper is dynamically tuned in line with its throughput to make sure a hard and fast incoming knowledge price for all purchasers. We achieved this utilizing Amazon EMR Managed Scaling with a customized coverage (accessible with Amazon EMR variations 5.30.1 and later), which permits us to scale EMR nodes in or out based mostly on Amazon CloudWatch metrics, with two completely different guidelines for scale-out and scale-in. The metric we created is predicated on the Amazon EMR operating time, as a result of our real-time AI risk detection runs on a sliding window interval of some seconds.
- The dimensions-out coverage tracks the common operating time over a interval of 10 minutes, and scales the EMR nodes if it’s longer than 95% of the required interval. This enables us to stop processing delays.
- Equally, the scale-in coverage makes use of the identical metric however measures the common over a 30-minute interval, and scales the cluster accordingly. This allows us to optimize cluster prices and cut back the variety of EMR nodes in off-hours.
- To optimize and seamlessly scale our AI inference calls, these have been made accessible by means of an ALB and one other auto scaling group of servers (AI model-service).
- We use Amazon DynamoDB as a quick and extremely accessible states desk.
The next determine exhibits the variety of information processed by the Kinesis knowledge stream over a single day.
The next exhibits the Kinesis knowledge streams information price per minute.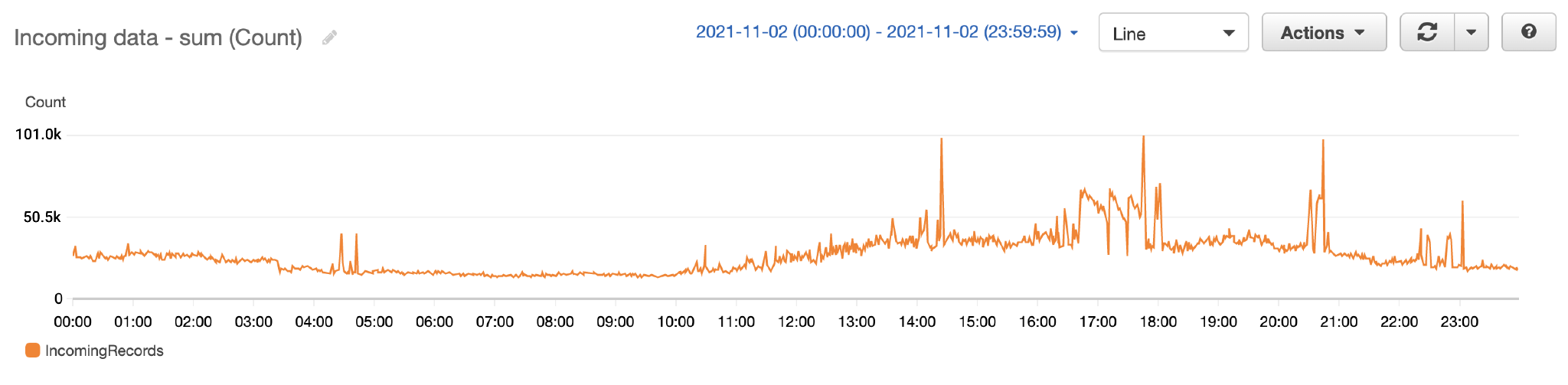
AI predictions and risk detections are despatched to continued processing and alerting, and are saved in Amazon DocumentDB (with MongoDB compatibility).
Conclusion
With the strategy described on this publish, Cynamics has been offering risk prediction based mostly on near-real-time evaluation of its distinctive AI algorithms for a continually rising buyer base in a seamless and routinely scalable approach. Since first implementing the answer, we’ve managed to simply and linearly scale our structure, and have been capable of additional optimize our prices by transitioning to Graviton-based processors within the movement transformers, which lowered over 30% of our movement transformers prices.
We’re contemplating the next subsequent steps:
- An automated machine studying lifecycle utilizing an Amazon SageMaker Studio pipeline, which incorporates the next steps:
- Extra value discount by shifting the EMR situations to be Graviton-based as properly, which ought to yield a further 20% discount.
In regards to the Authors
 Dr. Yehezkel Aviv is the co-founder and CTO of Cynamics, main the corporate innovation and know-how. Aviv holds a PhD in Pc Science from the Technion, specializing in cybersecurity, AI, and ML.
Dr. Yehezkel Aviv is the co-founder and CTO of Cynamics, main the corporate innovation and know-how. Aviv holds a PhD in Pc Science from the Technion, specializing in cybersecurity, AI, and ML.
 Sapir Kraus is Head of Engineering at Cynamics, the place his core focus is managing the software program growth lifecycle. His duties additionally embody software program structure and offering technical steerage to workforce members. Exterior of labor, he enjoys roasting espresso and barbecuing.
Sapir Kraus is Head of Engineering at Cynamics, the place his core focus is managing the software program growth lifecycle. His duties additionally embody software program structure and offering technical steerage to workforce members. Exterior of labor, he enjoys roasting espresso and barbecuing.
 Omer Haim is a Startup Options Architect at Amazon Internet Providers. He helps startups with their cloud journey, and is enthusiastic about containers and ML. In his spare time, Omer likes to journey, and sometimes recreation together with his son.
Omer Haim is a Startup Options Architect at Amazon Internet Providers. He helps startups with their cloud journey, and is enthusiastic about containers and ML. In his spare time, Omer likes to journey, and sometimes recreation together with his son.
[ad_2]