

[ad_1]
At the moment, organizations spend a substantial period of time understanding enterprise processes, profiling information, and analyzing information from quite a lot of sources. The result’s extremely structured and arranged information used primarily for reporting functions. These conventional programs extract information from transactional programs that include metrics and attributes that describe totally different features of the enterprise. Non-traditional information sources corresponding to internet server logs, sensor information, clickstream information, social community exercise, textual content, and pictures drive new and fascinating use circumstances like intrusion detection, predictive upkeep, advert placement, and quite a few optimizations throughout a variety of industries. Nevertheless, storing the various datasets can grow to be costly and tough as the quantity of knowledge will increase.
The info lake method embraces these non-traditional information varieties, whereby all the information is stored in its uncooked kind and solely remodeled when wanted. An information lake is a centralized repository that permits you to retailer all of your structured and unstructured information at any scale. Information lakes can acquire streaming audio, video, name logs, and sentiment and social media information to offer extra full, sturdy insights. This has a substantial impression on the power to carry out AI, machine studying (ML), and information science.
Earlier than constructing an information lake, organizations want to finish the next conditions:
- Perceive the foundational constructing blocks of knowledge lake
- Perceive the companies concerned in constructing an information lake
- Outline the personas wanted to handle the information lake
- Create the safety insurance policies required for the totally different companies to work in concord when transferring the information to create the information lake
To make constructing an information lake simpler, this publish presents an answer to handle and deploy your information lake as an AWS Service Catalog product. This allows you to create an information lake in your whole group or particular person strains of enterprise, or just to get began with analytics and ML use circumstances.
Answer overview
This publish offers a easy option to deploy an information lake as an AWS Service Catalog product. AWS Service Catalog permits you to centrally handle and deploy IT companies and purposes in a self-service method by means of a typical, customizable product catalog. We create automated pipelines to maneuver information from an operational database into an Amazon Easy Storage Service (Amazon S3) based mostly information lake in addition to outline methods to maneuver unstructured information from disparate information sources into the information lake. We additionally outline fine-grained permissions within the information lake to allow question engines like Amazon Athena to securely analyze information.
The next are some benefits of getting your information lake as an AWS Service Catalog product:
- Implement compliance with company requirements so you possibly can management which IT companies and variations can be found and who will get permission entry by particular person, group, division, or value middle.
- Implement governance by serving to workers rapidly discover and deploy solely authorised IT companies with out giving direct entry to the underlying companies.
- Finish-users, like builders, information scientists, or enterprise customers, have fast and quick access to a customized, curated listing of merchandise that may be deployed constantly, is all the time in compliance, and is all the time safe by means of self-service, which accelerates enterprise progress.
- Implement constraints corresponding to limiting the AWS Area by which the information lake could be launched.
- Implement tagging based mostly on division or value middle to maintain observe of the information lake constructed for various departments.
- Centrally handle the IT service lifecycle by centrally including new variations to the information lake product.
- Enhance operational effectivity by integrating with third-party merchandise and ITSM instruments corresponding to ServiceNow and Jira.
- Construct an information lake based mostly on a reusable basis offered by a central IT group.
The next diagram illustrates how information lake could be bundled as a product inside a Service Catalog Portfolio together with different merchandise:

Answer structure
The next diagram illustrates the structure for this answer:

We use the next companies on this answer:
- Amazon S3 – Amazon S3 is an object storage service that gives industry-leading scalability, information availability, safety, and efficiency. For this use case, you employ Amazon S3 as storage for the information lake.
- AWS Lake Formation – Lake Formation makes it easy to arrange a safe information lake—a centralized, curated, and secured repository that shops all of your information—each in its authentic kind and ready for evaluation. The info lake admin can simply label the information and provides customers granular permissions to entry approved datasets.
- AWS Glue – AWS Glue is a serverless information integration service that makes it straightforward to find, put together, and mix information for analytics, ML, and software improvement.
- Amazon Athena – Athena is an interactive question service that makes it easy to investigate information in Amazon S3 utilizing normal SQL. Athena is serverless, so there is no such thing as a infrastructure to handle, and also you pay just for the queries you run and the quantity of knowledge being scanned.
Datasets
As an instance how information is managed within the information lake, we use pattern datasets which might be publicly accessible. The primary dataset is United States producers census information that we obtain in a structured format right into a relational database. As well as, we will load United States faculty census information in its uncooked format into the information lake.
Walkthrough overview
AWS Service Catalog permits organizations to create and handle catalogs of IT companies which might be authorised to be used on AWS. It permits you to centrally handle deployed IT companies and your purposes, sources, and metadata. Following the identical idea, we deploy an information lake as a set of AWS companies and sources as an AWS Service Catalog product. This helps you obtain constant governance and meet your compliance necessities, whereas enabling customers to rapidly deploy solely the authorised companies.
Comply with the steps within the subsequent sections to deploy an information lake as an AWS Service Catalog product. For this publish, we load United States public census information into an Amazon Relational Database Service (Amazon RDS) for MySQL occasion to reveal ingestion of knowledge into the information lake from a relational database. We use an AWS CloudFormation template to create S3 buckets to load the script for creating the information lake as an AWS Service Catalog product in addition to scripts for information transformation.
Deploy the CloudFormation template
Be sure you deploy your sources within the US East (N. Virginia) Area (us-east-1). We use the offered CloudFormation template to create all the mandatory sources. This step removes any handbook errors by growing effectivity, and offers constant configurations over time.
- Select Launch Stack:

- On the Create stack web page, Amazon S3 URL ought to present as
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/datalake-service-catalog/datalake_portfolio.yaml. - Select Subsequent.

- Enter
datalake-portfoliofor the stack identify. - For Portfolio identify, enter a reputation for the AWS Service Catalog portfolio that holds the information lake product.
- Select Subsequent.
- Select Create stack and look ahead to the stack to create the sources in your AWS account.
On the stack’s Sources tab, you will discover the next:
- DataLakePortfolio – The AWS Service Catalog portfolio
- ProdAsDataLake – The info lake as a product
- ProductCFTDataLake – The CloudFormation template as a product
In case you select the arrow subsequent to the DataLakePortfolio useful resource, you’re redirected to the AWS Service Catalog portfolio, with datalake listed as a product.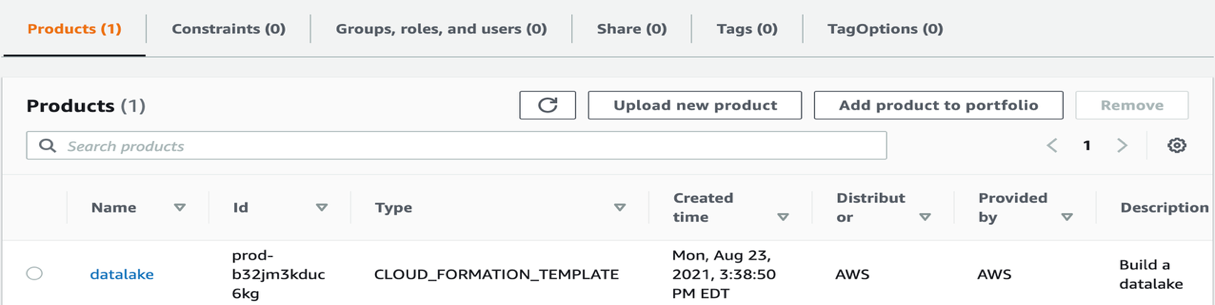
Grant permissions to launch the AWS Service Catalog product
We have to present acceptable permissions for the present consumer to launch the datalake product we simply created.
- On the portfolio web page on the AWS Service Catalog console, select the Teams, roles, and customers tab.
- Select Add teams, roles, customers.
- Choose the group, function, or consumer you wish to grant permissions to launch the product.

One other method is to reinforce the potential of the information lake by constructing a multi-tenant information lake. A multi-tenant information lake permits internet hosting information from a number of enterprise items in the identical information lake and sustaining information isolation by means of roles with totally different permission units. To construct a multi-tenant information lake, you possibly can add a variety of stakeholders (builders, analysts, information scientists) from totally different organizational items. By defining acceptable roles, multi-tenancy helps obtain information sharing and collaboration between totally different groups and combine a number of information silos to get a unified view of the information. You may add these acceptable roles on the portfolio web page.
Within the following instance screenshot, information analysts from HR and Advertising have entry to their very own datasets, the enterprise analyst has entry to each datasets to get a unified view of the information to derive significant insights, and the admin consumer manages the operations of the central information lake.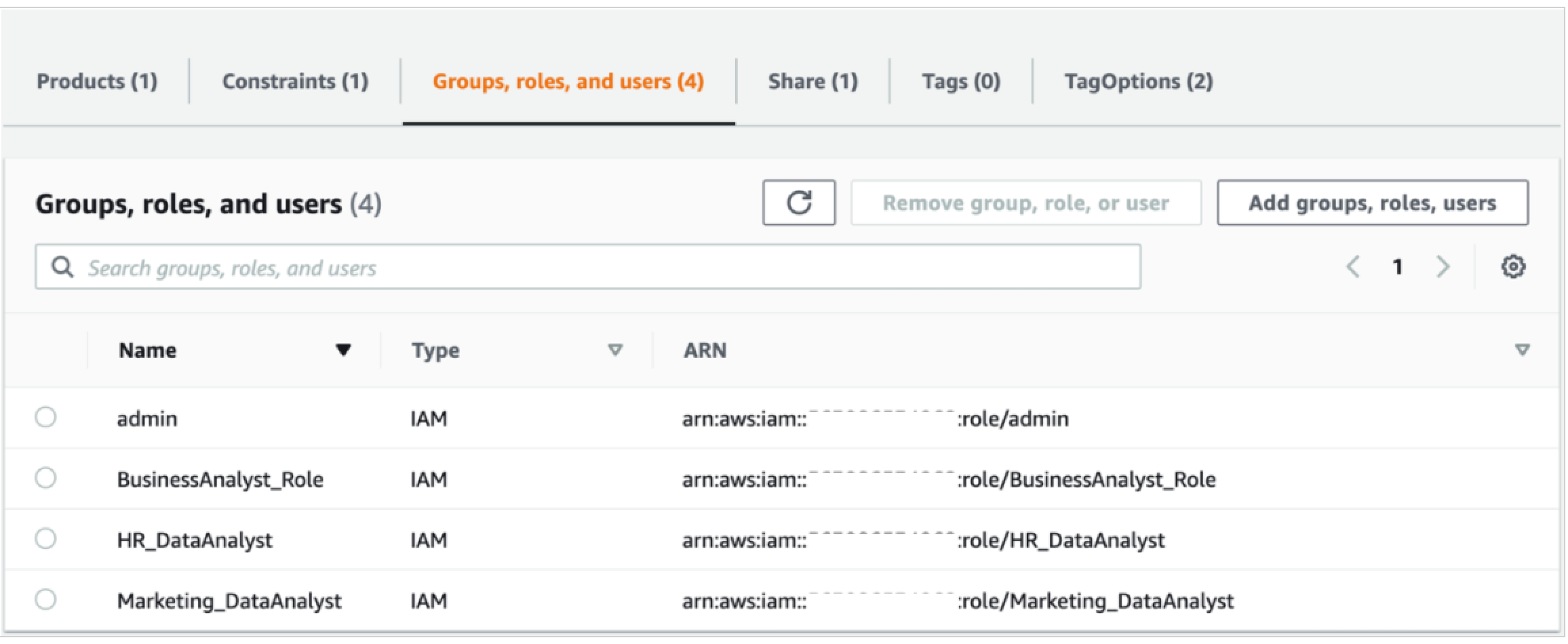
As well as, you possibly can implement constraints on the information lake from the AWS Service Catalog console versus the information lake product launched independently as a CloudFormation script. This enables the central IT staff to allow governance management when a division chooses to construct an information lake for his or her enterprise customers.
- To allow constraints, select the Constraints tab on the portfolio web page.
For instance, a template constraint permits you to restrict the choices which might be accessible to end-users once they launch the product. The next screenshot exhibits an instance of configuring a template constraint.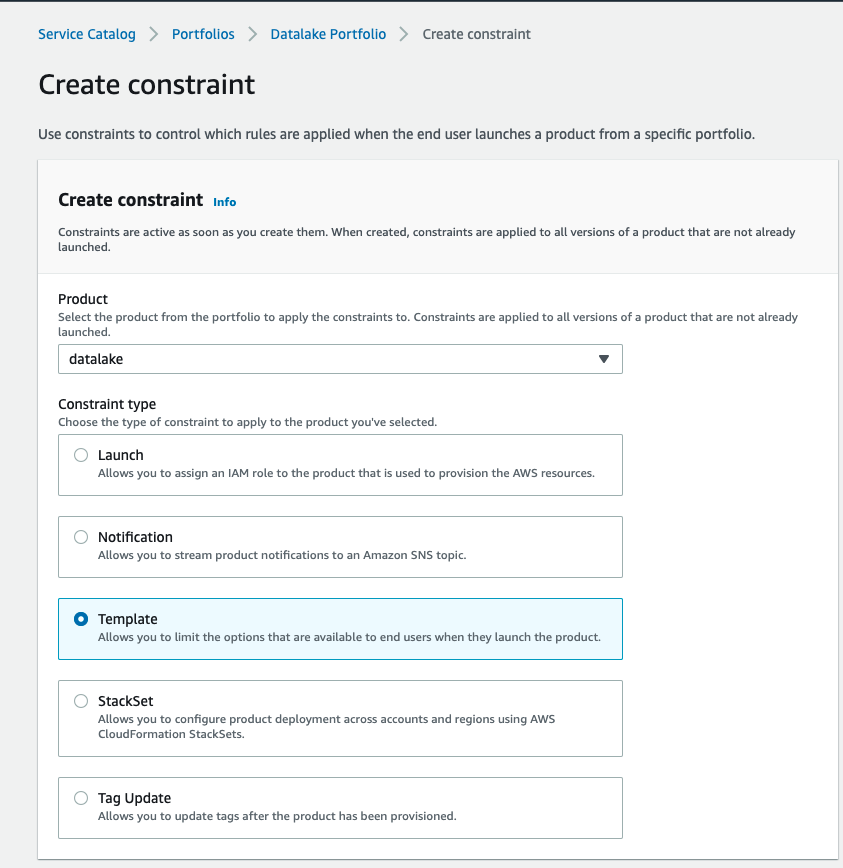
The VPC CIDR vary is restricted to a sure vary when launching the information lake.
We will now see the template constraint listed on the Constraints tab.
If the constraint is violated and a distinct CIDR vary is entered whereas launching the product, the template throws an error, as proven within the following screenshot.
As well as, whereas launching the product to trace prices per division or staff, the central IT staff can outline tags within the TagOptions library and power the operations staff to pick tags from an inventory of values to distinctly choose the enterprise unit for which the information lake is being created and ultimately observe prices per division or enterprise unit.
- Select the Tags tab to handle tags.

- After setting your group’s requirements for roles, constraints, and tags, the central IT staff can share the AWS Service Catalog
datalakeportfolio with accounts or organizations through AWS Organizations.
AWS Service Catalog directors from one other AWS account can then distribute the information lake product to their end-users.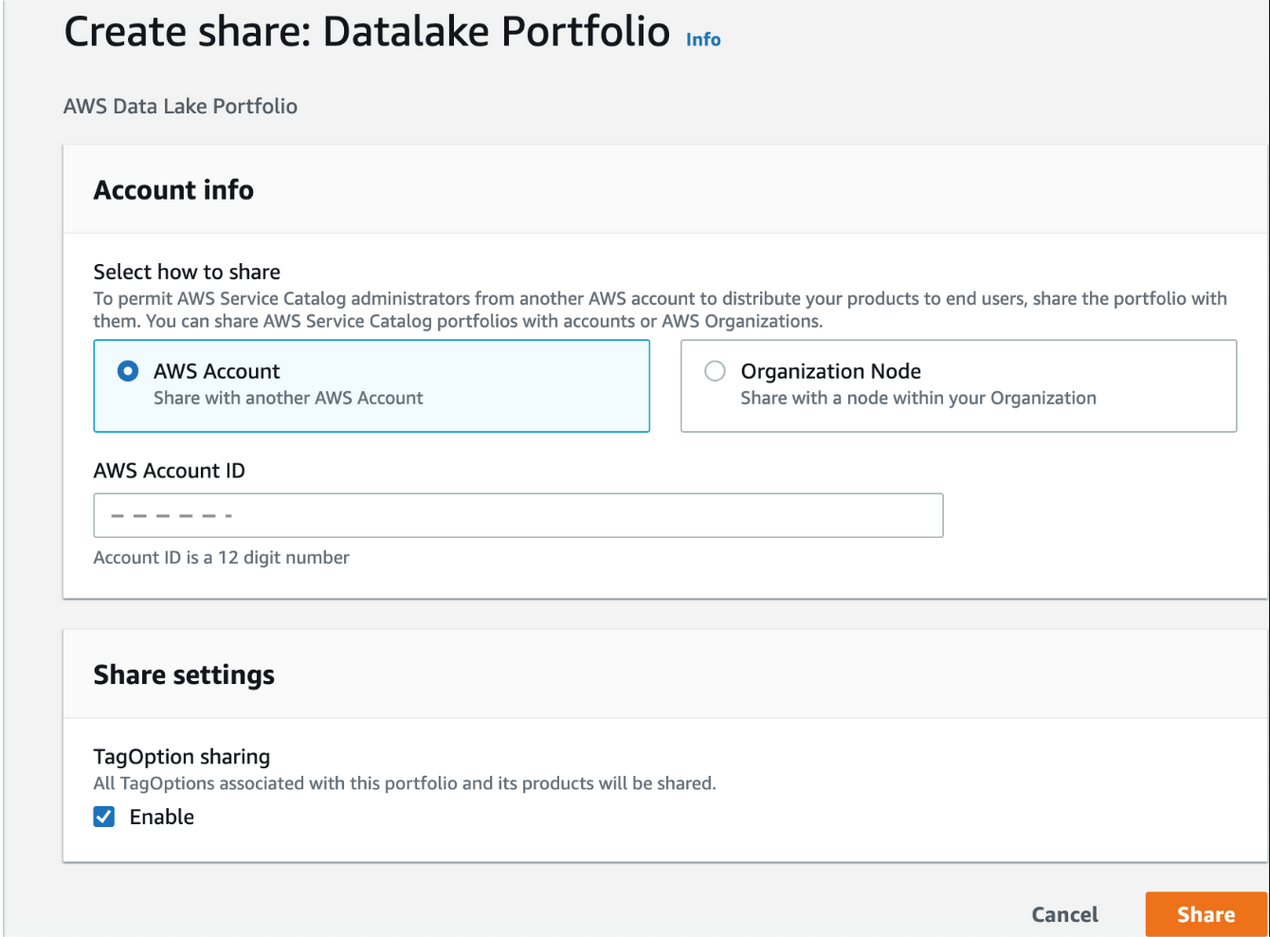
You may view the accounts with entry to the portfolio on the Share tab.
Launch the information lake
To launch the information lake, full the next steps:
- Check in because the consumer or function that you simply granted permissions to launch the information lake. When you have by no means launched AWS Lake Formation service and never outlined an preliminary administrator, please go to the service and add an administrator.
- On the AWS Service Catalog console, choose the
datalakeproduct and select Launch product.
- Choose Generate identify to robotically enter a reputation for the provisioned product.
- Choose your product model (for this publish, v1.0 is chosen by default).
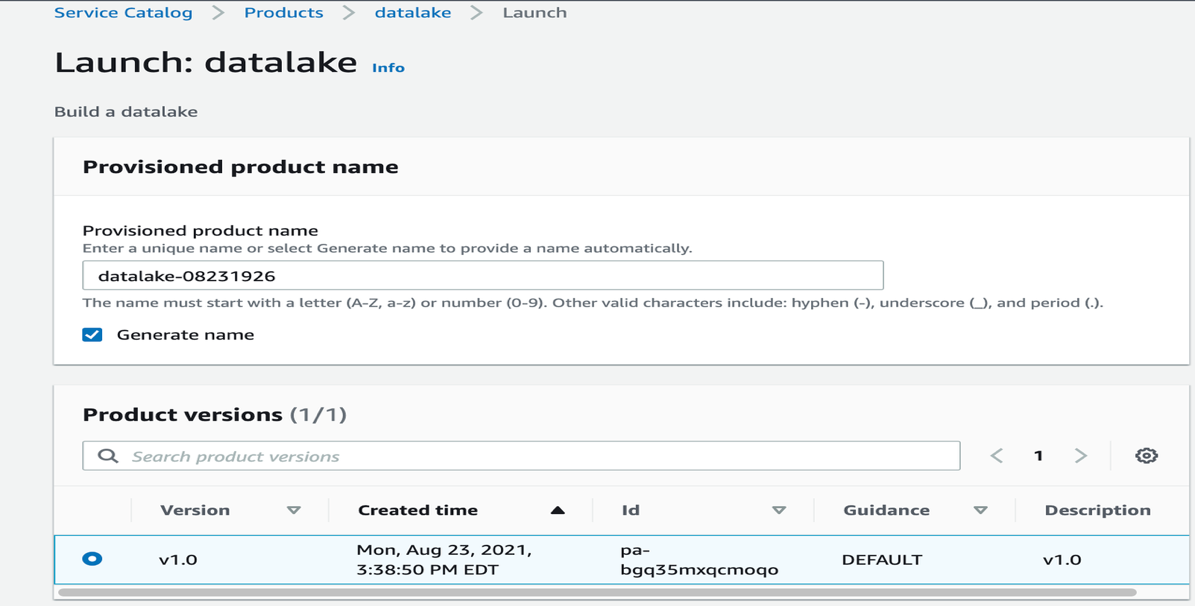
- Enter DB username and password.
- Confirm the stack identify of the beforehand launched CloudFormation template,
datalake-portfolio. - Select Launch product.
The datalake product triggers the CloudFormation template within the background, creates all of the sources, and launches the information lake in your account.
- On the AWS Service Catalog console, select Provisioned merchandise within the navigation pane.

- Select the output worth with the hyperlink to the CloudFormation stack that created the information lake in your account.
- On the Sources tab, evaluate the main points of the sources created.
The next sources are created on this step as a part of the launching the AWS Service Catalog product:
- Information ingestion:
- A VPC with subnets and safety teams for internet hosting the RDS for MySQL database with pattern information.
- An RDS for MySQL database as a pattern supply to load information into the information lake. Confirm the VPC CIDR vary to host the information lake in addition to database subnet CIDR ranges for the database.
- The default RDS for MySQL database. You may change the password as wanted on the Amazon RDS console.
- An AWS Glue JDBC connection to hook up with the RDS for MySQL database with the pattern information loaded.
- An AWS Glue crawler for information ingestion into the information lake.
- Information transformation:
- AWS Glue jobs for information transformation.
- An AWS Glue Information Catalog database to carry the metadata info.
- AWS Identification and Entry Administration (IAM) AWS Glue and AWS Lambda workflow roles to learn information from the RDS for MySQL database and cargo information into the information lake.
- Information visualization:
- IAM information lake administrator and information lake analyst roles for managing and accessing information within the information lake by means of Lake Formation.
- Two Athena named queries.
- Two customers:
- datalake_admin – Answerable for day-to-day operations, administration, and governance of the information lake.
- datalake_analyst – Has permissions to solely view and analyze the information utilizing totally different visualization instruments.
Information ingestion, transformation, and visualization
After the CloudFormation stack is prepared, we full the next steps to ingest, remodel, and visualize the information.
Ingest the information
We run an AWS Glue crawler to load information into the information lake. Optionally, you possibly can confirm that the information is accessible within the information supply by following the steps within the appendix of this publish. To run the crawler, full the next steps:
- On the AWS Glue console, select Crawlers within the navigation pane.
The Crawlers web page exhibits 4 crawlers created as a part of the information lake product deployment.
- Choose the crawler
GlueRDSCrawler-xxxx. - Select Run crawler.
A desk is added to the AWS Glue database gluedatabasemysql-blogdb.
The uncooked information is now able to run any type of transformations which might be wanted. On this instance, we remodel the uncooked information into Parquet format.
Remodel the information
AWS Glue offers a console and API operations to arrange and handle your extract, remodel, and cargo (ETL) workload. A job is the enterprise logic that performs the ETL work in AWS Glue. If you begin a job, AWS Glue runs a script that extracts information from sources, transforms the information, and hundreds it into targets. On this case, our supply is the uncooked S3 bucket and the goal is the curated S3 bucket to retailer the remodeled information in Parquet format after the AWS Glue job runs.
To rework the information, full the next steps:
- On the AWS Glue console, select Jobs within the navigation pane.
The Jobs web page lists the AWS Glue job created as a part of the information lake product deployment.
- Choose the job that begins with
GlueRDSJob. - On the Motion menu, select Edit script.

- Replace the identify of the S3 bucket on line 33 to the
ProcessedBucketS3worth on the Outputs tab of the second CloudFormation stack. - Choose the job once more and on the Motion menu, select Run job.
You may see the standing of the job because it runs.
The ETL job makes use of the AWS Glue IAM function created as a part of the CloudFormation script. To write down information into the curated bucket of the information lake, acceptable permissions should be granted to this function. These permissions have already been granted as a part of the information lake deployment. When the job is full, its standing exhibits as Succeeded.
The remodeled information is saved within the curated bucket on the information lake.
The pattern information is now remodeled and is prepared for information visualization.
Visualize the information
On this last step, we use Lake Formation to handle and govern the information that determines who has entry to the information and what degree of entry they’ve. We do that by assigning granular permissions for the customers and personas created by the information lake product. We will then question the information utilizing Athena.
The customers datalake-admin and datalake-analyst have already been created. datalake_admin is accountable for day-to-day operations, administration, and governance of the information lake. datalake_analyst has permissions to view and analyze the information utilizing totally different visualization instruments.
As a part of the information lake deployment, we outlined the curated S3 bucket as the information lake location in Lake Formation. To learn from and write to the information lake location, we now have to verify all of the permissions are correctly assigned. Within the earlier part, we embedded the permission for the AWS Glue ETL job to learn from and write to the information lake location within the CloudFormation template. Due to this fact, the function SC-xxxxGlueWorkFlowRole-xxxxx has acceptable permissions to imagine by the crawlers and create the required database and desk schema for querying the information. Word that the primary crawler analyzes information within the RDS for MySQL database and doesn’t entry the information lake, so we didn’t want to offer it permissions for the information lake.
To run the crawler, full the next steps:
- On the AWS Glue console, select Crawlers within the navigation pane.
- Choose the crawler
LakeCuratedZoneCrawler-xxxxxand select Run crawler.
The crawler reads the information from the information lake and populates the desk within the AWS Glue database created within the information ingestion stage and makes it accessible to question utilizing Athena.
To question the populated information within the AWS Glue Information Catalog utilizing Athena, we have to present granular permissions to the function utilizing Lake Formation governance and administration.
- On the Lake Formation console, select Information lake permissions within the navigation pane.
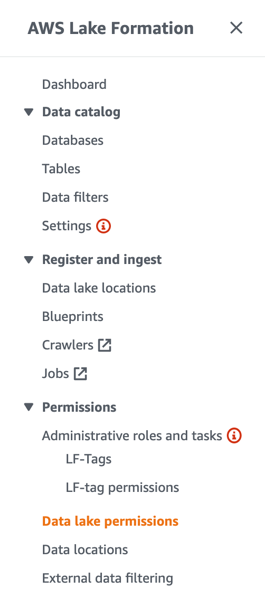
- Select Grant.
- For IAM customers and roles, select the function you wish to assign the permissions to.
- Choose Named information catalog sources.
- Select the database and desk.

- For Desk permissions, choose Choose.
- For Information permissions, choose All information entry.
This enables the consumer to see all the information within the desk however not modify it.
- Select Grant.

Now you possibly can question the information with Athena. In case you haven’t already arrange the Athena question outcomes path, see Specifying a Question Consequence Location for directions.
- On the Athena console, open the question editor.
- Select the Saved queries tab.
You need to see the 2 queries created as a part of the information lake product deployment.
- Select the question
CensusManufacturersQuery.
The database, desk, and question are pre-populated within the question editor.
- Select Run question to entry the information within the information lake.

We’ve got accomplished the method to load, remodel, and visualize the information within the information lake by fast deployment of an information lake as an AWS Service Catalog product. We used pattern information ingested in an RDS for MySQL database for example. You may repeat this course of and implement related steps utilizing Amazon S3 as an information supply. To take action, the pattern information file schools-census-data.csv is loaded and the corresponding AWS Glue crawler and job to ingest, remodel, and visualize the information has been created for you as a part of this AWS Service Catalog information lake product deployment.
Conclusion
On this publish, we noticed how one can reduce the effort and time required to construct an information lake. Establishing an information lake helps organizations to be data-driven, figuring out patterns in information and performing rapidly to speed up enterprise progress. Moreover, to take full benefit of your information lake, you possibly can construct and provide data-driven merchandise and purposes with ease by means of a extremely customizable product catalog. With AWS Service Catalog, you possibly can simply and rapidly deploy an information lake following frequent greatest practices. AWS Service Catalog additionally enforces constraints for community and account baselines to securely construct an information lake in an end-user atmosphere.
Appendix
To confirm the pattern information is loaded into Amazon RDS, full the next steps:
- On the Amazon Elastic Compute Cloud (Amazon EC2) console, choose the
EC2SampleRDSdataoccasion. - On the Actions menu, select Monitor and troubleshoot.
- Select Get system log.
The system log exhibits the depend of information loaded into the RDS for MySQL database:

Subsequent, we will check the connection to the database.
- On the AWS Glue console, select Connections within the navigation pane.
You need to see RDSConnectionMySQL-xxxx created for you.
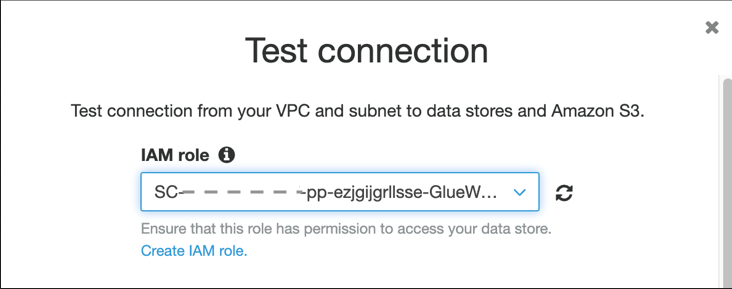
- Choose the connection and select Check connection.

- For IAM function¸ select the function
SC-xxxxGlueWorkFlowRole-xxxxx.
{kind=link}
RDSConnectionMySQL-xxxx ought to efficiently hook up with your RDS for MySQL DB occasion.
Concerning the Authors
 Mamata Vaidya is a Senior Options Architect at Amazon Internet Companies(AWS) accelerating clients of their adoption to the cloud within the space of bigdata analytics and foundational structure. She has over 20 years of expertise in constructing and architecting enterprise programs in healthcare, finance and cybersecurity with robust administration abilities. Previous to AWS, Mamata labored for Bristol-Myers Squibb and Citigroup in senior technical administration positions. Outdoors of labor, Mamata enjoys climbing with household and buddies and mentoring highschool college students.
Mamata Vaidya is a Senior Options Architect at Amazon Internet Companies(AWS) accelerating clients of their adoption to the cloud within the space of bigdata analytics and foundational structure. She has over 20 years of expertise in constructing and architecting enterprise programs in healthcare, finance and cybersecurity with robust administration abilities. Previous to AWS, Mamata labored for Bristol-Myers Squibb and Citigroup in senior technical administration positions. Outdoors of labor, Mamata enjoys climbing with household and buddies and mentoring highschool college students.
 Shan Kandaswamy is a Options Architect at Amazon Internet Companies (AWS) who’s enthusiastic about serving to clients remedy complicated issues. He’s a technical evangelist who advocates for distributed structure, bigdata analytics and serverless applied sciences to assist clients navigate the cloud panorama as they transfer to cloud computing. He’s a giant fan of journey, watching motion pictures and studying one thing new day-after-day.
Shan Kandaswamy is a Options Architect at Amazon Internet Companies (AWS) who’s enthusiastic about serving to clients remedy complicated issues. He’s a technical evangelist who advocates for distributed structure, bigdata analytics and serverless applied sciences to assist clients navigate the cloud panorama as they transfer to cloud computing. He’s a giant fan of journey, watching motion pictures and studying one thing new day-after-day.
[ad_2]