

{kind=link}
[ad_1]
At Databricks, we’ve got had the chance to assist hundreds of organizations modernize their knowledge architectures to be cloud-first and extract worth from their knowledge at scale with analytics and AI. Over the previous few years, we’ve been lucky to interact instantly with prospects throughout industries and areas about their data-driven aspirations – and the roadblocks that decelerate their potential to get there. Whereas challenges fluctuate drastically amongst industries and even particular person organizations, we’ve got developed a wealthy understanding of the highest 4 habits of information and AI-driven organizations.
Earlier than diving into the habits, let’s take a fast have a look at how organizations have approached enabling knowledge methods. First, knowledge groups have made know-how selections over time that propel a mind-set that’s primarily based round know-how stacks: knowledge warehousing, knowledge engineering, streaming real-time knowledge science, and machine studying. The issue is that’s not how enterprise items suppose. They give thought to use circumstances, the decision-making course of, and enterprise issues (e.g., buyer 360, personalization, fraud detection, and so forth). In consequence, enabling use circumstances turns into a fancy stitching train throughout know-how stacks. These ache factors aren’t simply anecdotal. In a latest survey carried out by Databricks and MIT Expertise Evaluation, 87% of surveyed organizations battle to succeed with their knowledge technique; it usually comes again to their strategy of specializing in a ’know-how stack.’ Second, there continues to be ample help inside IT groups to custom-build options slightly than shopping for off-the-shelf choices. This isn’t to say there aren’t legitimate situations the place custom-built options are the correct alternative, however in lots of circumstances know-how distributors have managed to unravel the vast majority of the widespread and low altering use circumstances enabling groups to concentrate on extra value-added initiatives listed on creating worth for the enterprise quicker. Lastly, from a individuals perspective, organizations have been well-intentioned of their methods tying know-how to enterprise outcomes however have failed as a result of the company tradition round knowledge hasn’t been addressed – in reality within the 2022 Information and AI Management Government Survey, 91.9% of respondents determine tradition as the best problem to turning into data-driven organizations.
Fortunately, these challenges are solvable – however require a special strategy. We’re at present in a “knowledge renaissance” the place enterprises understand that to execute on novel knowledge and AI use circumstances, the legacy mannequin of siloed know-how stacks wants to provide approach to a unified strategy. In different phrases, it’s not about simply knowledge analytics or simply ML – it’s about constructing a full enterprise-wide knowledge, analytics, and AI platform. In addition they acknowledge that they should empower their knowledge groups with extra turnkey options to be able to concentrate on creating enterprise worth and never constructing tech stacks. Organizations additionally understand that the technique can’t be some top-down authoritarian initiative however must be supported with trainings to enhance knowledge literacy and capabilities that make knowledge ubiquitous and a part of on a regular basis life. In the end, each group attempting to determine the best way to obtain all this whereas making issues easy. So how are you going to get there? These are the highest habits we’ve recognized amongst profitable knowledge and AI-driven organizations.
1. Embrace an AI future
Once we first began on the Databricks journey, we frequently mentioned how high-quality knowledge is essential for analytics, however much more so for AI, and that the latter, particularly for data-driven resolution making, will energy the long run. Over time, as use circumstances like personalization, forecasting, vaccine discovery, and churn evaluation have accelerated and superior with AI, individuals are extra snug with the truth that the long run is in AI. The habits are shifting from simply asking what occurred? to now specializing in why, producing excessive confidence predictions, and in the end influencing future outcomes and enterprise selections. And we see around the globe organizations like Rolls-Royce, ABN AMRO, Shell, Regeneron, Comcast, and HSBC are utilizing knowledge for superior analytics and AI to ship new capabilities or drastically improve current ones. And we see this throughout each vertical. Actually, Duan Peng, SVP of Information and AI at WarnerMedia, believes “The impression of AI has solely began. Within the coming years, we’ll see a large enhance in how AI is used to reimagine buyer experiences.”
2. Perceive that the long run is open
There’s an attention-grabbing statistic from MIT that states 50% of information and know-how leaders say that if given the redo button, they’d embrace extra open requirements and open codecs of their knowledge architectures – in different phrases, optionality. The problem to this strategy is that many knowledge practitioners and leaders affiliate “open” strictly with open supply – and primarily throughout the context of the on-prem world (i.e., Apache Hadoop). However oftentimes, you’ve received an open supply engine, and it was nearly how do you get providers and help round it.
In our conversations with CIOs and CDOs about what open means to them, it comes down to 3 core tenents. First, for his or her current answer, what’s the price of portability? It’s nice you threw some code on GitHub repost someplace. That’s not what they care about. What they actually care about is, if it comes all the way down to it, the viability of transferring off the platform from each a functionality and price standpoint. Subsequent, how properly do these capabilities enable for plugging right into a wealthy ecosystem, whether or not it’s homegrown or leveraging different distributors merchandise? Third, what’s the studying curve for inside practitioners when onboarding? How rapidly can they stand up to hurry?
Each group is underneath rising strain to fly the aircraft whereas it’s being upgraded, however as we get to the purpose the place there are a number of choices on the best way to fly and improve, that open nature permits optionality for the long run. The optionality enabled by an embrace of open requirements and codecs is turning into a essential element organizations are more and more prioritizing of their methods.
3. Be multi-cloud prepared
There are three varieties of knowledge and AI-driven organizations: those that are already multi-cloud, those that have gotten multi-cloud, and people which can be on the fence about multi-cloud. Actually, Accenture went on to foretell multi-cloud as their quantity 4 cloud development for 2021 and past. There are various drivers for a multi-cloud strategy, akin to the power to ship new capabilities with cloud-specific best-of-breed instruments, mergers and acquisitions, and necessities of doing enterprise like laws, buyer cloud-specific calls for, and so forth. However one of many greatest drivers is financial leverage. As cloud adoption grows and knowledge grows, for a lot of, spending on cloud infrastructure can be one of many largest line gadgets. As organizations take into consideration a multi-cloud structure, two issues roll as much as the highest as necessities. First, the end-user expertise must be the identical. Information leaders don’t need end-users to consider the best way to handle knowledge, run analytics or construct fashions individually throughout cloud suppliers. Second, on this pursuit of consistency, they don’t need some watered-down functionality both. There’s loads of investments that cloud suppliers are making of their infrastructure. And profitable organizations acknowledge the necessity to make sure that, as they function on every cloud, they deeply combine with them throughout efficiency, capabilities, safety, and billing. That is fairly onerous to get proper.
4. Simplify the information structure
Productiveness and effectivity are essential. In the end any modernization efforts are geared toward simplifying architectures as a method to extend productiveness, which has a domino impact on organizations’ potential to get to new insights, construct knowledge merchandise and ship improvements quicker. Organizations need their knowledge groups to concentrate on fixing enterprise issues and creating new alternatives, not simply managing infrastructure or reporting the information. To offer you an instance, Google printed “Hidden Technical Debt in Machine Studying Programs,” outlining the tax related to constructing ML merchandise. In the end the findings concluded that knowledge groups spend extra time on every little thing else from knowledge curation, administration, and pipelines than the precise ML code, which is what in the end will transfer the enterprise ahead.
This begs the query: how can knowledge groups automate as a lot as doable and spend extra time on the issues that can transfer the needle? Many organizations have engineers who like to construct every little thing. However the questions you wish to ask are: is constructing every little thing your self the correct strategy? How do you concentrate on the core power and aggressive benefit? The elemental wants of any group aren’t that distinctive; in reality, many are on the identical journey, and third-party options have gotten extremely efficient at automating turnkey duties. Ask your self how a lot is it price to principally decrease your general TCO and be capable of transfer quicker? Or as, Habsah Nordin, Head of Enterprise Information, at PETRONAS places it, “It’s not about how refined your know-how stack is. The main target ought to be: Will it assist create probably the most worth from the information you might have?”
Why are so many struggling whether it is this easy?
The reply: 30+ years of fragmented, polarizing legacy tech stacks that simply hold getting greater and extra advanced. The determine under is a simplified image of what’s the actuality for a lot of. Actually, solely 13% of organizations are literally succeeding with their knowledge methods and it’s owed to their concentrate on getting the foundations of sound knowledge administration and structure proper.
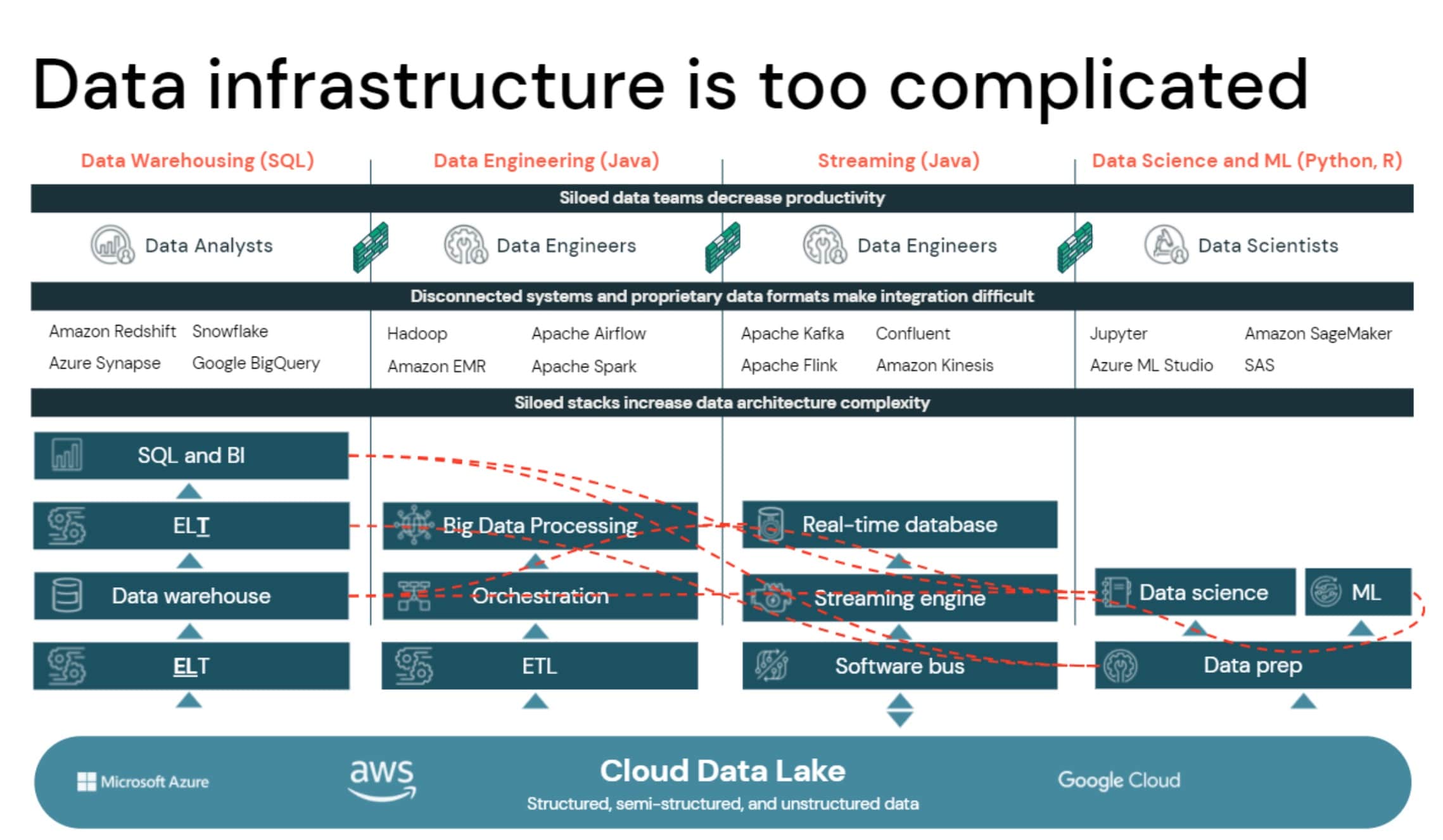
Most organizations land all the knowledge initially in an information lake, however to make it usable, they need to construct 4 separate siloed stacks. The pink dots characterize buyer and product knowledge that should be copied and moved round these totally different programs. The foundation of this complexity comes from the truth that there are two separate approaches which can be at odds with one another.
On one hand, you might have knowledge lakes, that are open, and on the opposite finish you might have knowledge warehouses which can be proprietary. They’re probably not appropriate. One is based on Python and Java. The opposite one is based on SQL, and these two worlds don’t combine and match very properly. You even have incompatible safety and governance fashions. So it’s a must to do safety governance and management for information within the knowledge lake and for tables and columns within the knowledge warehouse. They’re like two magnets that as a substitute of coming collectively, repel one another making it almost not possible for the broader inhabitants of organizations to construct on the 4 habits outlined above. Even the unique architect of the information warehouse, Invoice Inmon, is recognizing that the present state of affairs outlined within the picture above shouldn’t be what’s going to unlock the subsequent decade-plus of innovation.
The nice convergence of lakes and warehouses
As organizations take into consideration their strategy, there are solely two paths, a lake-first or warehouse-first. Let’s first discover knowledge warehouses, which have been obtainable for many years. They’re implausible for enterprise analytics and rearview mirror knowledge evaluation that focuses on reporting the information. However they’re not good for superior analytics capabilities, and dealing with them will get fairly advanced when knowledge groups are compelled to maneuver all of that knowledge into an information lake simply to drive new use circumstances. Moreover, knowledge warehouses are usually pricey as you attempt to scale. Information lakes, the place the vast majority of the world’s knowledge resides at present, helped clear up many of those challenges. Through the years, a bunch of nice water analogies emerged round knowledge lakes like knowledge streams, knowledge rivers, knowledge reservoirs that help ML and AI natively. However they don’t do a superb job supporting a few of these core enterprise intelligence (BI) use circumstances, and they’re lacking the information high quality and knowledge governance items that knowledge warehouses embody. Information lakes too usually develop into knowledge swamps. In consequence, we at the moment are seeing the convergence between lakes and warehouses with the rise of the information lakehouse structure.
Lakehouse combines the perfect of each knowledge warehouses and knowledge lakes with a lake-first strategy (see FAQs). In case your knowledge is already within the lake, why migrate it out and confine it to an information warehouse…after which be depressing when attempting to execute on each AI and analytics use circumstances? As an alternative, with lakehouse structure, organizations can start constructing on the 4 habits seen in profitable knowledge and AI-driven organizations. By having a lake-first strategy that unlocks all of the organizational knowledge, and is supported by easy-to-use, automated, and auditable tooling, an AI future turns into more and more doable. Organizations additionally achieve optionality that was as soon as considered a fairy story. True lakehouse structure is constructed on open requirements and codecs (and the Databricks platform is constructed on Delta Lake, MLflow, and Apache Spark™), which empowers organizations with the power to benefit from the widest vary of current and future know-how, in addition to to entry to an unlimited pool of expertise. This optionality additionally extends to being multi-cloud prepared by not solely gaining leverage but additionally making certain a constant expertise to your customers with one knowledge platform no matter which knowledge resides with which cloud supplier. Lastly, simplicity, this goes with out saying, if you happen to can scale back the complexity of two uniquely distinct tech stacks which can be basically constructed for separate outcomes, a simplified tech panorama turns into completely doable.
What you need to hopefully takeaway is that you just’re not alone on this journey, and there are nice examples of organizations throughout each business and geo which can be making progress on simplifying their knowledge, analytics, and AI platforms to be able to develop into data-driven innovation hubs. Take a look at the Enabling Information and AI at Scale technique information to be taught extra about the perfect practices constructing data-driven organizations in addition to the newest on the 2021 Gartner Magic Quadrants (MQs) the place Databricks is the one cloud-native vendor to be named a pacesetter in each the Cloud Database Administration Programs and the Information Science and Machine Studying Platforms MQs.
[ad_2]