

{kind=link}
[ad_1]
particular function

AI and the Way forward for Enterprise
Machine studying, activity automation and robotics are already broadly utilized in enterprise. These and different AI applied sciences are about to multiply, and we take a look at how organizations can finest reap the benefits of them.
GTC, Nvidia’s flagship occasion, is at all times a supply of bulletins round all issues AI. The autumn 2021 version isn’t any exception. Huang’s keynote emphasised what Nvidia calls the Omniverse. Omniverse is Nvidia’s digital world simulation and collaboration platform for 3D workflows, bringing its applied sciences collectively.
Primarily based on what we have seen, we’d describe the Omniverse as Nvidia’s tackle Metaverse. It is possible for you to to learn extra in regards to the Omniverse in Stephanie Condon and Larry Dignan’s protection right here on ZDNet. What we are able to say is that certainly, for one thing like this to work, a confluence of applied sciences is required.
So let’s undergo a number of the updates in Nvidia’s know-how stack, specializing in parts corresponding to giant language fashions (LLMs) and inference.
See additionally: Every part introduced at Nvidia’s Fall GTC 2021.
NeMo Megatron, Nvidia’s open supply giant language mannequin platform
Nvidia unveiled what it calls the Nvidia NeMo Megatron framework for coaching language fashions. As well as, Nvidia is making obtainable the Megatron LLM, a mannequin with 530 billion that may be educated for brand new domains and languages.
Bryan Catanzaro, Vice President of Utilized Deep Studying Analysis at Nvidia, mentioned that “constructing giant language fashions for brand new languages and domains is probably going the most important supercomputing utility but, and now these capabilities are inside attain for the world’s enterprises”.
Whereas LLMs are definitely seeing a number of traction and a rising variety of purposes, this specific providing’s utility warrants some scrutiny. First off, coaching LLMs shouldn’t be for the faint of coronary heart and requires deep pockets. It has been estimated that coaching a mannequin corresponding to OpenAI’s GPT-3 prices round $12 million.
OpenAI has partnered with Microsoft and made an API round GPT-3 obtainable with a purpose to commercialize it. And there are a variety of inquiries to ask across the feasibility of coaching one’s personal LLM. The apparent one is whether or not you possibly can afford it, so let’s simply say that Megatron shouldn’t be aimed on the enterprise usually, however a selected subset of enterprises at this level.
The second query can be — what for? Do you actually need your individual LLM? Catanzaro notes that LLMS “have confirmed to be versatile and succesful, capable of reply deep area questions, translate languages, comprehend and summarize paperwork, write tales and compute applications”.
Powering spectacular AI feats relies on an array of software program and {hardware} advances, and Nvidia is addressing each.
Nvidia
We might not go so far as to say that LLMs “comprehend” paperwork, for instance, however let’s acknowledge that LLMs are sufficiently helpful and can maintain getting higher. Huang claimed that LLMs “would be the greatest mainstream HPC utility ever”.
The true query is — why construct your individual LLM? Why not use GPT-3’s API, for instance? Aggressive differentiation could also be a respectable reply to this query. The fee to worth operate could also be one other one, in one other incarnation of the age-old “purchase versus construct” query.
In different phrases, if you’re satisfied you want an LLM to energy your purposes, and also you’re planning on utilizing GPT-3 or some other LLM with comparable utilization phrases, usually sufficient, it might be extra economical to coach your individual. Nvidia mentions use instances corresponding to constructing domain-specific chatbots, private assistants and different AI purposes.
To try this, it could make extra sense to start out from a pre-trained LLM and tailor it to your wants by way of switch studying reasonably than practice one from scratch. Nvidia notes that NeMo Megatron builds on developments from Megatron, an open-source undertaking led by Nvidia researchers finding out environment friendly coaching of enormous transformer language fashions at scale.
The corporate provides that the NeMo Megatron framework allows enterprises to beat the challenges of coaching subtle pure language processing fashions. So, the worth proposition appears to be — in the event you determine to spend money on LLMs, why not use Megatron? Though that feels like an inexpensive proposition, we must always word that Megatron shouldn’t be the one sport on the town.
Just lately, EleutherAI, a collective of impartial AI researchers, open-sourced their 6 billion parameter GPT-j mannequin. As well as, if you’re concerned with languages past English, we now have a big European language mannequin fluent in English, German, French, Spanish, and Italian by Aleph Alpha. Wudao is a Chinese language LLM which can also be the most important LLM with 1.75 trillion parameters, and HyperCLOVA is a Korean LLM with 204 billion parameters. Plus, there’s at all times different, barely older / smaller open supply LLMs corresponding to GPT2 or BERT and its many variations.
Aiming at AI mannequin inference addresses the entire price of possession and operation
One caveat is that relating to LLMs, greater (as in having extra parameters) doesn’t essentially imply higher. One other one is that even with a foundation corresponding to Megatron to construct on, LLMs are costly beasts to coach and function. Nvidia’s providing is ready to handle each of those points by particularly concentrating on inference, too.
Megatron, Nvidia notes, is optimized to scale out throughout the large-scale accelerated computing infrastructure of Nvidia DGX SuperPOD™. NeMo Megatron automates the complexity of LLM coaching with information processing libraries that ingest, curate, arrange and clear information. Utilizing superior applied sciences for information, tensor and pipeline parallelization, it allows the coaching of enormous language fashions to be distributed effectively throughout hundreds of GPUs.
However what about inference? In spite of everything, in concept, at the very least, you solely practice LLMs as soon as, however the mannequin is used many-many occasions to deduce — produce outcomes. The inference section of operation accounts for about 90% of the entire vitality price of operation for AI fashions. So having inference that’s each quick and economical is of paramount significance, and that applies past LLMs.
Nvidia is addressing this by asserting main updates to its Triton Inference Server, as 25,000+ corporations worldwide deploy Nvidia AI inference. The updates embody new capabilities within the open supply Nvidia Triton Inference Server™ software program, which supplies cross-platform inference on all AI fashions and frameworks, and Nvidia TensorRT™, which optimizes AI fashions and supplies a runtime for high-performance inference on Nvidia GPUs.
Nvidia introduces a lot of enhancements for the Triton Inference Server. The obvious tie to LLMs is that Triton now has multi-GPU multinode performance. This implies Transformer-based LLMs that now not slot in a single GPU will be inferenced throughout a number of GPUs and server nodes, which Nvidia says supplies real-time inference efficiency.
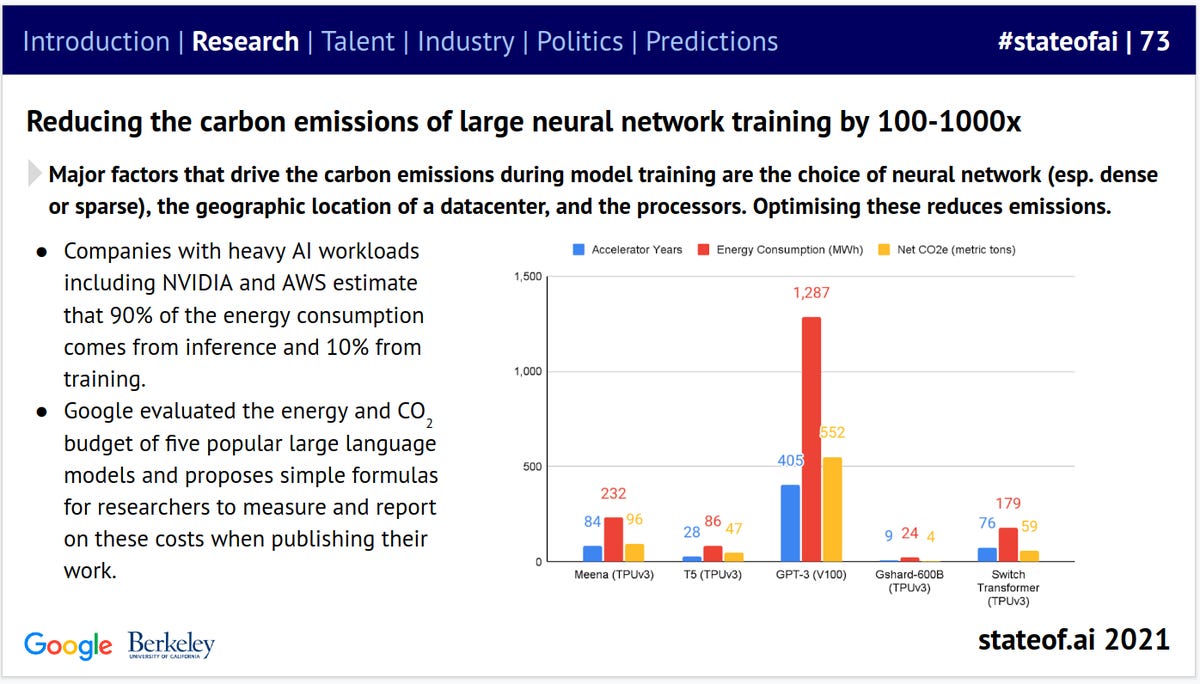
90% of the entire vitality required for AI fashions comes from inference
The Triton Mannequin Analyzer is a instrument that automates a key optimization activity by serving to choose one of the best configurations for AI fashions from a whole bunch of potentialities. In line with Nvidia, It achieves optimum efficiency whereas making certain the standard of service required for purposes.
RAPIDS FIL is a brand new back-end for GPU or CPU inference of random forest and gradient-boosted resolution tree fashions, which supplies builders with a unified deployment engine for each deep studying and conventional machine studying with Triton.
Final however not least, on the software program entrance, Triton now comes with Amazon SageMaker Integration, enabling customers to simply deploy multi-framework fashions utilizing Triton inside SageMaker, AWS’s absolutely managed AI service.
On the {hardware} entrance, Triton now additionally helps Arm CPUs and Nvidia GPUs and x86 CPUs. The corporate additionally launched the Nvidia A2 Tensor Core GPU, a low-power, a small-footprint accelerator for AI inference on the edge that Nvidia claims supply as much as 20X extra inference efficiency than CPUs.
Triton supplies AI inference on GPUs and CPUs within the cloud, information middle, enterprise edge, and embedded, is built-in into AWS, Google Cloud, Microsoft Azure and Alibaba Cloud, and is included in Nvidia AI Enterprise. To assist ship providers primarily based on Nvidia’s AI applied sciences to the sting, Huang introduced Nvidia Launchpad.
Nvidia shifting proactively to keep up its lead with its {hardware} and software program ecosystem
And that’s removed from every part Nvidia unveiled in the present day. Nvidia Modulus builds and trains physics-informed machine studying fashions that may study and obey the legal guidelines of physics. Graphs — a key information construction in fashionable information science — can now be projected into deep-neural networks frameworks with Deep Graph Library, or DGL, a brand new Python package deal.
Huang additionally launched three new libraries: ReOpt, for the $10 trillion logistics business. cuQuantum, to speed up quantum computing analysis. And cuNumeric, to speed up NumPy for scientists, information scientists and machine studying and AI researchers within the Python group. And Nvidia is introducing 65 new and up to date SDKs at GTC.
So, what to make of all that? Though we cherry-picked, every of these things would most likely warrant its personal evaluation. The large image is that, as soon as once more, Nvidia is shifting proactively to keep up its lead in a concerted effort to tie in its {hardware} to its software program.
LLMs could appear unique for many organizations at this level. Nonetheless, Nvidia is betting that they’ll see extra curiosity and sensible purposes and positioning itself as an LLM platform for others to construct on. Though alternate options exist, having curated, supported, and bundled with Nvidia’s software program and {hardware} ecosystem and model will most likely appear to be a beautiful proposition to many organizations.
The identical goes for the deal with inference. Within the face of accelerating competitors by an array of {hardware} distributors constructing on architectures designed particularly for AI workloads, Nvidia is doubling down on inference. That is the a part of the AI mannequin operation that performs the largest half within the complete price of possession and operation. And Nvidia is, as soon as once more, doing it in its signature model – leveraging {hardware} and software program into an ecosystem.
[ad_2]