

{kind=link}
[ad_1]
The International Funding Analysis (GIR) division at Goldman Sachs is accountable for offering analysis and insights to the agency’s purchasers within the fairness, fastened earnings, foreign money, and commodities markets. One of many long-standing objectives of the GIR workforce is to ship a personalised expertise and related analysis content material to their analysis customers. Beforehand, with a view to customise the person expertise for his or her numerous forms of purchasers, GIR supplied a number of distinct editions of their analysis web site that had been supplied to customers primarily based on broad standards. Nonetheless, GIR didn’t have any approach to create a personally curated content material move on the particular person person stage. To offer this performance, GIR needed to implement a system to actively filter the content material that’s really useful to their customers on a per-user foundation, keyed on traits such because the person’s job title or working area. Having this type of system in place would each enhance the person expertise and simplify the workflows of GIR’s analysis customers, by lowering the quantity of effort and time required to seek out the analysis content material that they want.
Step one in the direction of reaching that is to immediately classify GIR’s analysis customers primarily based on their profiles and readership. To that finish, GIR created a system to tag customers with personas. Every persona represents a kind or classification that particular person customers may be tagged with, primarily based on sure standards. For instance, GIR has a sequence of personas for classifying a person’s job title, and a person tagged with the “Chief Funding Officer” persona could have completely different analysis content material highlighted and have a special web site expertise in comparison with one that’s tagged with the “Company Treasurer” persona. This persona-tagging system can each effectively perform the information operations required for tagging customers, in addition to have new personas created as wanted to suit use instances as they emerge.
On this put up, we have a look at how GIR applied this technique utilizing Amazon EMR.
Problem
Given the variety of contacts (i.e., tens of millions) and the rising variety of publications maintained in GIR’s analysis information retailer, making a system for classifying customers and recommending content material is a scalability problem. A newly created persona might doubtlessly apply to virtually each contact, wherein case a tagging operation would have to be carried out on a number of million information entries. Usually, the variety of contacts, the complexity of the information saved per contact, and the quantity of standards for personalization can solely enhance. To future-proof their workflow, GIR wanted to make sure that their answer might deal with the processing of huge quantities of information as an anticipated and frequent case.
GIR’s enterprise objective is to assist two sorts of workflows for classification standards: advert hoc and ongoing. An advert hoc standards causes customers that presently match the defining standards situation to instantly get tagged with the required persona, and is supposed to facilitate the one-time tagging of particular contacts. Alternatively, an ongoing standards is a steady course of that routinely tags customers with a persona if a change to their attributes causes them to suit the standards situation. The next diagram illustrates the specified personalization move:

In the remainder of this put up, we give attention to the design and implementation of GIR’s advert hoc workflow.
Apache Flink on Amazon EMR
To fulfill GIR’s scalability calls for, they decided that Amazon EMR was the most effective match for his or her use case, being a managed large information platform meant for processing massive quantities of information utilizing open supply applied sciences similar to Apache Flink. Though GIR evaluated a number of different choices that addressed their scalability issues (similar to AWS Glue), GIR selected Amazon EMR for its ease of integration into their present techniques and chance to be tailored for each batch and streaming workflows.
Apache Flink is an open supply large information distributed stream and batch processing engine that effectively processes information from steady occasions. Flink presents exactly-once ensures, excessive throughput and low latency, and is suited to dealing with large information streams. Additionally, Flink offers many easy-to-use APIs and mitigates the necessity for the programmer to fret about failures. Nonetheless, constructing and sustaining a pipeline primarily based on Flink comes with operational overhead and requires appreciable experience, along with provisioning bodily sources.
Amazon EMR empowers customers to create, function, and scale large information environments similar to Apache Flink shortly and cost-effectively. We will optimize prices through the use of Amazon EMR managed scaling to routinely enhance or lower the cluster nodes primarily based on workload. In GIR’s use case, their customers want to have the ability to set off persona-tagging operations at any time, and require a predictable completion time for his or her jobs. For this, GIR determined to launch a long-running cluster, which permits a number of Flink jobs to be submitted concurrently to the identical cluster.
Advert hoc persona-tagging infrastructure and workflow
The next diagram illustrates the structure of GIR’s advert hoc persona-tagging workflow on the AWS Cloud.
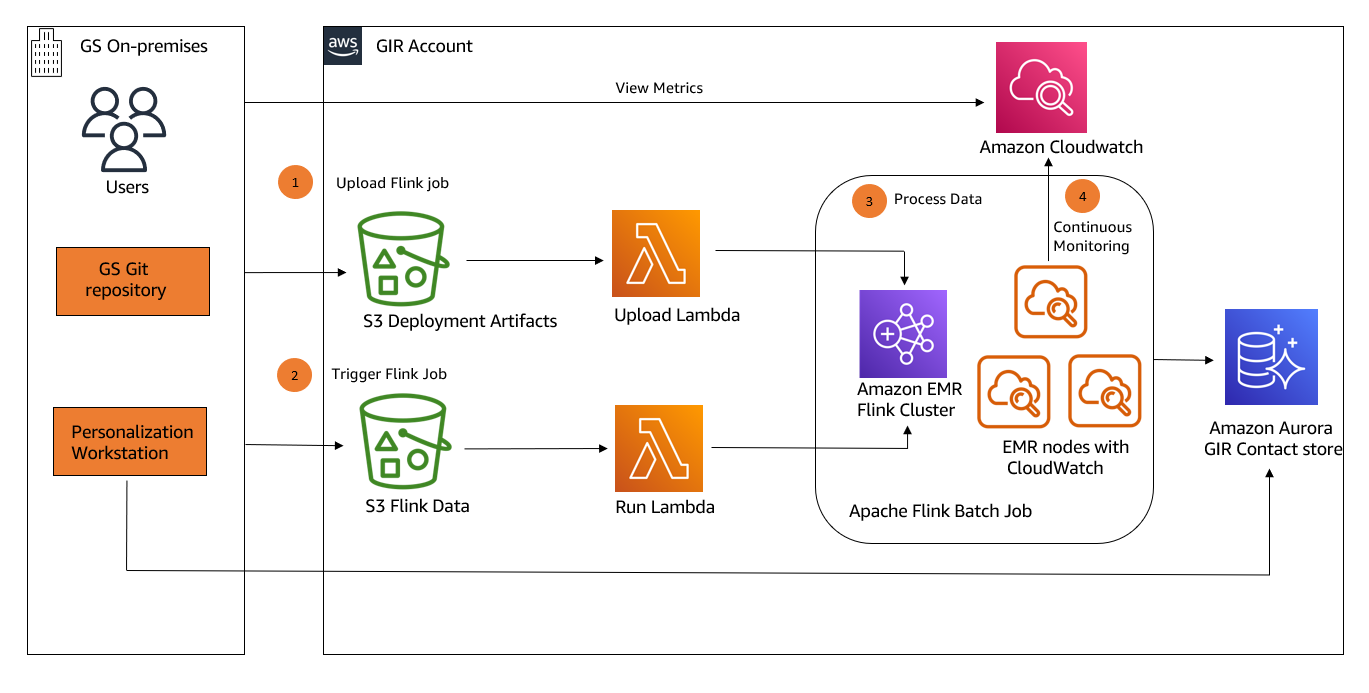
It is a broad overview, and the specifics of networking and safety between parts are out of scope for this put up.
At a excessive stage, we are able to talk about GIR’s workflow in 4 elements:
- Add the Flink job artifacts to the EMR cluster.
- Set off the Flink job.
- Throughout the Flink job, rework after which retailer person information.
- Steady monitoring.
You’ll be able to work together with Flink on Amazon EMR through the Amazon EMR console or the AWS Command Line Interface (AWS CLI). After launching the cluster, GIR used the Flink API to work together with and submit work to the Flink utility. The Flink API supplied a bit extra performance and was a lot simpler to invoke from an AWS Lambda utility.
The top objective of the setup is to have a pipeline the place GIR’s inner customers can freely make requests to replace contact information (which on this use case is tagging or untagging contacts with numerous personas), after which have the up to date contact information uploaded again to the GIR contact retailer.
Add the Flink job artifacts to Amazon EMR
GIR has a GitLab challenge on-premises for managing the contents of their Flink job. To set off the primary a part of their workflow and deploy a brand new model of the Flink job onto the cluster, a GitLab pipeline is run that first creates a .zip file containing the Flink job JAR file, properties, and config information.

The previous diagram depicts the sequence of occasions that happens within the job add:
- The GitLab pipeline is manually triggered when a brand new Flink job ought to be uploaded. This transfers the .zip file containing the Flink job to an Amazon Easy Storage Service (Amazon S3) bucket on the GIR AWS account, labeled as “S3 Deployment artifacts”.
- A Lambda operate (“Add Lambda”) is triggered in response to the create occasion from Amazon S3.
- The operate first uploads the Flink job JAR to the Amazon EMR Flink cluster, and retrieves the appliance ID for the Flink session.
- Lastly, the operate uploads the appliance properties file to a particular S3 bucket (“S3 Flink Job Properties”).
Set off the Flink job
The second a part of the workflow handles the submission of the particular Flink job to the cluster when job requests are generated. GIR has a user-facing internet app referred to as Personalization Workbench that gives the UI for finishing up persona-tagging operations. Admins and inner Goldman Sachs customers can assemble requests to tag or untag contacts with personas through this internet app. When a request is submitted, an information file is generated that incorporates the small print of the request.

The steps of this workflow are as follows:
- Personalization Workstation submits the small print of the job request to the Flink Knowledge S3 bucket, labeled as “S3 Flink information”.
- A Lambda operate (“Run Lambda”) is triggered in response to the create occasion from Amazon S3.
- The operate first reads the job properties file uploaded within the earlier step to get the Flink job ID.
- Lastly, the operate makes an API name to run the required Flink job.
Course of information
Contact information is processed based on the persona-tagging requests, and the reworked information is then uploaded again to the GIR contact retailer.

The steps of this workflow are as follows:
- The Flink job first reads the appliance properties file that was uploaded as a part of step one.
- Subsequent, it reads the information file from the second workflow that incorporates the contact and persona information to be up to date. The job then carries out the processing for the tagging or untagging operation.
- The outcomes are uploaded again to the GIR contact retailer.
- Lastly, each profitable and failed requests are written again to Amazon S3.
Steady monitoring
The ultimate a part of the general workflow includes steady monitoring of the EMR cluster with a view to be sure that GIR’s tagging workflow is steady and that the cluster is in a wholesome state. To make sure that the best stage of safety is maintained with their shopper information, GIR needed to keep away from unconstrained SSH entry to their AWS sources. Being constrained from accessing the EMR cluster’s major node immediately through SSH meant that GIR initially had no visibility into the EMR major node logs or the Flink internet interface.
By default, Amazon EMR archives the log information saved on the first node to Amazon S3 at 5-minute intervals. As a result of this pipeline serves as a central platform for processing many advert hoc persona-tagging requests at a time, it was essential for GIR to construct a correct steady monitoring system that will permit them to promptly diagnose any points with the cluster.
To perform this, GIR applied two monitoring options:
- GIR put in an Amazon CloudWatch agent onto each node of their EMR cluster through bootstrap actions. The CloudWatch agent collects and publishes Flink metrics to CloudWatch below a {custom} metric namespace, the place they are often considered on the CloudWatch console. GIR configured the CloudWatch agent configuration file to seize related metrics, similar to CPU utilization and complete working EMR situations. The result’s an EMR cluster the place metrics are emitted to CloudWatch at a a lot quicker price than ready for periodic S3 log flushes.
- In addition they enabled the Flink UI in read-only mode by fronting the cluster’s major node with a community load balancer and establishing connectivity from the Goldman Sachs on-premises community. This transformation allowed GIR to achieve direct visibility into the state of their working EMR cluster and in-progress jobs.
Observations, challenges confronted, and classes discovered
The personalization effort marked the first-time adoption of Amazon EMR inside GIR. Thus far, a whole bunch of personalization standards have been created in GIR’s manufacturing atmosphere. By way of internet visits and clickthrough price, web site engagement with GIR customized content material has steadily elevated for the reason that implementation of the persona-tagging system.
GIR confronted a number of noteworthy challenges throughout growth, as follows:
Restrictive safety group guidelines
By default, Amazon EMR creates its safety teams with guidelines which can be much less restrictive, as a result of Amazon EMR can’t anticipate the precise {custom} settings for ingress and egress guidelines required by particular person use instances. Nonetheless, correct administration of the safety group guidelines is important to guard the pipeline and information on the cluster. GIR used custom-managed safety teams for his or her EMR cluster nodes and included solely the wanted safety group guidelines for connectivity, with a view to fulfill this stricter safety posture.
Customized AMI
There have been challenges in making certain that the required packages had been accessible when utilizing {custom} Amazon Linux AMIs for Amazon EMR. As a part of Goldman Sachs growth SDLC controls, any Amazon Elastic Compute Cloud (Amazon EC2) situations on Goldman Sachs-owned AWS accounts are required to make use of inner Goldman Sachs-created AMIs. When GIR started growth, the one compliant AMI that was accessible below this management was a minimal AMI primarily based on the publicly accessible Amazon Linux 2 minimal AMI (amzn2-ami-minimal*-x86_64-ebs). Nonetheless, Amazon EMR recommends utilizing the total default Amazon 2 Linux AMI as a result of it has all the required packages pre-installed. This resulted in numerous begin up errors with no clear indication of the lacking libraries.
GIR labored with AWS assist to determine and resolve the difficulty by evaluating the minimal and full AMIs, and putting in the 177 lacking packages individually (see the appendix for the total record of packages). As well as, numerous AMI-related information had been set to read-only permissions by the Goldman Sachs inner AMI creation course of. Restoring these permissions to full learn/write entry allowed GIR to efficiently begin up their cluster.
Stalled Flink jobs
Throughout GIR’s preliminary manufacturing rollout, GIR skilled a difficulty the place their EMR cluster failed silently and brought about their Lambda features to day out. On additional debugging, GIR discovered this situation to be associated to an Akka quarantine-after-silence timeout setting. By default, it was set to 48 hours, inflicting the clusters to refuse extra jobs after that point. GIR discovered a workaround by setting the worth of akka.jvm-exit-on-fatal-error to false within the Flink config file.
Conclusion
On this put up, we mentioned how the GIR workforce at Goldman Sachs arrange a system utilizing Apache Flink on Amazon EMR to hold out the tagging of customers with numerous personas, with a view to higher curate content material choices for these customers. We additionally coated among the challenges that GIR confronted with the setup of their EMR cluster. This represents an vital first step in offering GIR’s customers with full customized content material curation primarily based on their particular person profiles and readership.
Acknowledgments
The authors wish to thank the next members of the AWS and GIR groups for his or her shut collaboration and steerage on this put up:
- Elizabeth Byrnes, Managing Director, GIR
- Moon Wang, Managing Director, GIR
- Ankur Gurha, Vice President, GIR
- Jeremiah O’Connor, Options Architect, AWS
- Ley Nezifort, Affiliate, GIR
- Shruthi Venkatraman, Analyst, GIR
Concerning the Authors
 Balasubramanian Sakthivel is a Vice President at Goldman Sachs in New York. He has greater than 16 years of expertise management expertise and labored on many firmwide entitlement, authentication and personalization tasks. Bala drives the International Funding Analysis division’s shopper entry and information engineering technique, together with structure, design and practices to allow the strains of enterprise to make knowledgeable selections and drive worth. He’s an innovator in addition to an skilled in creating and delivering massive scale distributed software program that solves actual world issues, with demonstrated success envisioning and implementing a broad vary of extremely scalable platforms, merchandise and structure.
Balasubramanian Sakthivel is a Vice President at Goldman Sachs in New York. He has greater than 16 years of expertise management expertise and labored on many firmwide entitlement, authentication and personalization tasks. Bala drives the International Funding Analysis division’s shopper entry and information engineering technique, together with structure, design and practices to allow the strains of enterprise to make knowledgeable selections and drive worth. He’s an innovator in addition to an skilled in creating and delivering massive scale distributed software program that solves actual world issues, with demonstrated success envisioning and implementing a broad vary of extremely scalable platforms, merchandise and structure.
 Victor Gan is an Analyst at Goldman Sachs in New York. Victor joined the International Funding Analysis division in 2020 after graduating from Cornell College, and has been accountable for creating and provisioning cloud infrastructure for GIR’s person entitlement techniques. He’s targeted on studying new applied sciences and streamlining cloud techniques deployments.
Victor Gan is an Analyst at Goldman Sachs in New York. Victor joined the International Funding Analysis division in 2020 after graduating from Cornell College, and has been accountable for creating and provisioning cloud infrastructure for GIR’s person entitlement techniques. He’s targeted on studying new applied sciences and streamlining cloud techniques deployments.
 Manjula Nagineni is a Options Architect with AWS primarily based in New York. She works with main Monetary service establishments, architecting, and modernizing their large-scale functions whereas adopting AWS cloud companies. She is enthusiastic about designing large information workloads cloud-natively. She has over 20 years of IT expertise in Software program Improvement, Analytics and Structure throughout a number of domains similar to finance, manufacturing and telecom.
Manjula Nagineni is a Options Architect with AWS primarily based in New York. She works with main Monetary service establishments, architecting, and modernizing their large-scale functions whereas adopting AWS cloud companies. She is enthusiastic about designing large information workloads cloud-natively. She has over 20 years of IT expertise in Software program Improvement, Analytics and Structure throughout a number of domains similar to finance, manufacturing and telecom.
Appendix
GIR ran the next command to put in the lacking AMI packages:
[ad_2]