

{kind=link}
[ad_1]
Amazon Redshift is a quick, scalable, safe, and absolutely managed cloud knowledge warehouse that makes it easy and cost-effective to investigate all of your knowledge utilizing normal SQL. Amazon Redshift affords as much as thrice higher value efficiency than every other cloud knowledge warehouse. Tens of hundreds of consumers use Amazon Redshift to course of exabytes of knowledge per day and energy analytics workloads resembling high-performance enterprise intelligence (BI) reporting, dashboarding functions, knowledge exploration, and real-time analytics.
Loading knowledge is a key course of for any analytical system, together with Amazon Redshift. Loading very giant datasets can take a very long time and eat a whole lot of computing assets. How your knowledge is loaded may have an effect on question efficiency. You should utilize many various strategies to load knowledge into Amazon Redshift. One of many quickest and most scalable strategies is to make use of the COPY command. This submit dives into among the latest enhancements made to the COPY command and the right way to use them successfully.
Overview of the COPY command
A finest observe for loading knowledge into Amazon Redshift is to make use of the COPY command. The COPY command hundreds knowledge in parallel from Amazon Easy Storage Service (Amazon S3), Amazon EMR, Amazon DynamoDB, or a number of knowledge sources on any distant hosts accessible via a Safe Shell (SSH) connection.
The COPY command reads and hundreds knowledge in parallel from a file or a number of information in an S3 bucket. You possibly can take most benefit of parallel processing by splitting your knowledge into a number of information, in instances the place the information are compressed. The COPY command appends the brand new enter knowledge to any current rows within the goal desk. The COPY command can load knowledge from Amazon S3 for the file codecs AVRO, CSV, JSON, and TXT, and for columnar format information resembling ORC and Parquet.
Use COPY with FILLRECORD
In conditions when the contiguous fields are lacking on the finish of among the data for knowledge information being loaded, COPY stories an error indicating that there’s mismatch between the variety of fields within the file being loaded and the variety of columns within the goal desk. In some conditions, columnar information (resembling Parquet) which are produced by functions and ingested into Amazon Redshift by way of COPY could have further fields added to the information (and new columns to the goal Amazon Redshift desk) over time. In such instances, these information could have values absent for sure newly added fields. To load these information, you beforehand needed to both preprocess the information to refill values within the lacking fields earlier than loading the information utilizing the COPY command, or use Amazon Redshift Spectrum to learn the information from Amazon S3 after which use INSERT INTO to load knowledge into the Amazon Redshift desk.
With the FILLRECORD parameter, now you can load knowledge information with a various variety of fields efficiently in the identical COPY command, so long as the goal desk has all columns outlined. The FILLRECORD parameter addresses ease of use as a result of now you can instantly use the COPY command to load columnar information with various fields into Amazon Redshift as an alternative of reaching the identical end result with a number of steps.
With the FILLRECORD parameter, lacking columns are loaded as NULLs. For textual content and CSV codecs, if the lacking column is a VARCHAR column, zero-length strings are loaded as an alternative of NULLs. To load NULLs to VARCHAR columns from textual content and CSV, specify the EMPTYASNULL key phrase. NULL substitution solely works if the column definition permits NULLs.
Use FILLRECORD whereas loading Parquet knowledge from Amazon S3
On this part, we reveal the utility of FILLRECORD by utilizing a Parquet file that has a smaller variety of fields populated than the variety of columns within the goal Amazon Redshift desk. First we attempt to load the file into the desk with out the FILLRECORD parameter within the COPY command, then we use the FILLRECORD parameter within the COPY command.
For the aim of this demonstration, now we have created the next parts:
- An Amazon Redshift cluster with a database, public schema, awsuser as admin person, and an AWS Id and Entry Administration (IAM) position, used to carry out the COPY command to load the file from Amazon S3, connected to the Amazon Redshift cluster. For particulars on authorizing Amazon Redshift to entry different AWS providers, seek advice from Authorizing Amazon Redshift to entry different AWS providers in your behalf.
- An Amazon Redshift desk named
call_center_parquet. - A Parquet file already uploaded to an S3 bucket from the place the file is copied into the Amazon Redshift cluster.
The next code is the definition of the call_center_parquet desk:
The desk has 31 columns.
The Parquet file doesn’t comprise any worth for the cc_gmt_offset and cc_tax_percentage fields. It has 29 columns. The next screenshot exhibits the schema definition for the Parquet file situated in Amazon S3, which we load into Amazon Redshift.
We ran the COPY command two alternative ways: with or with out the FILLRECORD parameter.
We first tried to load the Parquet file into the call_center_parquet desk with out the FILLRECORD parameter:
It generated an error whereas performing the copy.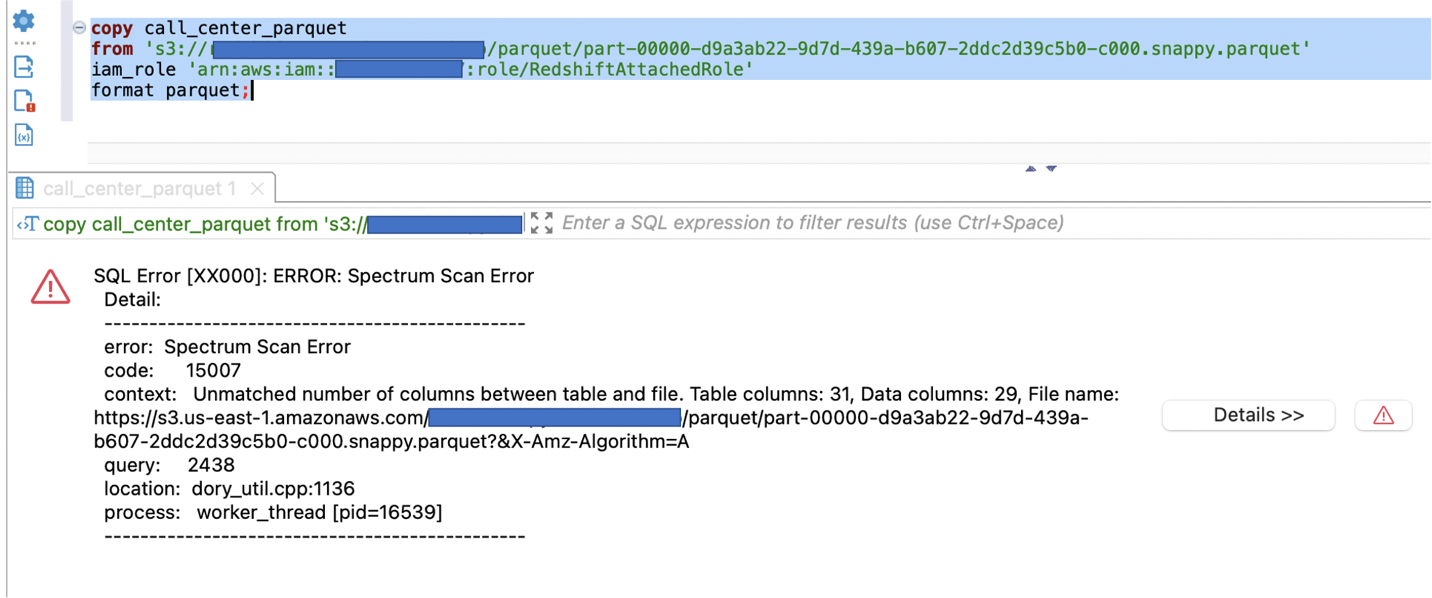
Subsequent, we tried to load the Parquet file into the call_center_parquet desk and used the FILLRECORD parameter:
The Parquet knowledge was loaded efficiently within the call_center_parquet desk, and NULL was entered into the cc_gmt_offset and cc_tax_percentage columns.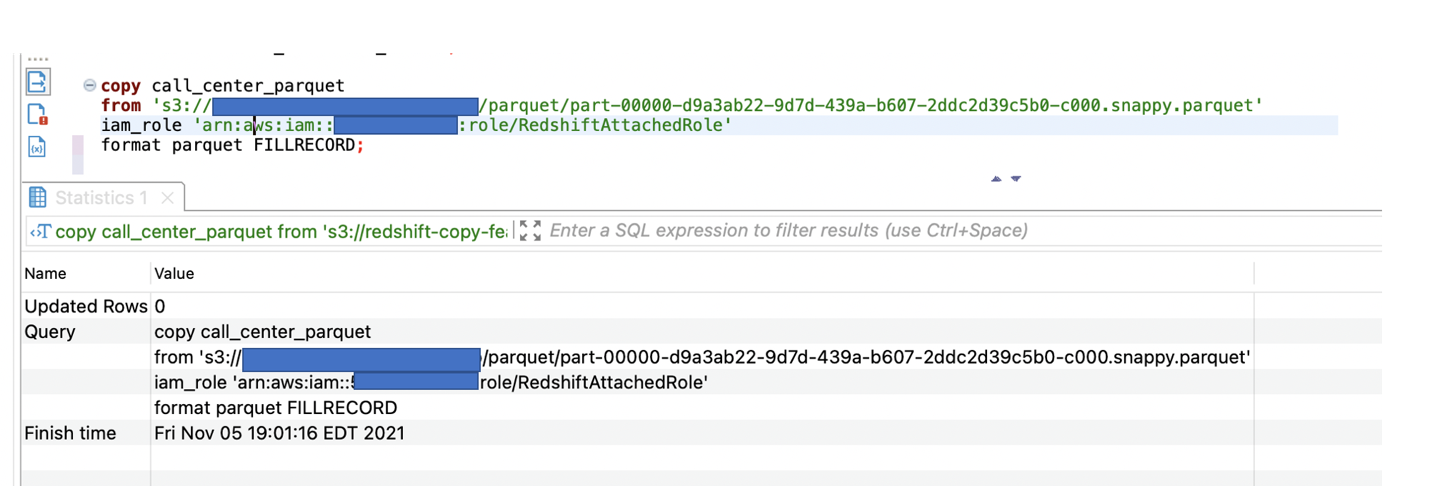
Break up giant textual content information whereas copying
The second new function we talk about on this submit is robotically splitting giant information to make the most of the large parallelism of the Amazon Redshift cluster. A finest observe when utilizing the COPY command in Amazon Redshift is to load knowledge utilizing a single COPY command from a number of knowledge information. This hundreds knowledge in parallel by dividing the workload among the many nodes and slices within the Amazon Redshift cluster. When all the information from a single file or small variety of giant information is loaded, Amazon Redshift is compelled to carry out a a lot slower serialized load, as a result of the Amazon Redshift COPY command can’t make the most of the parallelism of the Amazon Redshift cluster. You must write further preprocessing steps to separate the big information into smaller information in order that the COPY command hundreds knowledge in parallel into the Amazon Redshift cluster.
The COPY command now helps robotically splitting a single file into a number of smaller scan ranges. This function is at present supported just for giant uncompressed delimited textual content information. Extra file codecs and choices, resembling COPY with CSV key phrase, shall be added within the close to future.
This helps enhance efficiency for COPY queries when loading a small variety of giant uncompressed delimited textual content information into your Amazon Redshift cluster. Scan ranges are carried out by splitting the information into 64 MB chunks, which get assigned to every Amazon Redshift slice. This variation addresses ease of use since you don’t want to separate giant uncompressed textual content information as an extra preprocessing step.
With Amazon Redshift’s capability to separate giant uncompressed textual content information, you may see efficiency enhancements for the COPY command with a single giant file or a couple of information with considerably various relative sizes (for instance, one file 5 GB in dimension and 20 information of some KBs). Efficiency enhancements for the COPY command are extra vital because the file dimension will increase even with preserving the identical Amazon Redshift cluster configuration. Primarily based on exams accomplished, we noticed a greater than 1,500% efficiency enchancment for the COPY command for loading a 6 GB uncompressed textual content file when the auto splitting function turned obtainable.
There aren’t any adjustments within the COPY question or key phrases to allow this variation, and splitting of information is robotically utilized for the eligible COPY instructions. Splitting isn’t relevant for the COPY question with the key phrases CSV, REMOVEQUOTES, ESCAPE, and FIXEDWIDTH.
For the check, we used a single 6 GB uncompressed textual content file and the next COPY command:
The Amazon Redshift cluster with out the auto break up possibility took 102 seconds to repeat the file from Amazon S3 to the Amazon Redshift store_sales desk. When the auto break up possibility was enabled within the Amazon Redshift cluster (with out every other configuration adjustments), the identical 6 GB uncompressed textual content file took simply 6.19 seconds to repeat the file from Amazon S3 to the store_sales desk.
Abstract
On this submit, we confirmed two enhancements to the Amazon Redshift COPY command. First, we confirmed how one can add the FILLRECORD parameter within the COPY command as a way to efficiently load knowledge information even when the contiguous fields are lacking on the finish of among the data, so long as the goal desk has all of the columns. Secondly, we described how Amazon Redshift auto splits giant uncompressed textual content information into 64 MB chunks earlier than copying the information into the Amazon Redshift cluster to boost COPY efficiency. This automated break up of enormous information lets you use the COPY command on giant uncompressed textual content information—Amazon Redshift auto splits the file without having you so as to add a preprocessing step to the break up the big information your self. Strive these options to make your knowledge loading to Amazon Redshift a lot less complicated by eradicating customized preprocessing steps.
In Half 2 of this collection, we are going to talk about further new options of Amazon Redshift COPY command and reveal how one can take advantages of these to optimize your knowledge loading course of.
Concerning the Authors
 Dipankar Kushari is a Senior Analytics Options Architect with AWS.
Dipankar Kushari is a Senior Analytics Options Architect with AWS.
 Cody Cunningham is a Software program Growth Engineer with AWS, engaged on knowledge ingestion for Amazon Redshift.
Cody Cunningham is a Software program Growth Engineer with AWS, engaged on knowledge ingestion for Amazon Redshift.
 Joe Yong is a Senior Technical Product Supervisor on the Amazon Redshift crew and a relentless pursuer of constructing advanced database applied sciences straightforward and intuitive for the plenty. He has labored on database and knowledge administration programs for SMP, MPP, and distributed programs. Joe has shipped dozens of options for on-premises and cloud-native databases that serve IoT gadgets via petabyte-sized cloud knowledge warehouses. Off keyboard, Joe tries to onsight 5.11s, hunt for good eats, and search a treatment for his Australian Labradoodle’s obsession with squeaky tennis balls.
Joe Yong is a Senior Technical Product Supervisor on the Amazon Redshift crew and a relentless pursuer of constructing advanced database applied sciences straightforward and intuitive for the plenty. He has labored on database and knowledge administration programs for SMP, MPP, and distributed programs. Joe has shipped dozens of options for on-premises and cloud-native databases that serve IoT gadgets via petabyte-sized cloud knowledge warehouses. Off keyboard, Joe tries to onsight 5.11s, hunt for good eats, and search a treatment for his Australian Labradoodle’s obsession with squeaky tennis balls.
 Anshul Purohit is a Software program Growth Engineer with AWS, engaged on knowledge ingestion and question processing for Amazon Redshift.
Anshul Purohit is a Software program Growth Engineer with AWS, engaged on knowledge ingestion and question processing for Amazon Redshift.
[ad_2]