

{kind=link}
[ad_1]
It’s been an thrilling previous few years with the Delta Lake mission. The discharge of Delta Lake 1.0 as introduced by Michael Armbrust within the Knowledge+AI Summit in Could 2021 represents an incredible milestone for the open supply group and we’re simply getting began! To raised streamline group involvement and ask, we lately revealed Delta Lake 2021 H2 Roadmap and related Delta Lake Person Survey (2021 H2) – the results of which we are going to talk about in a future weblog. On this weblog, we overview the foremost options launched thus far and supply an summary of the upcoming roadmap.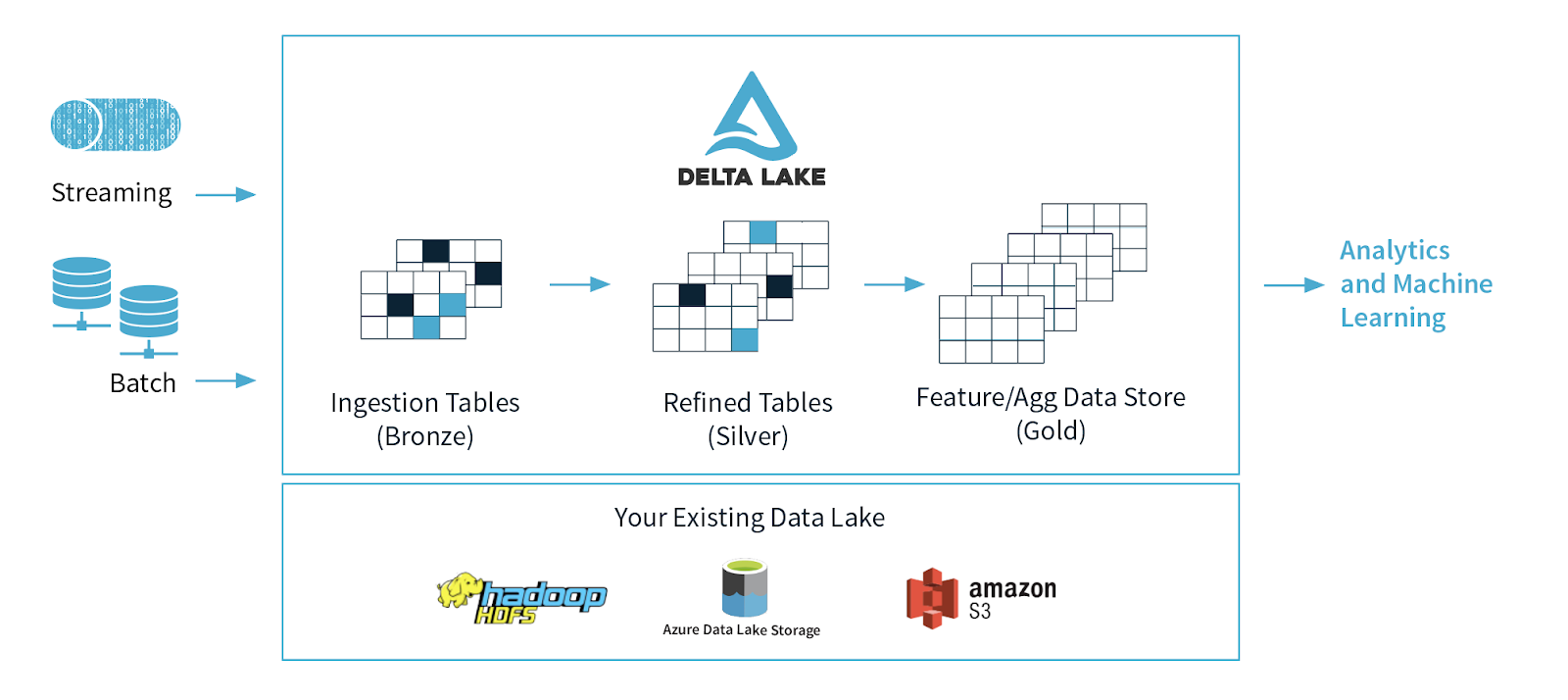
Let’s first begin with what Delta Lake is. Delta Lake is an open-source mission that permits constructing a Lakehouse structure on prime of your present storage programs comparable to S3, ADLS, GCS, and HDFS. The options of Delta Lake enhance each the manageability and efficiency of working with knowledge in cloud storage objects and allow the lakehouse paradigm that mixes the important thing options of information warehouses and knowledge lakes: commonplace DBMS administration features usable towards low-cost object shops. Along with the multi-hop Delta medallion structure knowledge high quality framework, Delta Lake ensures the reliability of your batch and streaming knowledge with ACID transactions.
Delta Lake adoption
At the moment, Delta Lake is used everywhere in the world. Exabytes of information get processed every day on Delta Lake, which accounts for 75% of the information that’s scanned on the Databricks Platform alone. Furthermore, Delta Lake has been deployed to greater than 3000 clients of their manufacturing lakehouse architectures on Databricks alone!
Delta Lake tempo of innovation highlights
The journey to Delta Lake 1.0 has been filled with innovation highlights – so how did we get right here?

As Michael highlighted in his keynote on the Knowledge + AI Summit 2021, the Delta Lake mission was initially created at Databricks primarily based on buyer suggestions again in 2017. By means of steady collaboration efforts with early adopters, Delta Lake was open-sourced in 2019 and was introduced on the Spark+AI Summit keynote by Ali Ghodsi. The primary launch Delta Lake 0.1 included ACID transactions, schema administration, and unified streaming and batch supply and sink. Model 0.4 included the help for DML instructions and vacuuming for each Scala and Python APIs have been added. In model 0.5, Delta Lake noticed enhancements round compaction and concurrency. It was doable to transform Parquet into Delta Lake tables utilizing SQL solely. Different issues added within the subsequent model, 0.6, have been enhancements round merge operations and describe historical past, which lets you perceive how your desk has been evolving over time. In 0.7, the help for various engines like Presto and Athena through manifest era was added. And at last, numerous work went into including merge and different options within the 0.8 launch.
To dive deeper into every of those improvements, please take a look at the blogs beneath for every of those releases.
Delta Lake 1.0
The Delta Lake 1.0 launch was licensed by the group in Could 2021 and was introduced on the Knowledge and AI summit with a set of recent options that make Delta Lake accessible all over the place.
Let’s undergo every of the options that made it into the 1.0 launch.

The important thing themes of the discharge coated as a part of the ’Asserting Delta Lake 1.0’ keynote will be damaged down into the next:
- Generated Columns
- Multi-cluster writes
- Cloud Independence
- Apache Spark™ 3.1 help
- PyPI Set up
- Delta In all places
- Connectors
Generated columns
A typical drawback when working with distributed programs is the way you partition your knowledge to higher manage your knowledge for ingestion and querying. A typical method is to partition your knowledge by date, as this permits your ingestion to naturally manage the information as new knowledge arrives, in addition to question the information by date vary.
The issue with this method is that more often than not, your knowledge column is within the type of a timestamp; if you happen to have been to partition by a timestamp, this is able to lead to too many partitions. To partition by date (as a substitute of by milliseconds), you may manually create a date column that’s calculated by the insert. The creation of this derived column would require you to manually create columns and manually add predicates; this course of is error-prone and will be simply forgotten.
A greater answer is to create generated columns, that are a particular kind of columns whose values are routinely generated primarily based on a user-specified perform over different columns that exist already in your Delta desk. Once you write to a desk with generated columns, and you don’t explicitly present values for them, Delta Lake routinely computes the values. For instance, you may routinely generate a date column (for partitioning the desk by date) from the timestamp column; any writes into the desk want solely specify the information for the timestamp column.
This may be finished utilizing commonplace SQL syntax to simply help your lakehouse.
CREATE TABLE occasions(
id bigint,
eventTime timestamp,
eventDate GENERATED ALWAYS AS (
CAST(eventTime AS DATE)
)
)
USING delta
PARTITIONED BY (eventDate)
Cloud independence
Out of the field, Delta Lake has at all times labored with a wide range of storage programs – Hadoop HDFS, Amazon S3, Azure Knowledge Lake Storage (ADLS) Gen2 – although the cluster would beforehand be particular for one storage system.
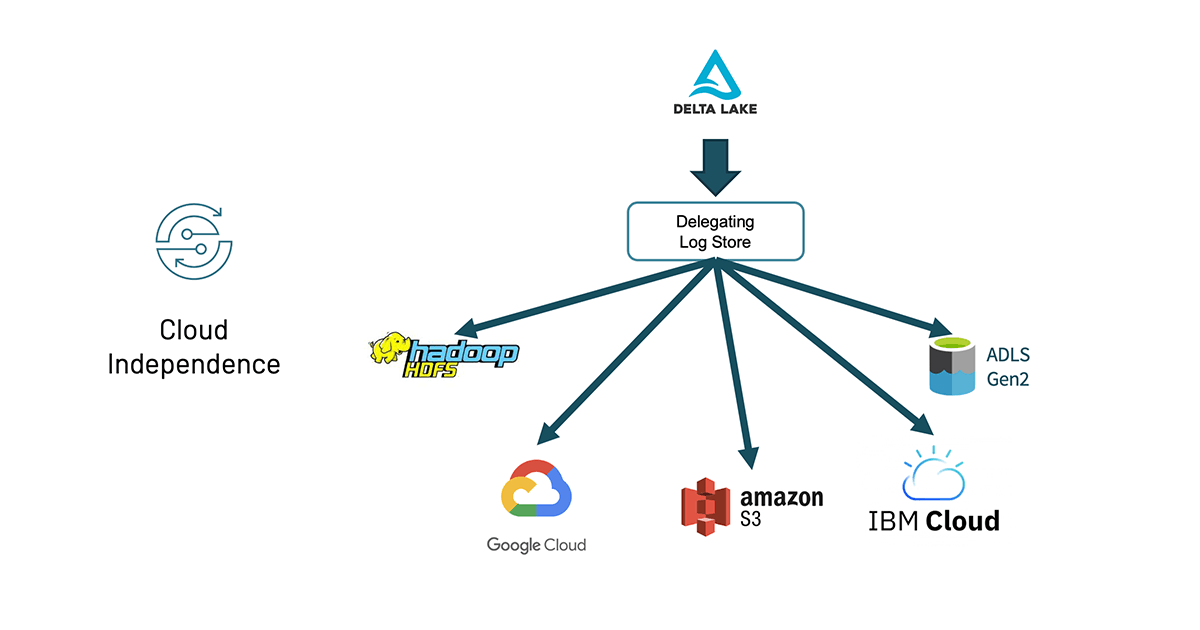
Now, with Delta Lake 1.0 and the DelegatingLogStore, you may have a single cluster that reads and writes from completely different storage programs. This implies you are able to do federated querying throughout knowledge saved in a number of clouds or use this for cross-region consolidation. On the identical time, the Delta group has been extending help for added filesystems, together with IBM Cloud and Google Cloud Storage (GCS) and Oracle Cloud Infrastructure. For extra info, please consult with Storage configuration — Delta Lake Documentation.
Multi-cluster transactions
Delta Lake has at all times had help for a number of clusters writing to a single desk – mediating the updates with an ACID transaction protocol, stopping conflicts. This has labored on Hadoop HDFS, ADLS Gen2, and now Google Cloud Storage. AWS S3 is lacking the transactional primitives wanted to construct this performance with out relying on exterior programs.

Now, in Delta Lake 1.0, open-source contributors from Scribd and Samba TV are including help within the Delta transaction protocol to make use of Amazon DynamoDB to mediate between a number of writers of Amazon S3 endpoints. Now, a number of Delta Lake clusters can learn and write from the identical desk.
Delta Standalone reader
Beforehand Delta Lake was just about an Apache Spark mission — nice integration with streaming and batch APIs to learn and write from Delta tables. Whereas Apache Spark is built-in seamlessly with Delta, there are a bunch of various engines on the market and a wide range of causes you may need to use them.
With the Delta Standalone reader, we’ve created an implementation for the JVM that understands the Delta transaction protocol however doesn’t depend on an Apache Spark cluster. This makes it considerably simpler to construct help for different engines. We already use the Delta Standalone reader on the Hive connector, and there’s work underway for a Presto connector as nicely.
Delta Lake Rust implementation
The Delta Rust implementation helps write transactions (although that has not but been carried out within the different languages).

Now that we’ve acquired nice Python help it’s essential to make it simpler for Python customers to get began. There are two completely different packages relying on the way you’re going to be utilizing Delta Lake from Python:
- If you wish to use it together with Apache Spark, you may pip set up delta-spark, and it’ll arrange every little thing it’s worthwhile to run Apache Spark jobs towards your Delta Lake
- In the event you’re going to be working with smaller knowledge, use pandas, or use another library; you not want to make use of Apache Spark to entry Delta tables from Python. Customers can use pip set up deltalake command to put in the Delta Rust API with Python bindings.
Delta Lake 1.0 helps Apache Spark 3.1
The Apache Spark group has made numerous enhancements round efficiency and compatibility. And it’s tremendous essential that Delta Lake retains updated with that innovation.
This implies you could benefit from elevated efficiency in predicate pushdowns and pruning which can be accessible in Apache Spark 3.1. Moreover, Delta Lake integration with Apache Spark streaming catalog APIs ensures Delta tables accessible for streaming are current within the catalog with out manually dealing with the trail metadata.

Spark 3.1 Help
Delta Lake all over the place
With the introduction of all of the options that we walked by way of above, Delta is now accessible all over the place you might need to use it. This mission has come a extremely great distance, and that is what the ecosystem of Delta seems like now.

- Languages: Native code for working with a Delta Lake makes it simple to make use of your knowledge from a wide range of languages. Delta Lake now has the Python, Kafka, and Ruby help utilizing Rust bindings.
- Providers: Delta Lake is obtainable from a wide range of providers, together with Databricks, Azure Synapse Analytics, Google DataProc, Confluent Cloud, and Oracle.
- Connectors: There are connectors for the entire in style instruments for knowledge engineers, due to native help for Delta Lake (standalone reader), by way of which knowledge will be simply queried from many alternative databases with out the necessity for any manifest recordsdata.
- Databases: Delta Lake can also be queryable from many alternative databases. You possibly can entry Delta tables from Apache Spark and different database programs.
Delta Lake OSS: 2021 H2 Roadmap
The next are a few of the highlights from the ever-expanding Delta Lake ecosystem. For extra info, consult with Delta Lake Roadmap 2021 H2: Options Overview by Vini and Denny
The next are some key highlights of the present Delta Lake ecosystem roadmap.
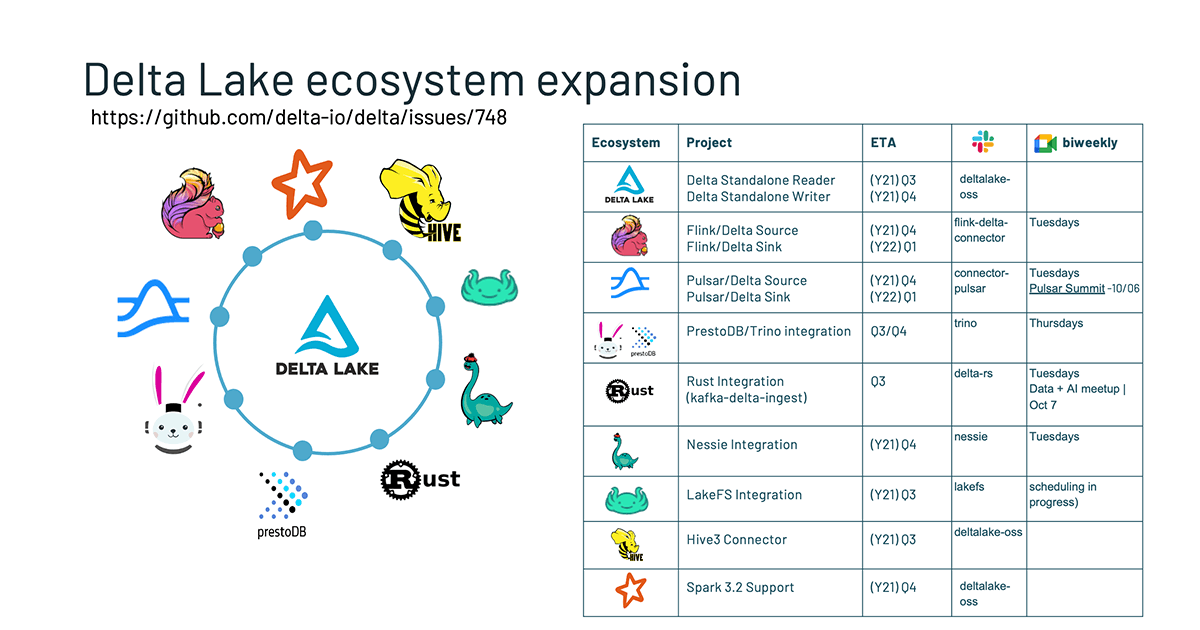
Delta Standalone
The very first thing within the roadmap that we need to spotlight is the Delta Standalone.
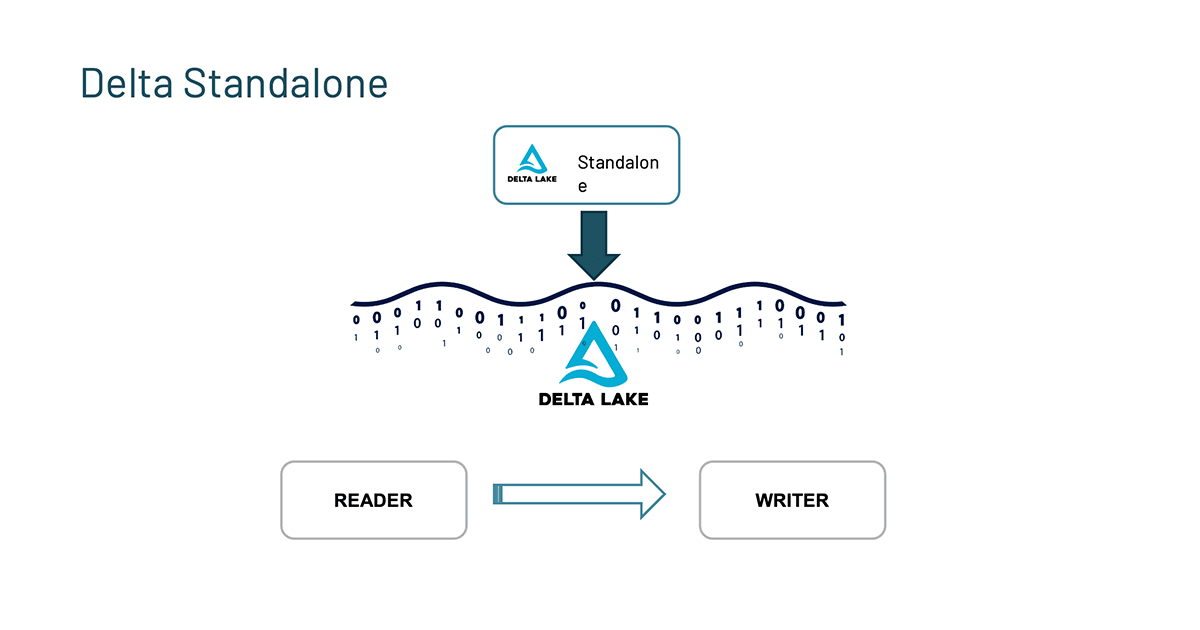
Within the Delta Lake 1.0 overview, we coated the Delta Standalone Reader which permits different engines to learn from Delta Lake instantly with out counting on an Apache Spark cluster. Given the demand for write capabilities, the Delta Standalone Author was the pure subsequent step. Thus, work is underway to construct Delta Standalone Author (DSW #85) that permits builders to write down to Delta tables with out Apache Spark. It allows builders to construct connectors so different streaming engines like Flink, Kafka, and Pulsar can write to Delta tables. For extra info, consult with the [2021-09-13] Delta Standalone Author Design Doc.
Flink/Delta sink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded knowledge streams. The most typical forms of functions which can be powered by Flink are event-driven, knowledge analytics, and knowledge pipeline functions. At the moment, the group is engaged on a Flink/Delta Sink (#111) utilizing the upcoming Delta Standalone Author to permit Flink to write down to Delta tables.
If you’re , you may take part in lively discussions on slack #flink-delta-connector or by way of bi-weekly conferences on Tuesdays.
Pulsar/Delta connector
Pulsar is an open-source streaming mission that was initially constructed at Yahoo! as a streaming platform. The Delta group is bringing streaming enhancements to the Delta Standalone Reader to help Pulsar. There are two connectors which can be being labored on – one for studying from the Delta desk as a supply and one other writing to the Delta desk as a sink (#112). This can be a group effort, and there’s an lively slack group you could be a part of through the Delta Customers Slack #connector-pulsar channel or take part in biweekly Tuesdays. For extra info, take a look at the latest Pulsar EU summit the place Ryan Zhu and Addison Higham have been keynote audio system.

Trino/Delta connector
Trino is an ANSI SQL compliant question engine that works with BI instruments comparable to R, Tableau, Energy BI, Superset, and many others. The group is engaged on a Trino/Delta reader leveraging the Delta Standalone Reader. This can be a group effort, and all are welcome. Be part of us through the Delta Person Slack channel #trino channel, and we may have bi-weekly conferences on Thursdays.
PrestoDB/Delta connector
Presto is an open-source distributed SQL question engine for working interactive analytic queries
Presto Delta reader will permit Presto to learn from Delta tables. It’s a group effort, and you may be a part of the slack #connector-presto. We even have bi-weekly conferences on Thursdays.
Kafka-delta-ingest
delta-rs is a library that gives low-level entry to Delta tables in Rust which presently help Python, Kafka, and Ruby bindings. The Rust implementation helps write transactions, and the kafka-delta-ingest mission lately went into manufacturing as famous within the following tech speak: Tech Speak | Diving into Delta-rs: kafka-delta-ingest.
You may as well take part within the discussions by becoming a member of slack #kafka-delta-ingest or biweekly Tuesday conferences.
Hive 3 connector
Hive to delta connector is a library to make Hive learn Delta Lake tables. We’re updating the present Hive 2 connector similar to Delta Standalone Reader to help Hive 3. To take part, you may be a part of the Delta Slack channel or attend our month-to-month core Delta workplace hours.
Spark enhancements
We’ve seen an incredible tempo of innovation in Apache Spark, and with that, we now have two most important issues arising within the roadmap.
- Help for Apache Spark’s column drop and rename instructions
- Help Apache Spark 3.2
Delta Sharing
One other highly effective function of Delta Lake is Delta Sharing. There’s a rising demand to share knowledge past the partitions of the group with exterior entities. Customers are pissed off by the constraints to how they’ll share their knowledge and as soon as that knowledge is shared, model management and knowledge freshness are tough to keep up. For instance, take a bunch of information scientists who’re collaborating. They’re within the circulate and on the verge of perception however want to research one other knowledge set. In order that they submit a ticket and wait. Within the two or extra weeks it takes them to get that lacking knowledge set, time is misplaced, situations change, and momentum stalls. Knowledge sharing shouldn’t be a barrier to innovation. That is why we’re enthusiastic about Delta Sharing, which is the business’s first open protocol for safe knowledge sharing, making it easy to share knowledge with different organizations no matter which computing platforms they use.
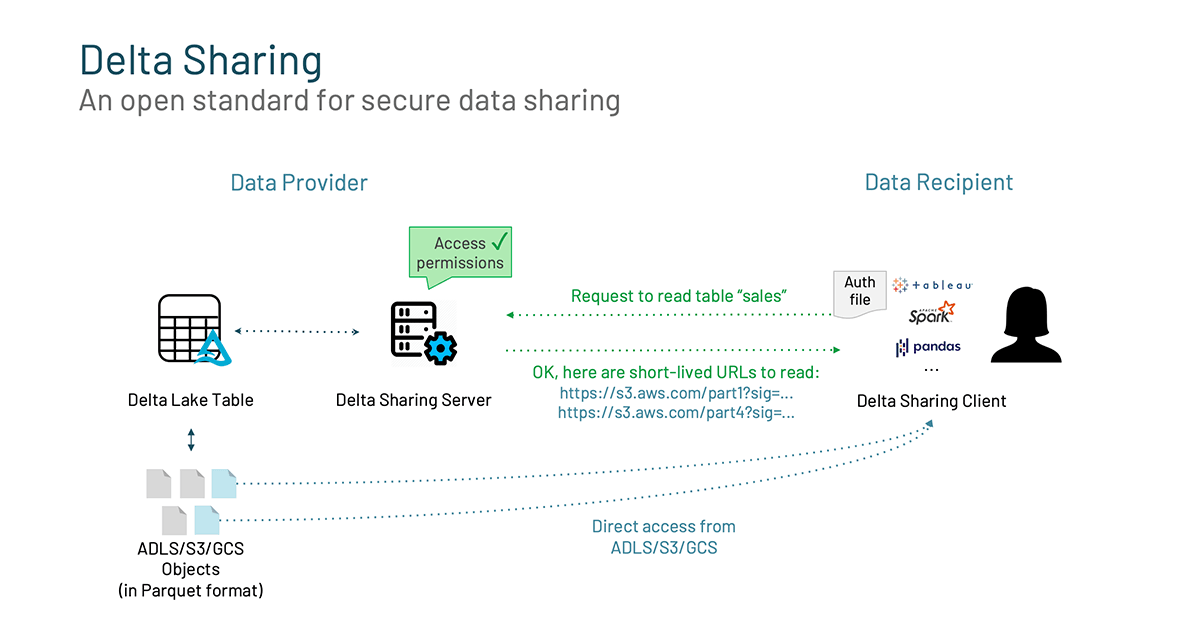
Delta Sharing means that you can:
- Share reside knowledge instantly: Simply share present, reside knowledge in your Delta Lake with out copying it to a different system.
- Help numerous purchasers: Knowledge recipients can instantly connect with Delta Shares from Pandas, Apache Spark™, Rust, and different programs with out having to first deploy a particular compute platform. Scale back the friction to get your knowledge to your customers.
- Safety and governance: Delta Sharing means that you can simply govern, observe, and audit entry to your shared knowledge units.
- Scalability: Share terabyte-scale datasets reliably and effectively by leveraging cloud storage programs like S3, ADLS, and GCS.
Delta Lake committers
Because the Delta Lake mission is community-driven and with that, we need to spotlight a bunch of recent Delta Lake committers from many alternative firms. Specifically, we need to spotlight the contributions of QP Hou , R. Tyler Croy, Christian Williams, and Mykhailo Osypov from Scribd and Florian Valeye from Again Marketto delta.rs, kafka-delta-ingest, sql-delta-import, and the Delta group.

Delta Lake roadmap in a nutshell
Placing all of it collectively — we reviewed how the Delta Lake group is quickly increasing from connectors to committers. To study extra about Delta Lake, take a look at the Delta Lake Definitive Information, a brand new O’Reilly e book accessible in Early Launch at no cost.
Tips on how to interact within the Delta Lake mission
We encourage you to become involved within the Delta group by way of Slack, Google Teams, GitHub, and extra.

Our lately closed Delta Lake survey obtained over 600 responses. We shall be analyzing and publishing the survey outcomes to assist information the Delta Lake group. For these of you who want to present your suggestions, please be a part of one of many many Delta group boards.
For those who accomplished the survey, you’ll obtain Delta swag and get an opportunity to win a tough copy of the upcoming Delta Lake Definitive Information authored by TD, Denny, and Vini (you may obtain the uncooked, unedited early preview now)!

Early Launch of Delta Lake: The Definitive Information
With that, we need to conclude the weblog with a quote from R. Tyler Croy, Director of Platform Engineering, Scribd:
“With Delta Lake 1.0, Delta Lake is now prepared for each workload!
[ad_2]