
[ad_1]
An method generally used to coach brokers for a variety of purposes from robotics to chip design is reinforcement studying (RL). Whereas RL excels at discovering resolve duties from scratch, it may well battle in coaching an agent to know the reversibility of its actions, which will be essential to make sure that brokers behave in a protected method inside their setting. For example, robots are typically expensive and require upkeep, so one needs to keep away from taking actions which may result in damaged parts. Estimating if an motion is reversible or not (or higher, how simply it may be reversed) requires a working data of the physics of the setting by which the agent is working. Nonetheless, in the usual RL setting, brokers don’t possess a mannequin of the setting adequate to do that.
In “There Is No Turning Again: A Self-Supervised Method to Reversibility-Conscious Reinforcement Studying”, accepted at NeurIPS 2021, we current a novel and sensible method of approximating the reversibility of agent actions within the context of RL. This method, which we name Reversibility-Conscious RL, provides a separate reversibility estimation element to the RL process that’s self-supervised (i.e., it learns from unlabeled knowledge collected by the brokers). It may be skilled both on-line (collectively with the RL agent) or offline (from a dataset of interactions). Its position is to information the RL coverage in direction of reversible habits. This method will increase the efficiency of RL brokers on a number of duties, together with the difficult Sokoban puzzle recreation.
Reversibility-Conscious RL
The reversibility element added to the RL process is discovered from interactions, and crucially, is a mannequin that may be skilled separate from the agent itself. The mannequin coaching is self-supervised and doesn’t require that the info be labeled with the reversibility of the actions. As an alternative, the mannequin learns about which kinds of actions are usually reversible from the context offered by the coaching knowledge alone.We name the theoretical clarification for this empirical reversibility, a measure of the likelihood that an occasion A precedes one other occasion B, figuring out that A and B each occur. Priority is a helpful proxy for true reversibility as a result of it may be discovered from a dataset of interactions, even with out rewards.
Think about, for instance, an experiment the place a glass is dropped from desk peak and when it hits the ground it shatters. On this case, the glass goes from place A (desk peak) to place B (flooring) and whatever the variety of trials, A at all times precedes B, so when randomly sampling pairs of occasions, the likelihood of discovering a pair by which A precedes B is 1. This may point out an irreversible sequence. Assume, as an alternative, a rubber ball was dropped as an alternative of the glass. On this case, the ball would begin at A, drop to B, after which (roughly) return to A. So, when sampling pairs of occasions, the likelihood of discovering a pair by which A precedes B would solely be 0.5 (the identical because the likelihood {that a} random pair confirmed B previous A), and would point out a reversible sequence.
 |
| Reversibility estimation depends on the data of the dynamics of the world. A proxy to reversibility is priority, which establishes which of two occasions comes first on common,on condition that each are noticed. |
In observe, we pattern pairs of occasions from a group of interactions, shuffle them, and prepare the neural community to reconstruct the precise chronological order of the occasions. The community’s efficiency is measured and refined by evaluating its predictions towards the bottom fact derived from the timestamps of the particular knowledge. Since occasions which can be temporally distant are usually both trivial or unimaginable to order, we pattern occasions in a temporal window of fastened dimension. We then use the prediction possibilities of this estimator as a proxy for reversibility: if the neural community’s confidence that occasion A occurs earlier than occasion B is increased than a selected threshold, then we deem that the transition from occasion A to B is irreversible.
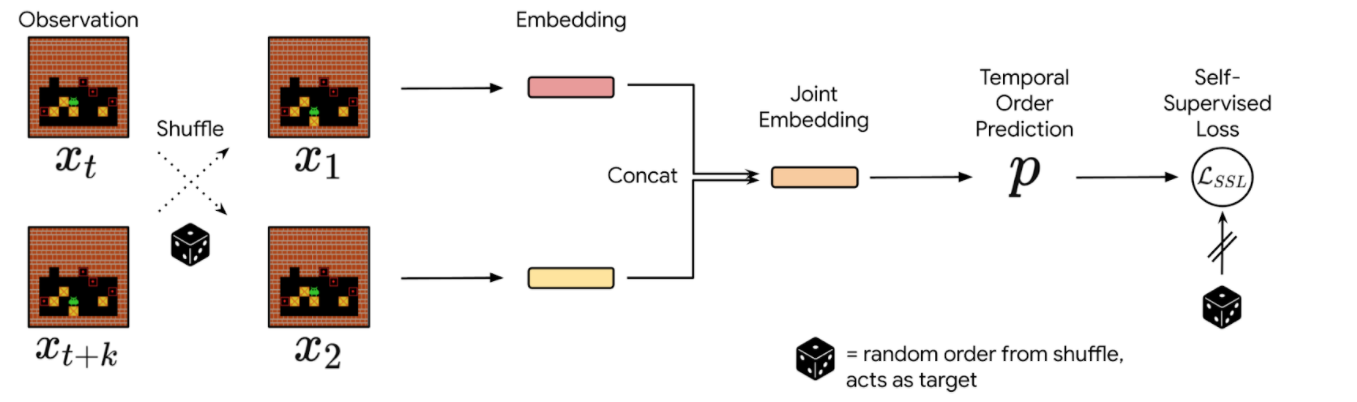 |
| Priority estimation consists of predicting the temporal order of randomly shuffled occasions. |
Integrating Reversibility into RL
We suggest two concurrent methods of integrating reversibility in RL:
- Reversibility-Conscious Exploration (RAE): This method penalizes irreversible transitions, through a modified reward perform. When the agent picks an motion that’s thought of irreversible, it receives a reward similar to the setting’s reward minus a constructive, fastened penalty, which makes such actions much less seemingly, however doesn’t exclude them.
- Reversibility-Conscious Management (RAC): Right here, all irreversible actions are filtered out, a course of that serves as an intermediate layer between the coverage and the setting. When the agent picks an motion that’s thought of irreversible, the motion choice course of is repeated, till a reversible motion is chosen.
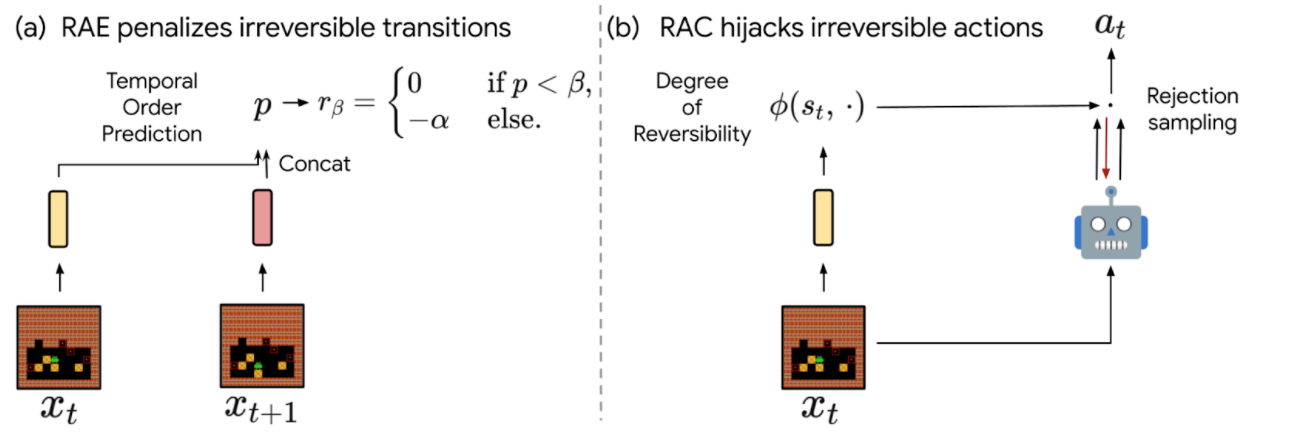 |
| The proposed RAE (left) and RAC (proper) strategies for reversibility-aware RL. |
An necessary distinction between RAE and RAC is that RAE solely encourages reversible actions, it doesn’t prohibit them, which signifies that irreversible actions can nonetheless be carried out when the advantages outweigh prices (as within the Sokoban instance under). Because of this, RAC is healthier suited to protected RL the place irreversible side-effects induce dangers that ought to be prevented totally, and RAE is healthier suited to duties the place it’s suspected that irreversible actions are to be prevented more often than not.
For instance the excellence between RAE and RAC, we consider the capabilities of each proposed strategies. A couple of instance eventualities observe:
- Avoiding (however not prohibiting) irreversible side-effects
A common rule for protected RL is to reduce irreversible interactions when potential, as a precept of warning. To check such capabilities, we introduce an artificial setting the place an agent in an open discipline is tasked with reaching a aim. If the agent follows the established pathway, the setting stays unchanged, but when it departs from the pathway and onto the grass, the trail it takes turns to brown. Whereas this modifications the setting, no penalty is issued for such habits.
On this situation, a typical model-free agent, akin to a Proximal Coverage Optimization (PPO) agent, tends to observe the shortest path on common and spoils among the grass, whereas a PPO+RAE agent avoids all irreversible side-effects.
Prime-left: The artificial setting by which the agent (blue) is tasked with reaching a aim (pink). A pathway is proven in gray main from the agent to the aim, however it doesn’t observe probably the most direct route between the 2. Prime-right: An motion sequence with irreversible side-effects of an agent’s actions. When the agent departs from the trail, it leaves a brown path via the sphere. Backside-left: The visitation heatmap for a PPO agent. Brokers are likely to observe a extra direct path than that proven in gray. Backside-right: The visitation heatmap for a PPO+RAE agent. The irreversibility of going off-path encourages the agent to remain on the established gray path. - Protected interactions by prohibiting irreversibility
We additionally examined towards the traditional Cartpole activity, by which the agent controls a cart as a way to stability a pole standing precariously upright on high of it. We set the utmost variety of interactions to 50k steps, as an alternative of the standard 200. On this activity, irreversible actions are likely to trigger the pole to fall, so it’s higher to keep away from such actions in any respect.
We present that combining RAC with any RL agent (even a random agent) by no means fails, on condition that we choose an acceptable threshold for the likelihood that an motion is irreversible. Thus, RAC can assure protected, reversible interactions from the very first step within the setting.
We present how the Cartpole efficiency of a random coverage outfitted with RAC evolves with completely different threshold values (ꞵ). Normal model-free brokers (DQN, M-DQN) usually rating lower than 3000, in comparison with 50000 (the utmost rating) for an agent ruled by a random+RAC coverage at a threshold worth of β=0.4. - Avoiding deadlocks in Sokoban
Sokoban is a puzzle recreation by which the participant controls a warehouse keeper and has to push containers onto goal areas, whereas avoiding unrecoverable conditions (e.g., when a field is in a nook or, in some circumstances, alongside a wall).
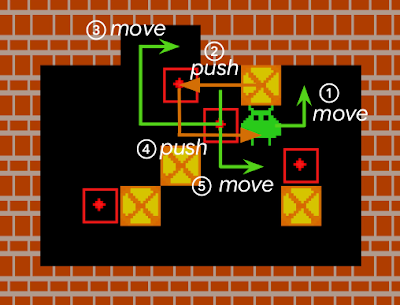
An motion sequence that completes a Sokoban stage. Containers (yellow squares with a crimson “x”) have to be pushed by an agent onto targets (crimson outlines with a dot within the center). As a result of the agent can not pull the containers, any field pushed towards a wall will be tough, if not unimaginable to get away from the wall, i.e., it turns into “deadlocked”. For the standard RL mannequin, early iterations of the agent usually act in a near-random trend to discover the setting, and consequently, get caught fairly often. Such RL brokers both fail to resolve Sokoban puzzles, or are fairly inefficient at it.
Brokers that discover randomly rapidly have interaction themselves in deadlocks that forestall them from finishing ranges (for example right here, pushing the rightmost field on the wall can’t be reversed). We in contrast the efficiency within the Sokoban setting of IMPALA, a state-of-the-art model-free RL agent, to that of an IMPALA+RAE agent. We discover that the agent with the mixed IMPALA+RAE coverage is deadlocked much less continuously, leading to superior scores.
The scores of IMPALA and IMPALA+RAE on a set of 1000 Sokoban ranges. A brand new stage is sampled firstly of every episode.The very best rating is stage dependent and near 10. On this activity, detecting irreversible actions is tough as a result of it’s a extremely imbalanced studying downside — solely ~1% of actions are certainly irreversible, and lots of different actions are tough to flag as reversible, as a result of they will solely be reversed via numerous further steps by the agent.
Reversing an motion is usually non-trivial. Within the instance proven right here, a field has been pushed towards the wall, however remains to be reversible. Nonetheless, reversing the scenario takes not less than 5 separate actions comprising 17 distinct actions by the agent (every numbered transfer being the results of a number of actions from the agent). We estimate that roughly half of all Sokoban ranges require not less than one irreversible motion to be accomplished (e.g., as a result of not less than one goal vacation spot is adjoining to a wall). Since IMPALA+RAE solves just about all ranges, it implies that RAE doesn’t forestall the agent from taking irreversible actions when it’s essential to take action.





{kind=link}
Conclusion
We current a technique that permits RL brokers to foretell the reversibility of an motion by studying to mannequin the temporal order of randomly sampled trajectory occasions, which leads to higher exploration and management. Our proposed technique is self-supervised, which means that it doesn’t necessitate any prior data in regards to the reversibility of actions, making it nicely suited to a wide range of environments. Sooner or later, we’re inquisitive about finding out additional how these concepts may very well be utilized in bigger scale and safety-critical purposes.
Acknowledgements
We wish to thank our paper co-authors Nathan Grinsztajn, Philippe Preux, Olivier Pietquin and Matthieu Geist. We’d additionally wish to thank Bobak Shahriari, Théophane Weber, Damien Vincent, Alexis Jacq, Robert Dadashi, Léonard Hussenot, Nino Vieillard, Lukasz Stafiniak, Nikola Momchev, Sabela Ramos and all those that offered useful dialogue and suggestions on this work.
[ad_2]