

[ad_1]
Fast advances in machine studying in recent times have begun to decrease the technical hurdles to implementing AI, and varied corporations have begun to actively use machine studying. Firms are emphasizing the accuracy of machine studying fashions whereas on the identical time specializing in price discount, each of that are essential. After all, discovering a compromise is critical to a sure diploma, however reasonably than merely compromising, discovering the optimum resolution inside that trade-off is the important thing to creating most enterprise worth.
This text presents a case examine of how DataRobot was capable of obtain excessive accuracy and low price by really utilizing strategies realized by means of Information Science Competitions within the technique of fixing a DataRobot buyer’s drawback.
As a DataRobot knowledge scientist, I’ve labored with group members on quite a lot of initiatives to enhance the enterprise worth of our clients. Along with the accuracy of the fashions we constructed, we needed to take into account enterprise metrics, price, interpretability, and suitability for ongoing operations. Finally, the analysis relies on whether or not or not the mannequin delivers success to the purchasers’ enterprise.
However, within the Information Science Competitions, which I’ve participated in for a few years as a pastime, the info and analysis standards are principally ready from the start, so principally all it’s important to do is give attention to enhancing accuracy. Whereas the appliance of cutting-edge expertise and the power to give you novel concepts are sometimes the deciding components, a easy resolution primarily based on an understanding of the essence of the issue can usually be the profitable resolution.
Whereas there are a lot of variations between Information Science Competitions and enterprise, there are additionally similarities. That commonality is that low-cost, high-accuracy resolution strategies, or approaches of excellence, can have a big affect on outcomes. On this weblog publish, we want to current some examples of precise instances wherein noise discount had a big impact in real-world functions, and wherein highly effective options have been obtained. Discovering such good options shouldn’t be solely helpful to win at Information Science Competitions, but additionally to maximise enterprise worth.
Sensor Information Evaluation Examples

{kind=link}
The accuracy of machine studying fashions is extremely depending on the standard of the coaching knowledge. With out high-quality knowledge, irrespective of how superior the mannequin is, it is not going to produce good outcomes. Actual knowledge is nearly all the time a mix of sign and noise, and if you happen to embrace that noise within the mannequin, it is going to be troublesome to seize the sign.
Particularly in time sequence knowledge evaluation, there are a lot of conditions wherein there are extreme fluctuations and consequent noise. For instance, knowledge measured by sensors can include every kind of noise because of sensor malfunctions, environmental adjustments, and so forth., which might result in massive prediction errors. One other instance is web site entry knowledge, the place the presence of spamming, search engine crawlers, and so forth. could make it troublesome to investigate the actions of peculiar customers. Distinguishing between sign and noise is one essential facet of machine studying mannequin enchancment. To enhance mannequin accuracy, it’s vital to extend the signal-to-noise ratio (SNR), and it’s common apply to attempt to extract extra indicators by spending a number of effort and time on function engineering and modeling, however that is usually not an easy course of. When evaluating the 2 approaches, sign enhancement and noise discount, noise discount is less complicated and simpler in lots of instances.
The next is a case the place I’ve succeeded in considerably enhancing accuracy through the use of a noise discount technique in apply. The shopper’s problem was to detect predictive indicators within the manufacturing technique of a sure materials. If the varied noticed values measured by sensors within the tools might be predicted, it could be potential to manage manufacturing parameters and scale back gasoline prices. The bottleneck right here was the very low high quality of the info, which was very noisy, together with intervals of steady operation and intervals of shutdown. Initially, the shopper tried modeling utilizing statistical strategies to create typical options, similar to shifting averages, however the mannequin metrics (R-square) was solely 0.5 or much less. The bigger the worth, the higher the mannequin represents the info, and the smaller the worth, the much less nicely it represents the info. Subsequently, a worth under 0.5 couldn’t be stated to be extremely correct, and in reality the mannequin was not sensible. Transferring common options can scale back noise to a sure diploma, however the noise was so massive that it was inadequate.
At the moment, I considered an answer from the highest group in a Information Science Competitions known as Net Visitors Time Sequence Forecasting. The competitors was to foretell Wikipedia’s pageview, however it was an evaluation drawback for very noisy time sequence knowledge. The profitable group was ready to make use of RNN seq2seq to be taught to robustly encode and decode even noisy knowledge, which was a terrific resolution. Extra fascinating was the eighth place group’s resolution, which used a kalman filter reasonably than a machine studying mannequin to take away noise, after which added statistical strategies to construct a strong prediction mannequin, which was very simple and highly effective. I keep in mind being impressed on the time that this was a extremely productive expertise that ought to be pursued in apply.
The Kalman filter is a technique for effectively estimating the invisible inside “state” in a mathematical mannequin known as a state-space mannequin. Within the state-space mannequin, for instance, data obtained from sensors is used as “noticed values” from which the “state” is estimated, and management is carried out primarily based on this. Even when there’s noise within the “noticed values,” the “state” will eradicate the noise and turn into the unique appropriate noticed values.
After processing all of the noticed values utilizing the Kalman filter, I created shifting common options and educated a mannequin utilizing DataRobot. The R-square, which was lower than 0.5 utilizing the standard technique, improved to greater than 0.85 directly, a big enchancment that was like magic. Furthermore, the method took just a few dozen seconds for a number of tens of hundreds of rows of information, and a extremely correct forecasting mannequin was realized at a low price.


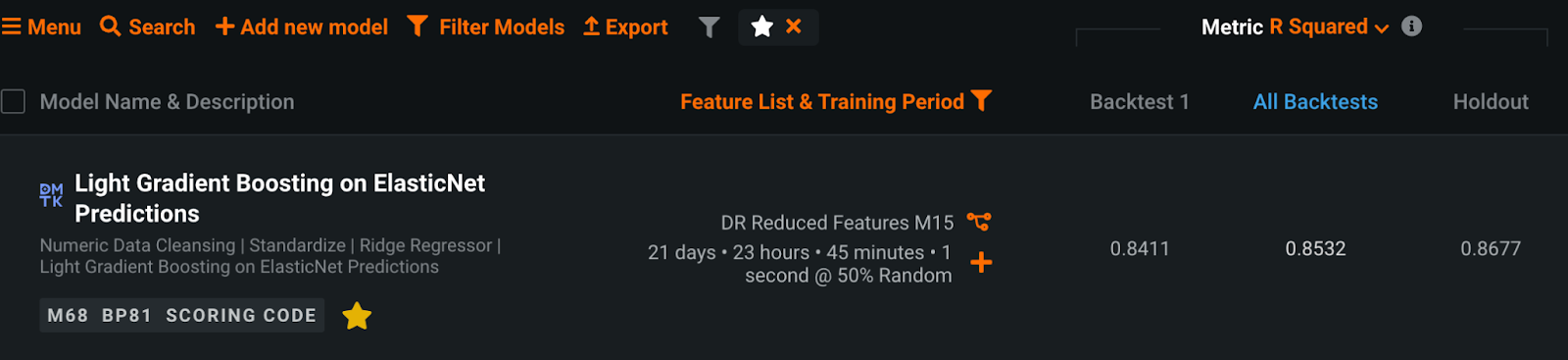
There’s a library known as pykalman that may deal with Kalman filters in Python, which is straightforward to make use of and helpful.
from pykalman import KalmanFilter
def Kalman1D(observations,damping=1):
observation_covariance = damping
initial_value_guess = observations[0]
transition_matrix = 1
transition_covariance = 0.1
initial_value_guess
kf = KalmanFilter(
initial_state_mean=initial_value_guess,
initial_state_covariance=observation_covariance,
observation_covariance=observation_covariance,
transition_covariance=transition_covariance,
transition_matrices=transition_matrix
)
pred_state, state_cov = kf.easy(observations)
return pred_state
observation_covariance = 1 # <- Hyperparameter Tuning
df['sensor_kf'] = Kalman1D(df['sensor'].values, observation_covariance)Examples of Voice Information Evaluation
The accuracy of machine studying fashions is proscribed solely by the standard of the coaching knowledge, however if you happen to can grasp the strategies of function engineering, you’ll be able to maximize their potential. Characteristic creation is essentially the most time-consuming a part of the machine studying mannequin constructing course of, and it’s not unusual to spend an infinite period of time experimenting with completely different function combos. Nevertheless, if we are able to perceive the essence of the info and extract options that may characterize enterprise information, we are able to construct extremely correct fashions even with a small variety of options.
I want to introduce one of many instances the place I’ve improved accuracy with easy options in apply. The shopper’s drawback was a course of to manage engine knocking in cars. Conventionally, the extent of engine knocking was decided by the listening to of a talented individual, however this required particular coaching, was troublesome to find out, and resulted in variation. If this knock leveling might be automated, it could lead to important price financial savings. The primary baseline mannequin we created used spectrograms of speech waveform knowledge, statistical options, and spectrogram photos. This strategy received us to an R-squared of 0.7, however it was troublesome to enhance past that.
I considered the options of the highest group in a Information Science Competitors for LANL Earthquake Prediction. The competitors was to foretell the time-to-failure of an earthquake utilizing solely acoustic knowledge obtained from experimental tools utilized in earthquake analysis. The profitable group and lots of different prime groups used an strategy that diminished overfitting and constructed strong fashions by decreasing the variety of options to a really small quantity, together with the Mel Frequency Cepstrum (MFCC).
MFCC is believed to higher characterize the traits of sounds heard by people by stretching the frequency parts which are essential to human listening to and rising their proportion within the total cepstrum. As well as, by passing by means of an Nth-order Melfilter financial institution, the dimension of the cepstrum might be diminished to N whereas preserving the options which are essential to human listening to, which has the benefit of decreasing the computational load in machine studying.
For the duty of figuring out the extent of engine knocking, this MFCC function was very nicely suited, and by including it to this buyer’s mannequin, we have been capable of considerably enhance the R-square to over 0.8. Once more, excessive accuracy was achieved at a low price, and processing might be accomplished in tens of seconds for a number of hundred audio information.
There’s a library known as librosa that may extract MFCC options in Python, and pattern code is supplied under on your reference.
import librosa
fn = 'audio file path'
y, sr = librosa.core.load(fn)
mfcc = librosa.function.mfcc(y=y, sr=sr, n_mfcc=20)
mfcc_mean = mfcc.imply(axis=1)Customized Mannequin in DataRobot
Now it’s really potential to make use of pykalman, librosa, and so forth. on the DataRobot platform. By combining the varied built-in duties in DataRobot with customized duties designed by customers in Python or R, customers can simply construct their very own machine studying pipelines. As well as, customized container environments for duties help you add dependencies at any time.

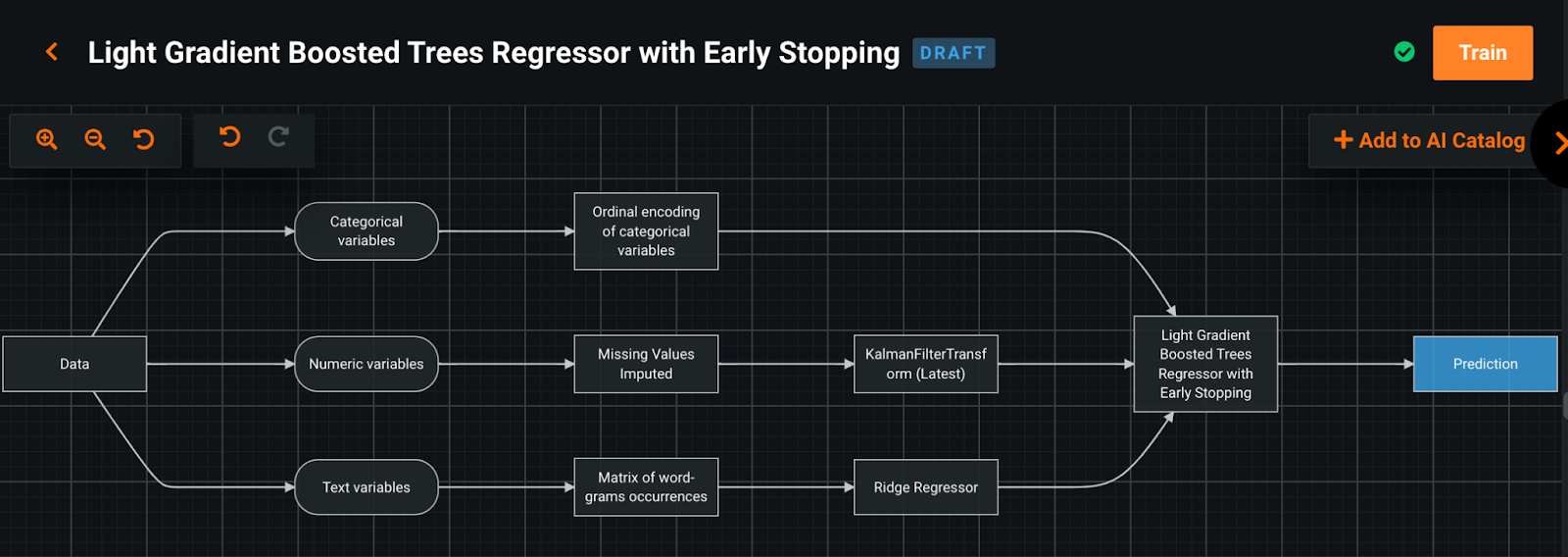
Abstract
As we’ve got defined, the important thing to each enhancing the accuracy and decreasing the price of machine studying fashions shouldn’t be merely to compromise, however to search out the optimum resolution, primarily based on an actual buyer case examine of DataRobot, making use of the concise but highly effective strategies realized from the Information Science Competitions. DataRobot Composable ML means that you can construct customized environments, code duties in Python or R, and work with the DataRobot platform to construct optimum fashions. We additionally hope you’ll benefit from Composable ML, a brand new function that mixes excessive productiveness with full automation and customizability.
Concerning the writer

Senior Execution Information Scientist at DataRobot
Senkin Zhan is a Senior Execution Information Scientist at DataRobot. Senkin develops end-to-end enterprise AI options with DataRobot AI Cloud Platform for purchasers throughout trade verticals. He’s additionally a Kaggle competitors grandmaster who gained many gold medals.
[ad_2]