
{kind=link}
[ad_1]
Regardless of appreciable progress in robotic studying over the previous a number of years, some insurance policies for robotic brokers can nonetheless wrestle to decisively select actions when attempting to mimic exact or complicated behaviors. Take into account a process during which a robotic tries to slip a block throughout a desk to exactly place it right into a slot. There are a lot of doable methods to resolve this process, every requiring exact actions and corrections. The robotic should commit to only certainly one of these choices, however should even be able to altering plans every time the block finally ends up sliding farther than anticipated. Though one would possibly count on such a process to be simple, that’s usually not the case for contemporary learning-based robots, which regularly be taught conduct that skilled observers describe as indecisive or imprecise.
| Instance of a baseline specific conduct cloning mannequin struggling on a process the place the robotic wants to slip a block throughout a desk after which exactly insert it right into a fixture. |
To encourage robots to be extra decisive, researchers usually make the most of a discretized motion house, which forces the robotic to decide on choice A or choice B, with out oscillating between choices. For instance, discretization was a key ingredient of our current Transporter Networks structure, and can be inherent in lots of notable achievements by game-playing brokers, equivalent to AlphaGo, AlphaStar, and OpenAI’s Dota bot. However discretization brings its personal limitations — for robots that function within the spatially steady actual world, there are at the very least two downsides to discretization: (i) it limits precision, and (ii) it triggers the curse of dimensionality, since contemplating discretizations alongside many alternative dimensions can dramatically enhance reminiscence and compute necessities. Associated to this, in 3D laptop imaginative and prescient a lot current progress has been powered by steady, quite than discretized, representations.
With the purpose of studying decisive insurance policies with out the drawbacks of discretization, at present we announce our open supply implementation of Implicit Behavioral Cloning (Implicit BC), which is a brand new, easy strategy to imitation studying and was offered final week at CoRL 2021. We discovered that Implicit BC achieves robust outcomes on each simulated benchmark duties and on real-world robotic duties that demand exact and decisive conduct. This contains attaining state-of-the-art (SOTA) outcomes on human-expert duties from our group’s current benchmark for offline reinforcement studying, D4RL. On six out of seven of those duties, Implicit BC outperforms the most effective earlier methodology for offline RL, Conservative Q Studying. Apparently, Implicit BC achieves these outcomes with out requiring any reward data, i.e., it may use comparatively easy supervised studying quite than more-complex reinforcement studying.
Implicit Behavioral Cloning
Our strategy is a sort of conduct cloning, which is arguably the only approach for robots to be taught new expertise from demonstrations. In conduct cloning, an agent learns find out how to mimic an skilled’s conduct utilizing customary supervised studying. Historically, conduct cloning entails coaching an specific neural community (proven under, left), which takes in observations and outputs skilled actions.
The important thing thought behind Implicit BC is to as an alternative prepare a neural community to absorb each observations and actions, and output a single quantity that’s low for skilled actions and excessive for non-expert actions (under, proper), turning behavioral cloning into an energy-based modeling drawback. After coaching, the Implicit BC coverage generates actions by discovering the motion enter that has the bottom rating for a given statement.
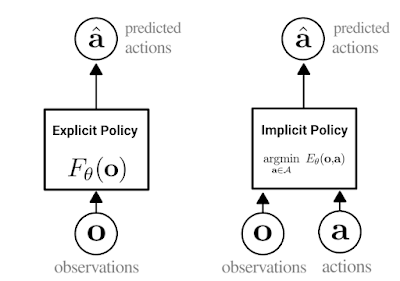 |
| Depiction of the distinction between specific (left) and implicit (proper) insurance policies. Within the implicit coverage, the “argmin” means the motion that, when paired with a specific statement, minimizes the worth of the vitality operate. |
To coach Implicit BC fashions, we use an InfoNCE loss, which trains the community to output low vitality for skilled actions within the dataset, and excessive vitality for all others (see under). It’s attention-grabbing to notice that this concept of utilizing fashions that soak up each observations and actions is widespread in reinforcement studying, however not so in supervised coverage studying.
| Animation of how implicit fashions can match discontinuities — on this case, coaching an implicit mannequin to suit a step (Heaviside) operate. Left: 2D plot becoming the black (X) coaching factors — the colours signify the values of the energies (blue is low, brown is excessive). Center: 3D plot of the vitality mannequin throughout coaching. Proper: Coaching loss curve. |
As soon as educated, we discover that implicit fashions are significantly good at exactly modeling discontinuities (above) on which prior specific fashions wrestle (as within the first determine of this publish), leading to insurance policies which can be newly able to switching decisively between completely different behaviors.
However why do standard specific fashions wrestle? Trendy neural networks nearly all the time use steady activation features — for instance, Tensorflow, Jax, and PyTorch all solely ship with steady activation features. In making an attempt to suit discontinuous information, specific networks constructed with these activation features can’t signify discontinuities, so should draw steady curves between information factors. A key facet of implicit fashions is that they acquire the flexibility to signify sharp discontinuities, though the community itself consists solely of steady layers.
We additionally set up theoretical foundations for this facet, particularly a notion of common approximation. This proves the category of features that implicit neural networks can signify, which can assist justify and information future analysis.
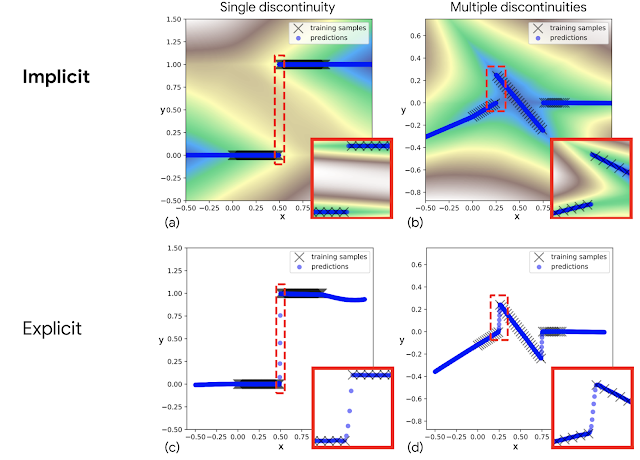 |
| Examples of becoming discontinuous features, for implicit fashions (prime) in comparison with specific fashions (backside). The purple highlighted insets present that implicit fashions signify discontinuities (a) and (b) whereas the express fashions should draw steady strains (c) and (d) in between the discontinuities. |
One problem confronted by our preliminary makes an attempt at this strategy was “excessive motion dimensionality”, which signifies that a robotic should determine find out how to coordinate many motors all on the identical time. To scale to excessive motion dimensionality, we use both autoregressive fashions or Langevin dynamics.
Highlights
In our experiments, we discovered Implicit BC does significantly effectively in the true world, together with an order of magnitude (10x) higher on the 1mm-precision slide-then-insert process in comparison with a baseline specific BC mannequin. On this process the implicit mannequin does a number of consecutive exact changes (under) earlier than sliding the block into place. This process calls for a number of components of decisiveness: there are various completely different doable options as a result of symmetry of the block and the arbitrary ordering of push maneuvers, and the robotic must discontinuously determine when the block has been pushed far “sufficient” earlier than switching to slip it in a special route. That is in distinction to the indecisiveness that’s usually related to continuous-controlled robots.
| Instance process of sliding a block throughout a desk and exactly inserting it right into a slot. These are autonomous behaviors of our Implicit BC insurance policies, utilizing solely photographs (from the proven digital camera) as enter. |
| A various set of various methods for carrying out this process. These are autonomous behaviors from our Implicit BC insurance policies, utilizing solely photographs as enter. |
In one other difficult process, the robotic must kind blocks by colour, which presents a lot of doable options as a result of arbitrary ordering of sorting. On this process the express fashions are typically indecisive, whereas implicit fashions carry out significantly higher.
| Comparability of implicit (left) and specific (proper) BC fashions on a difficult steady multi-item sorting process. (4x velocity) |
In our testing, implicit BC fashions also can exhibit sturdy reactive conduct, even after we attempt to intrude with the robotic, regardless of the mannequin by no means seeing human arms.
| Sturdy conduct of the implicit BC mannequin regardless of interfering with the robotic. |
General, we discover that Implicit BC insurance policies can obtain robust outcomes in comparison with state-of-the-art offline reinforcement studying strategies throughout a number of completely different process domains. These outcomes embrace duties that, challengingly, have both a low variety of demonstrations (as few as 19), excessive statement dimensionality with image-based observations, and/or excessive motion dimensionality as much as 30 — which is a lot of actuators to have on a robotic.
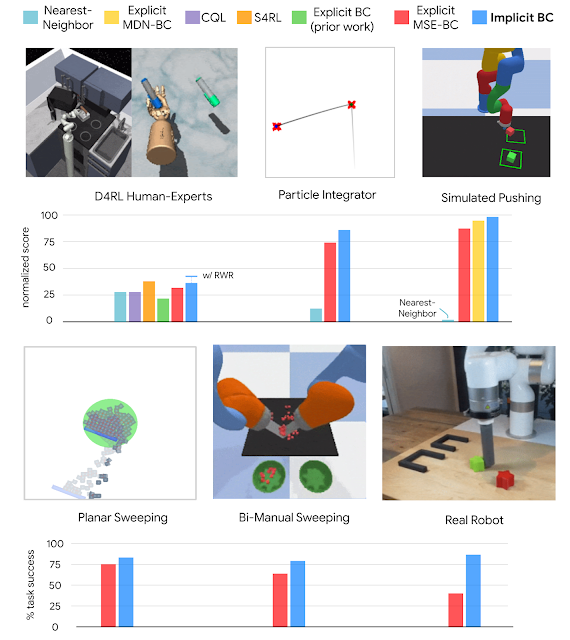 |
| Coverage studying outcomes of Implicit BC in comparison with baselines throughout a number of domains. |
Conclusion
Regardless of its limitations, behavioral cloning with supervised studying stays one of many easiest methods for robots to be taught from examples of human behaviors. As we confirmed right here, changing specific insurance policies with implicit insurance policies when doing behavioral cloning permits robots to beat the “wrestle of decisiveness”, enabling them to mimic rather more complicated and exact behaviors. Whereas the main focus of our outcomes right here was on robotic studying, the flexibility of implicit features to mannequin sharp discontinuities and multimodal labels might have broader curiosity in different utility domains of machine studying as effectively.
Acknowledgements
Pete and Corey summarized analysis carried out along with different co-authors: Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. The authors would additionally wish to thank Vikas Sindwhani for mission route recommendation; Steve Xu, Robert Baruch, Arnab Bose for robotic software program infrastructure; Jake Varley, Alexa Greenberg for ML infrastructure; and Kamyar Ghasemipour, Jon Barron, Eric Jang, Stephen Tu, Sumeet Singh, Jean-Jacques Slotine, Anirudha Majumdar, Vincent Vanhoucke for useful suggestions and discussions.
[ad_2]