
[ad_1]
Deep studying fashions have made spectacular progress in imaginative and prescient, language, and different modalities, significantly with the rise of large-scale pre-training. Such fashions are most correct when utilized to check knowledge drawn from the identical distribution as their coaching set. Nonetheless, in apply, the info confronting fashions in real-world settings hardly ever match the coaching distribution. As well as, the fashions is probably not well-suited for functions the place predictive efficiency is barely a part of the equation. For fashions to be dependable in deployment, they have to be capable of accommodate shifts in knowledge distribution and make helpful choices in a broad array of eventualities.
In “Plex: In direction of Reliability Utilizing Pre-trained Massive Mannequin Extensions”, we current a framework for dependable deep studying as a brand new perspective a few mannequin’s talents; this consists of quite a lot of concrete duties and datasets for stress-testing mannequin reliability. We additionally introduce Plex, a set of pre-trained massive mannequin extensions that may be utilized to many various architectures. We illustrate the efficacy of Plex within the imaginative and prescient and language domains by making use of these extensions to the present state-of-the-art Imaginative and prescient Transformer and T5 fashions, which ends up in important enchancment of their reliability. We’re additionally open-sourcing the code to encourage additional analysis into this method.
 |
| Uncertainty — Canine vs. Cat classifier: Plex can say “I don’t know” for inputs which can be neither cat nor canine. Sturdy Generalization — A naïve mannequin is delicate to spurious correlations (“vacation spot”), whereas Plex is strong. Adaptation — Plex can actively select the info from which it learns to enhance efficiency extra shortly. |
Framework for Reliability
First, we discover perceive the reliability of a mannequin in novel eventualities. We posit three basic classes of necessities for dependable machine studying (ML) programs: (1) they need to precisely report uncertainty about their predictions (“know what they don’t know”); (2) they need to generalize robustly to new eventualities (distribution shift); and (3) they need to be capable of effectively adapt to new knowledge (adaptation). Importantly, a dependable mannequin ought to goal to do nicely in all of those areas concurrently out-of-the-box, with out requiring any customization for particular person duties.
- Uncertainty displays the imperfect or unknown data that makes it tough for a mannequin to make correct predictions. Predictive uncertainty quantification permits a mannequin to compute optimum choices and helps practitioners acknowledge when to belief the mannequin’s predictions, thereby enabling sleek failures when the mannequin is prone to be flawed.
- Sturdy Generalization includes an estimate or forecast about an unseen occasion. We examine 4 forms of out-of-distribution knowledge: covariate shift (when the enter distribution modifications between coaching and software and the output distribution is unchanged), semantic (or class) shift, label uncertainty, and subpopulation shift.
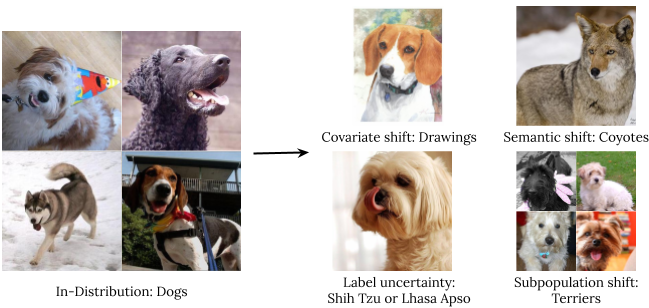
Varieties of distribution shift utilizing an illustration of ImageNet canines. - Adaptation refers to probing the mannequin’s talents over the course of its studying course of. Benchmarks usually consider on static datasets with pre-defined train-test splits. Nonetheless, in lots of functions, we’re keen on fashions that may shortly adapt to new datasets and effectively study with as few labeled examples as potential.

{kind=link}
 |
| Reliability framework. We suggest to concurrently stress-test the “out-of-the-box” mannequin efficiency (i.e., the predictive distribution) throughout uncertainty, sturdy generalization, and adaptation benchmarks, with none customization for particular person duties. |
We apply 10 forms of duties to seize the three reliability areas — uncertainty, sturdy generalization, and adaptation — and to make sure that the duties measure a various set of fascinating properties in every space. Collectively the duties comprise 40 downstream datasets throughout imaginative and prescient and pure language modalities: 14 datasets for fine-tuning (together with few-shot and energetic studying–primarily based adaptation) and 26 datasets for out-of-distribution analysis.
Plex: Pre-trained Massive Mannequin Extensions for Imaginative and prescient and Language
To enhance reliability, we develop ViT-Plex and T5-Plex, constructing on massive pre-trained fashions for imaginative and prescient (ViT) and language (T5), respectively. A key characteristic of Plex is extra environment friendly ensembling primarily based on submodels that every make a prediction that’s then aggregated. As well as, Plex swaps every structure’s linear final layer with a Gaussian course of or heteroscedastic layer to higher characterize predictive uncertainty. These concepts had been discovered to work very nicely for fashions educated from scratch on the ImageNet scale. We prepare the fashions with various sizes as much as 325 million parameters for imaginative and prescient (ViT-Plex L) and 1 billion parameters for language (T5-Plex L) and pre-training dataset sizes as much as 4 billion examples.
The next determine illustrates Plex’s efficiency on a choose set of duties in comparison with the prevailing state-of-the-art. The highest-performing mannequin for every process is normally a specialised mannequin that’s extremely optimized for that downside. Plex achieves new state-of-the-art on most of the 40 datasets. Importantly, Plex achieves sturdy efficiency throughout all duties utilizing the out-of-the-box mannequin output with out requiring any customized designing or tuning for every process.
 |
| The most important T5-Plex (prime) and ViT-Plex (backside) fashions evaluated on a highlighted set of reliability duties in comparison with specialised state-of-the-art fashions. The spokes show completely different duties, quantifying metric efficiency on numerous datasets. |
Plex in Motion for Totally different Reliability Duties
We spotlight Plex’s reliability on choose duties under.
Open Set Recognition
We present Plex’s output within the case the place the mannequin should defer prediction as a result of the enter is one which the mannequin doesn’t help. This process is called open set recognition. Right here, predictive efficiency is a component of a bigger decision-making state of affairs the place the mannequin might abstain from ensuring predictions. Within the following determine, we present structured open set recognition: Plex returns a number of outputs and indicators the precise a part of the output about which the mannequin is unsure and is probably going out-of-distribution.
 |
| Structured open set recognition permits the mannequin to offer nuanced clarifications. Right here, T5-Plex L can acknowledge fine-grained out-of-distribution circumstances the place the request’s vertical (i.e., coarse-level area of service, corresponding to banking, media, productiveness, and so on.) and area are supported however the intent will not be. |
Label Uncertainty
In real-world datasets, there’s usually inherent ambiguity behind the bottom fact label for every enter. For instance, this may increasingly come up because of human rater ambiguity for a given picture. On this case, we’d just like the mannequin to seize the total distribution of human perceptual uncertainty. We showcase Plex under on examples from an ImageNet variant we constructed that gives a floor fact label distribution.
 |
| Plex for label uncertainty. Utilizing a dataset we assemble known as ImageNet ReaL-H, ViT-Plex L demonstrates the power to seize the inherent ambiguity (likelihood distribution) of picture labels. |
Energetic Studying
We look at a big mannequin’s capability to not solely study over a set set of knowledge factors, but in addition take part in understanding which knowledge factors to study from within the first place. One such process is called energetic studying, the place at every coaching step, the mannequin selects promising inputs amongst a pool of unlabeled knowledge factors on which to coach. This process assesses an ML mannequin’s label effectivity, the place label annotations could also be scarce, and so we wish to maximize efficiency whereas minimizing the variety of labeled knowledge factors used. Plex achieves a major efficiency enchancment over the identical mannequin structure with out pre-training. As well as, even with fewer coaching examples, it additionally outperforms the state-of-the-art pre-trained technique, BASE, which reaches 63% accuracy at 100K examples.
 |
| Energetic studying on ImageNet1K. ViT-Plex L is extremely label environment friendly in comparison with a baseline that doesn’t leverage pre-training. We additionally discover that energetic studying’s knowledge acquisition technique is simpler than uniformly deciding on knowledge factors at random. |
Study extra
Try our paper right here and an upcoming contributed speak in regards to the work on the ICML 2022 pre-training workshop on July 23, 2022. To encourage additional analysis on this route, we’re open-sourcing all code for coaching and analysis as a part of Uncertainty Baselines. We additionally present a demo that reveals use a ViT-Plex mannequin checkpoint. Layer and technique implementations use Edward2.
Acknowledgements
We thank all of the co-authors for contributing to the undertaking and paper, together with Andreas Kirsch, Clara Huiyi Hu, Du Phan, D. Sculley, Honglin Yuan, Jasper Snoek, Jeremiah Liu, Jie Ren, Joost van Amersfoort, Karan Singhal, Kehang Han, Kelly Buchanan, Kevin Murphy, Mark Collier, Mike Dusenberry, Neil Band, Nithum Thain, Rodolphe Jenatton, Tim G. J. Rudner, Yarin Gal, Zachary Nado, Zelda Mariet, Zi Wang, and Zoubin Ghahramani. We additionally thank Anusha Ramesh, Ben Adlam, Dilip Krishnan, Ed Chi, Neil Houlsby, Rif A. Saurous, and Sharat Chikkerur for his or her useful suggestions, and Tom Small and Ajay Nainani for serving to with visualizations.
[ad_2]