
{kind=link}
[ad_1]
This fall Pixel 6 telephones launched with Google Tensor, Google’s first cellular system-on-chip (SoC), bringing collectively varied processing parts (similar to central/graphic/tensor processing items, picture processors, and many others.) onto a single chip, custom-built to ship state-of-the-art improvements in machine studying (ML) to Pixel customers. In reality, each facet of Google Tensor was designed and optimized to run Google’s ML fashions, in alignment with our AI Rules. That begins with the custom-made TPU built-in in Google Tensor that enables us to satisfy our imaginative and prescient of what needs to be potential on a Pixel cellphone.
At the moment, we share the enhancements in on-device machine studying made potential by designing the ML fashions for Google Tensor’s TPU. We use neural structure search (NAS) to automate the method of designing ML fashions, which incentivize the search algorithms to find fashions that obtain greater high quality whereas assembly latency and energy necessities. This automation additionally permits us to scale the event of fashions for varied on-device duties. We’re making these fashions publicly obtainable by the TensorFlow mannequin backyard and TensorFlow Hub in order that researchers and builders can bootstrap additional use case improvement on Pixel 6. Furthermore, we’ve got utilized the identical strategies to construct a extremely energy-efficient face detection mannequin that’s foundational to many Pixel 6 digicam options.
 |
| An illustration of NAS to search out TPU-optimized fashions. Every column represents a stage within the neural community, with dots indicating completely different choices, and every colour representing a special kind of constructing block. A path from inputs (e.g., a picture) to outputs (e.g., per-pixel label predictions) by the matrix represents a candidate neural community. In every iteration of the search, a neural community is fashioned utilizing the blocks chosen at each stage, and the search algorithm goals to search out neural networks that collectively decrease TPU latency and/or power and maximize accuracy. |
Search House Design for Imaginative and prescient Fashions
A key element of NAS is the design of the search area from which the candidate networks are sampled. We customise the search area to incorporate neural community constructing blocks that run effectively on the Google Tensor TPU.
One widely-used constructing block in neural networks for varied on-device imaginative and prescient duties is the Inverted Bottleneck (IBN). The IBN block has a number of variants, every with completely different tradeoffs, and is constructed utilizing common convolution and depthwise convolution layers. Whereas IBNs with depthwise convolution have been conventionally utilized in cellular imaginative and prescient fashions on account of their low computational complexity, fused-IBNs, whereby depthwise convolution is changed by an everyday convolution, have been proven to enhance the accuracy and latency of picture classification and object detection fashions on TPU.
Nevertheless, fused-IBNs can have prohibitively excessive computational and reminiscence necessities for neural community layer shapes which might be typical within the later levels of imaginative and prescient fashions, limiting their use all through the mannequin and leaving the depthwise-IBN as the one different. To beat this limitation, we introduce IBNs that use group convolutions to boost the flexibleness in mannequin design. Whereas common convolution mixes data throughout all of the options within the enter, group convolution slices the options into smaller teams and performs common convolution on options inside that group, lowering the general computational value. Referred to as group convolution–primarily based IBNs (GC-IBNs), their tradeoff is that they could adversely affect mannequin high quality.
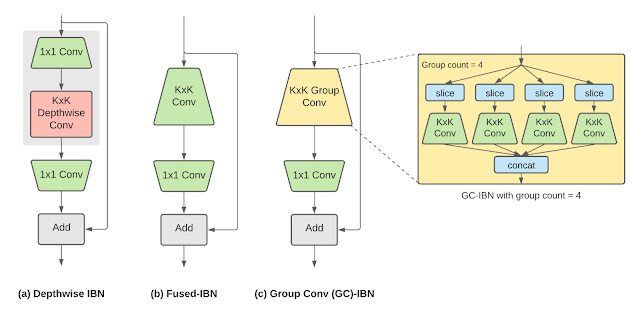 |
| Inverted bottleneck (IBN) variants: (a) depthwise-IBN, depthwise convolution layer with filter dimension OkxOk sandwiched between two convolution layers with filter dimension 1×1; (b) fused-IBN, convolution and depthwise are fused right into a convolution layer with filter dimension OkxOk; and (c) group convolution–primarily based GC-IBN that replaces with the OkxOk common convolution in fused-IBN with group convolution. The variety of teams (group depend) is a tunable parameter throughout NAS. |
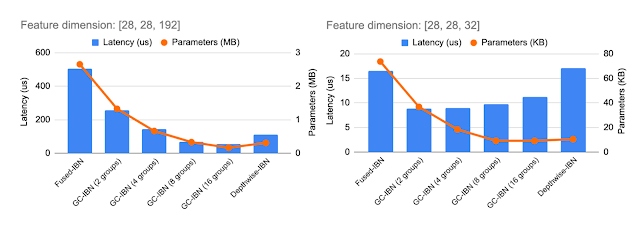 |
| Inclusion of GC-IBN as an choice gives extra flexibility past different IBNs. Computational value and latency of various IBN variants depends upon the function dimensions being processed (proven above for 2 instance function dimensions). We use NAS to find out the optimum alternative of IBN variants. |
Sooner, Extra Correct Picture Classification
Which IBN variant to make use of at which stage of a deep neural community depends upon the latency on the goal {hardware} and the efficiency of the ensuing neural community on the given job. We assemble a search area that features all of those completely different IBN variants and use NAS to find neural networks for the picture classification job that optimize the classification accuracy at a desired latency on TPU. The ensuing MobileNetEdgeTPUV2 mannequin household improves the accuracy at a given latency (or latency at a desired accuracy) in comparison with the prevailing on-device fashions when run on the TPU. MobileNetEdgeTPUV2 additionally outperforms their predecessor, MobileNetEdgeTPU, the picture classification fashions designed for the earlier technology of the TPU.
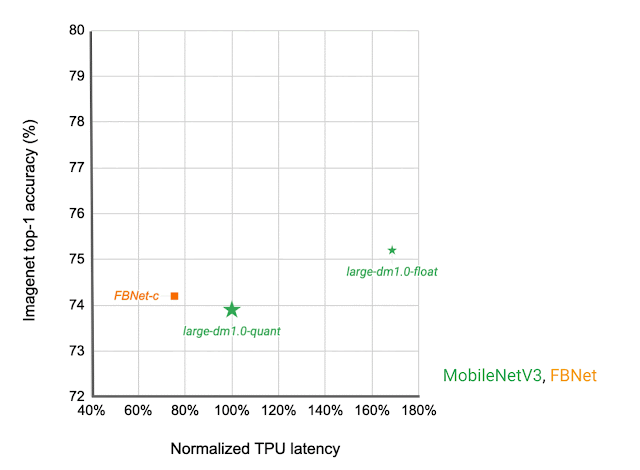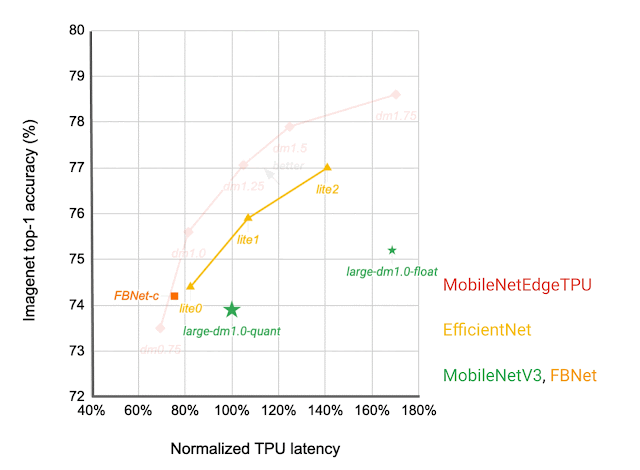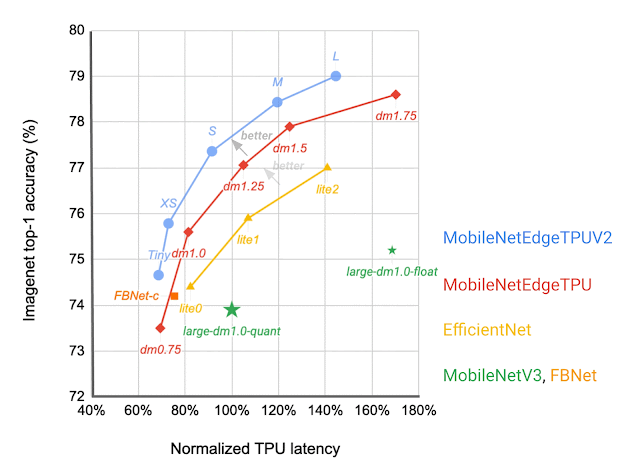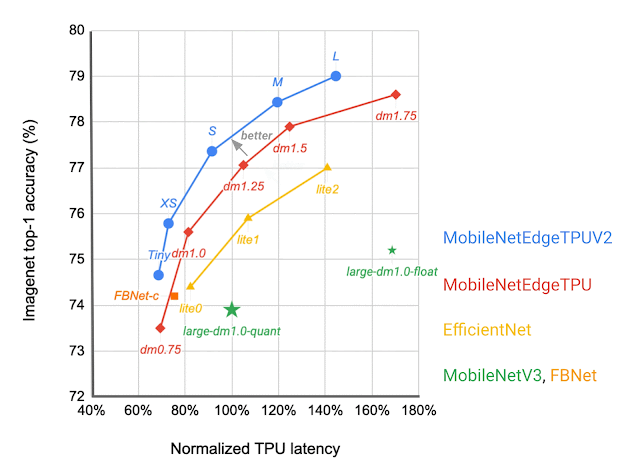 |
| Community structure households visualized as linked dots at completely different latency targets. In contrast with different cellular fashions, similar to FBNet, MobileNetV3, and EfficientNets, MobileNetEdgeTPUV2 fashions obtain greater ImageNet top-1 accuracy at decrease latency when operating on Google Tensor’s TPU. |
MobileNetEdgeTPUV2 fashions are constructed utilizing blocks that additionally enhance the latency/accuracy tradeoff on different compute parts within the Google Tensor SoC, such because the CPU. In contrast to accelerators such because the TPU, CPUs present a stronger correlation between the variety of multiply-and-accumulate operations within the neural community and latency. GC-IBNs are likely to have fewer multiply-and-accumulate operations than fused-IBNs, which leads MobileNetEdgeTPUV2 to outperform different fashions even on Pixel 6 CPU.
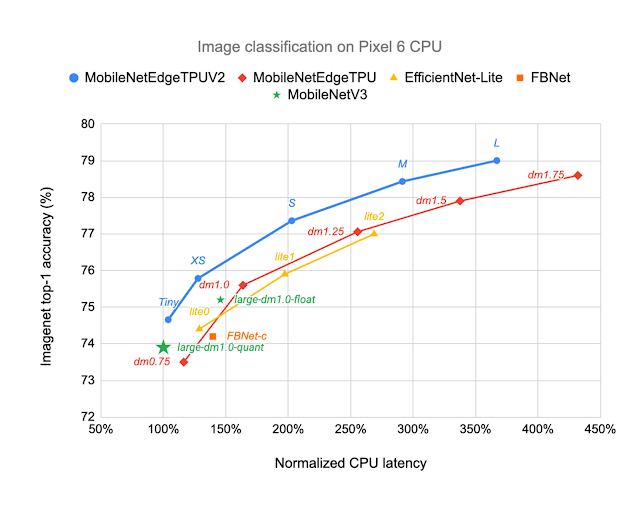 |
| MobileNetEdgeTPUV2 fashions obtain ImageNet top-1 accuracy at decrease latency on Pixel 6 CPU, and outperform different CPU-optimized mannequin architectures, similar to MobileNetV3. |
Enhancing On-Machine Semantic Segmentation
Many imaginative and prescient fashions encompass two parts, the base function extractor for understanding basic options of the picture, and the head for understanding domain-specific options, similar to semantic segmentation (the duty of assigning labels, similar to sky, automobile, and many others., to every pixel in a picture) and object detection (the duty of detecting situations of objects, similar to cats, doorways, automobiles, and many others., in a picture). Picture classification fashions are sometimes used as function extractors for these imaginative and prescient duties. As proven under, the MobileNetEdgeTPUV2 classification mannequin coupled with the DeepLabv3+ segmentation head improves the standard of on-device segmentation.
To additional enhance the segmentation mannequin high quality, we use the bidirectional function pyramid community (BiFPN) because the segmentation head, which performs weighted fusion of various options extracted by the function extractor. Utilizing NAS we discover the optimum configuration of blocks in each the function extractor and the BiFPN head. The ensuing fashions, named Autoseg-EdgeTPU, produce even higher-quality segmentation outcomes, whereas additionally operating quicker.
The ultimate layers of the segmentation mannequin contribute considerably to the general latency, primarily as a result of operations concerned in producing a excessive decision segmentation map. To optimize the latency on TPU, we introduce an approximate technique for producing the excessive decision segmentation map that reduces the reminiscence requirement and gives a virtually 1.5x speedup, with out considerably impacting the segmentation high quality.
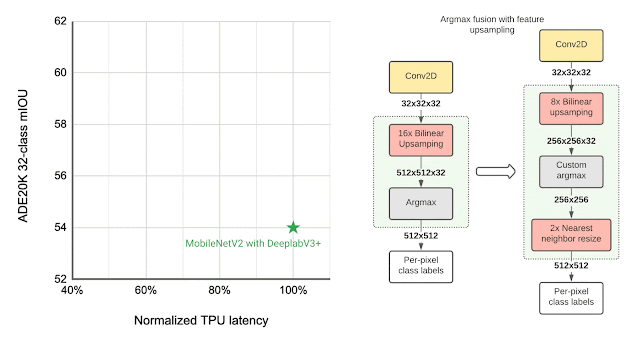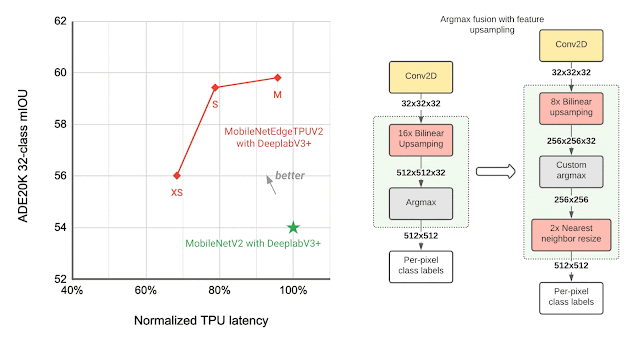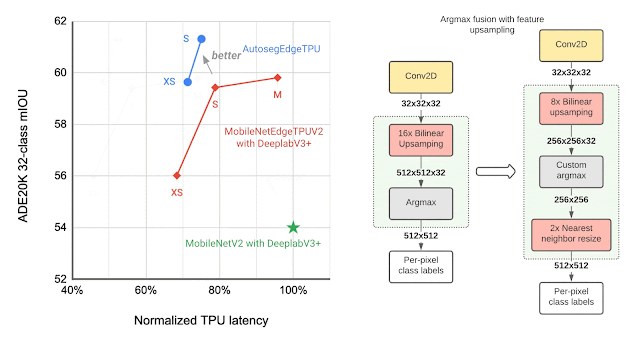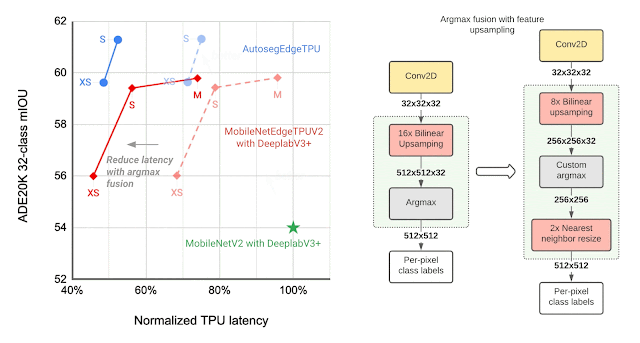 |
| Left: Evaluating the efficiency, measured as imply intersection-over-union (mIOU), of various segmentation fashions on the ADE20K semantic segmentation dataset (high 31 courses). Proper: Approximate function upsampling (e.g., rising decision from 32×32 → 512×512). Argmax operation used to compute per-pixel labels is fused with the bilinear upsampling. Argmax carried out on smaller decision options reduces reminiscence necessities and improves latency on TPU with out a important affect to high quality. |
Increased-High quality, Low-Power Object Detection
Traditional object detection architectures allocate ~70% of the compute funds to the function extractor and solely ~30% to the detection head. For this job we incorporate the GC-IBN blocks right into a search area we name “Spaghetti Search House”1, which gives the flexibleness to maneuver extra of the compute funds to the top. This search area additionally makes use of the non-trivial connection patterns seen in current NAS works similar to MnasFPN to merge completely different however associated levels of the community to strengthen understanding.
We examine the fashions produced by NAS to MobileDet-EdgeTPU, a category of cellular detection fashions personalized for the earlier technology of TPU. MobileDets have been demonstrated to attain state-of-the-art detection high quality on quite a lot of cellular accelerators: DSPs, GPUs, and the earlier TPU. In contrast with MobileDets, the brand new household of SpaghettiNet-EdgeTPU detection fashions achieves +2.2% mAP (absolute) on COCO on the identical latency and consumes lower than 70% of the power utilized by MobileDet-EdgeTPU to attain related accuracy.
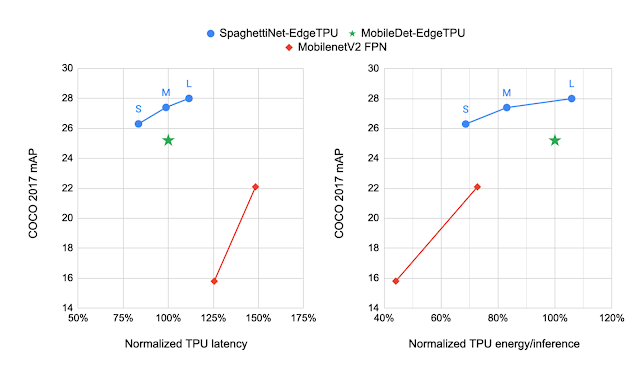 |
| Evaluating the efficiency of various object detection fashions on the COCO dataset with the mAP metric (greater is healthier). SpaghettiNet-EdgeTPU achieves greater detection high quality at decrease latency and power consumption in comparison with earlier cellular fashions, similar to MobileDets and MobileNetV2 with Characteristic Pyramid Community (FPN). |
Inclusive, Power-Environment friendly Face Detection
Face detection is a foundational know-how in cameras that permits a collection of extra options, similar to fixing the main focus, publicity and white stability, and even eradicating blur from the face with the brand new Face Unblur function. Such options should be designed responsibly, and Face Detection within the Pixel 6 had been developed with our AI Rules high of thoughts.
 |
| Left: The unique picture with out enhancements. Proper: An unblurred face in a dynamic surroundings. That is the results of Face Unblur mixed with a extra correct face detector operating at a better frames per second. |
Since cellular cameras may be power-intensive, it was vital for the face detection mannequin to suit inside an influence funds. To optimize for power effectivity, we used the Spaghetti Search House with an algorithm to seek for architectures that maximize accuracy at a given power goal. In contrast with a closely optimized baseline mannequin, SpaghettiNet achieves the identical accuracy at ~70% of the power. The ensuing face detection mannequin, referred to as FaceSSD, is extra power-efficient and correct. This improved mannequin, mixed with our auto-white stability and auto-exposure tuning enhancements, are a part of Actual Tone on Pixel 6. These enhancements assist higher replicate the fantastic thing about all pores and skin tones. Builders can make the most of this mannequin in their very own apps by the Android Camera2 API.
Towards Datacenter-High quality Language Fashions on a Cell Machine
Deploying low-latency, high-quality language fashions on cellular gadgets advantages ML duties like language understanding, speech recognition, and machine translation. MobileBERT, a by-product of BERT, is a pure language processing (NLP) mannequin tuned for cellular CPUs.
Nevertheless, as a result of varied architectural optimizations made to run these fashions effectively on cellular CPUs, their high quality is just not as excessive as that of the big BERT fashions. Since MobileBERT on TPU runs considerably quicker than on CPU, it presents a possibility to enhance the mannequin structure additional and cut back the standard hole between MobileBERT and BERT. We prolonged the MobileBERT structure and leveraged NAS to find fashions that map effectively to the TPU. These new variants of MobileBERT, named MobileBERT-EdgeTPU, obtain as much as 2x greater {hardware} utilization, permitting us to deploy giant and extra correct fashions on TPU at latencies corresponding to the baseline MobileBERT.
MobileBERT-EdgeTPU fashions, when deployed on Google Tensor’s TPU, produce on-device high quality corresponding to the big BERT fashions sometimes deployed in information facilities.
 |
| Efficiency on the query answering job (SQuAD v 1.1). Whereas the TPU in Pixel 6 gives a ~10x acceleration over CPU, additional mannequin customization for the TPU achieves on-device high quality corresponding to the big BERT fashions sometimes deployed in information facilities. |
Conclusion
On this publish, we demonstrated how designing ML fashions for the goal {hardware} expands the on-device ML capabilities of Pixel 6 and brings high-quality, ML-powered experiences to Pixel customers. With NAS, we scaled the design of ML fashions to quite a lot of on-device duties and constructed fashions that present state-of-the-art high quality on-device throughout the latency and energy constraints of a cellular machine. Researchers and ML builders can check out these fashions in their very own use instances by accessing them by the TensorFlow mannequin backyard and TF Hub.
Acknowledgements
This work is made potential by a collaboration spanning a number of groups throughout Google. We’d wish to acknowledge contributions from Rachit Agrawal, Berkin Akin, Andrey Ayupov, Aseem Bathla, Gabriel Bender, Po-Hsein Chu, Yicheng Fan, Max Gubin, Jaeyoun Kim, Quoc Le, Dongdong Li, Jing Li, Yun Lengthy, Hanxiao Lu, Ravi Narayanaswami, Benjamin Panning, Anton Spiridonov, Anakin Tung, Zhuo Wang, Dong Hyuk Woo, Hao Xu, Jiayu Ye, Hongkun Yu, Ping Zhou, and Yanqi Zhuo. Lastly, we’d wish to thank Tom Small for creating illustrations for this weblog publish.
1The ensuing architectures are likely to appear like spaghetti due to the connection patterns fashioned between blocks. ↩
[ad_2]