
{kind=link}
[ad_1]
Multimodal video captioning methods make the most of each the video frames and speech to generate pure language descriptions (captions) of movies. Such methods are stepping stones in direction of the longstanding objective of constructing multimodal conversational methods that effortlessly talk with customers whereas perceiving environments by multimodal enter streams.
In contrast to video understanding duties (e.g., video classification and retrieval) the place the important thing problem lies in processing and understanding multimodal enter movies, the duty of multimodal video captioning consists of the extra problem of producing grounded captions. Probably the most broadly adopted strategy for this process is to coach an encoder-decoder community collectively utilizing manually annotated information. Nevertheless, because of a scarcity of large-scale, manually annotated information, the duty of annotating grounded captions for movies is labor intensive and, in lots of circumstances, impractical. Earlier analysis reminiscent of VideoBERT and CoMVT pre-train their fashions on unlabelled movies by leveraging automated speech recognition (ASR). Nevertheless, such fashions typically can not generate pure language sentences as a result of they lack a decoder, and thus solely the video encoder is transferred to the downstream duties.
In “Finish-to-Finish Generative Pre-training for Multimodal Video Captioning”, printed at CVPR 2022, we introduce a novel pre-training framework for multimodal video captioning. This framework, which we name multimodal video generative pre-training or MV-GPT, collectively trains a multimodal video encoder and a sentence decoder from unlabelled movies by leveraging a future utterance because the goal textual content and formulating a novel bi-directional era process. We display that MV-GPT successfully transfers to multimodal video captioning, reaching state-of-the-art outcomes on varied benchmarks. Moreover, the multimodal video encoder is aggressive for a number of video understanding duties, reminiscent of VideoQA, text-video retrieval, and motion recognition.
Future Utterance as an Extra Textual content Sign
Sometimes, every coaching video clip for multimodal video captioning is related to two completely different texts: (1) a speech transcript that’s aligned with the clip as part of the multimodal enter stream, and (2) a goal caption, which is usually manually annotated. The encoder learns to fuse data from the transcript with visible contents, and the goal caption is used to coach the decoder for era. Nevertheless, within the case of unlabelled movies, every video clip comes solely with a transcript from ASR, with no manually annotated goal caption. Furthermore, we can not use the identical textual content (the ASR transcript) for the encoder enter and decoder goal, for the reason that era of the goal would then be trivial.
MV-GPT circumvents this problem by leveraging a future utterance as a further textual content sign and enabling joint pre-training of the encoder and decoder. Nevertheless, coaching a mannequin to generate future utterances which can be typically not grounded within the enter content material shouldn’t be very best. So we apply a novel bi-directional era loss to strengthen the connection to the enter.
Bi-directional Technology Loss
The difficulty of non-grounded textual content era is mitigated by formulating a bi-directional era loss that features ahead and backward era. Ahead era produces future utterances given visible frames and their corresponding transcripts and permits the mannequin to be taught to fuse the visible content material with its corresponding transcript. Backward era takes the visible frames and future utterances to coach the mannequin to generate a transcript that comprises extra grounded textual content of the video clip. Bi-directional era loss in MV-GPT permits the encoder and the decoder to be skilled to deal with visually grounded texts.
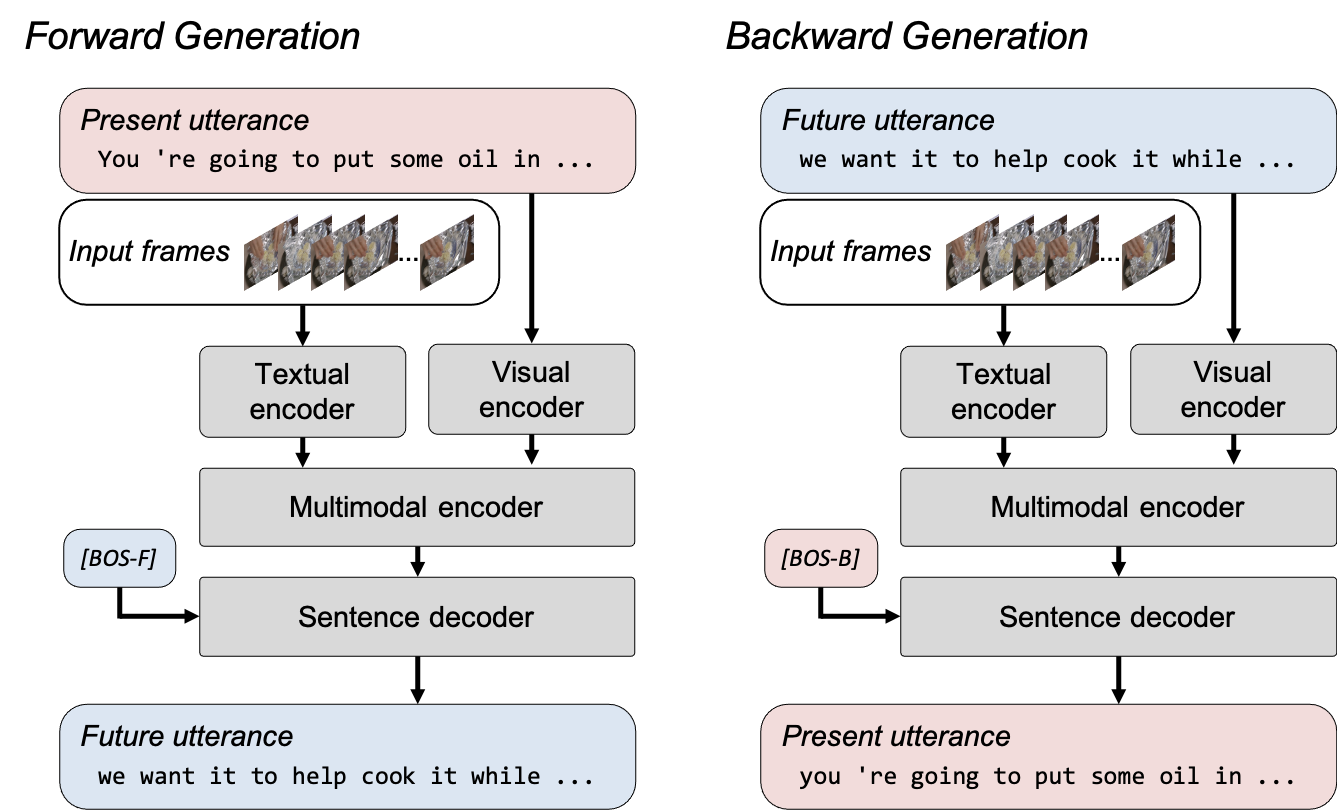 |
| Bi-directional era in MV-GPT. A mannequin is skilled with two era losses. In ahead era, the mannequin generates a future utterance (blue containers) given the frames and the current utterance (pink containers), whereas the current is generated from the longer term utterance in backward era. Two particular beginning-of-sentence tokens ([BOS-F] and [BOS-B]) provoke ahead and backward era for the decoder. |
Outcomes on Multimodal Video Captioning
We examine MV-GPT to present pre-training losses utilizing the identical mannequin structure, on YouCook2 with normal analysis metrics (Bleu-4, Cider, Meteor and Rouge-L). Whereas all pre-training methods enhance captioning performances, it’s crucial to pre-train the decoder collectively to enhance mannequin efficiency. We display that MV-GPT outperforms the earlier state-of-the-art joint pre-training technique by over 3.5% with relative beneficial properties throughout all 4 metrics.
| Pre-training Loss | Pre-trained Components | Bleu-4 | Cider | Meteor | Rouge-L |
| No Pre-training | N/A | 13.25 | 1.03 | 17.56 | 35.48 |
| CoMVT | Encoder | 14.46 | 1.24 | 18.46 | 37.17 |
| UniVL | Encoder + Decoder | 19.95 | 1.98 | 25.27 | 46.81 |
| MV-GPT (ours) | Encoder + Decoder | 21.26 | 2.14 | 26.36 | 48.58 |
| MV-GPT efficiency throughout 4 metrics (Bleu-4, Cider, Meteor and Rouge-L) of various pre-training losses on YouCook2. “Pre-trained components” signifies which components of the mannequin are pre-trained — solely the encoder or each the encoder and decoder. We reimplement the loss features of present strategies however use our mannequin and coaching methods for a good comparability. | ||||
We switch a mannequin pre-trained by MV-GPT to 4 completely different captioning benchmarks: YouCook2, MSR-VTT, ViTT and ActivityNet-Captions. Our mannequin achieves state-of-the-art efficiency on all 4 benchmarks by important margins. As an example on the Meteor metric, MV-GPT exhibits over 12% relative enhancements in all 4 benchmarks.
| YouCook2 | MSR-VTT | ViTT | ActivityNet-Captions | |
| Finest Baseline | 22.35 | 29.90 | 11.00 | 10.90 |
| MV-GPT (ours) | 27.09 | 38.66 | 26.75 | 12.31 |
| Meteor metric scores of the most effective baseline strategies and MV-GPT on 4 benchmarks. | ||||
Outcomes on Non-generative Video Understanding Duties
Though MV-GPT is designed to coach a generative mannequin for multimodal video captioning, we additionally discover that our pre-training approach learns a strong multimodal video encoder that may be utilized to a number of video understanding duties, together with VideoQA, text-video retrieval and motion classification. When in comparison with the most effective comparable baseline fashions, the mannequin transferred from MV-GPT exhibits superior efficiency in 5 video understanding benchmarks on their main metrics — i.e., top-1 accuracy for VideoQA and motion classification benchmarks, and recall at 1 for the retrieval benchmark.
| Job | Benchmark | Finest Comparable Baseline | MV-GPT |
| VideoQA | MSRVTT-QA | 41.5 | 41.7 |
| ActivityNet-QA | 38.9 | 39.1 | |
| Textual content-Video Retrieval | MSR-VTT | 33.7 | 37.3 |
| Motion Recognition | Kinetics-400 | 78.9 | 80.4 |
| Kinetics-600 | 80.6 | 82.4 |
| Comparisons of MV-GPT to greatest comparable baseline fashions on 5 video understanding benchmarks. For every dataset we report the broadly used main metric, i.e., MSRVTT-QA and ActivityNet-QA: High-1 reply accuracy; MSR-VTT: Recall at 1; and Kinetics: High-1 classification accuracy. | ||||
Abstract
We introduce MV-GPT, a brand new generative pre-training framework for multimodal video captioning. Our bi-directional generative goal collectively pre-trains a multimodal encoder and a caption decoder through the use of utterances sampled at completely different instances in unlabelled movies. Our pre-trained mannequin achieves state-of-the-art outcomes on a number of video captioning benchmarks and different video understanding duties, particularly VideoQA, video retrieval and motion classification.
Acknowledgements
This analysis was performed by Paul Hongsuck Search engine optimization, Arsha Nagrani, Anurag Arnab and Cordelia Schmid.
[ad_2]