
[ad_1]

{kind=link}
| “The mind is ready to use data coming from the pores and skin as if it had been coming from the eyes. We don’t see with the eyes or hear with the ears, these are simply the receptors, seeing and listening to in reality goes on within the mind.” |
| — Paul Bach-y-Rita1 |
Individuals have the wonderful skill to make use of one sensory modality (e.g., contact) to provide environmental data usually gathered by one other sense (e.g., imaginative and prescient). This adaptive skill, referred to as sensory substitution, is a phenomenon well-known to neuroscience. Whereas tough diversifications — equivalent to adjusting to seeing issues upside-down, studying to journey a “backwards” bicycle, or studying to “see” by decoding visible data emitted from a grid of electrodes positioned on one’s tongue — require wherever from weeks, months and even years to realize mastery, persons are capable of finally modify to sensory substitutions.
 |
 |
In distinction, most neural networks are usually not capable of adapt to sensory substitutions in any respect. As an illustration, most reinforcement studying (RL) brokers require their inputs to be in a pre-specified format, or else they may fail. They count on fixed-size inputs and assume that every ingredient of the enter carries a exact that means, such because the pixel depth at a specified location, or state data, like place or velocity. In widespread RL benchmark duties (e.g., Ant or Cart-pole), an agent skilled utilizing present RL algorithms will fail if its sensory inputs are modified or if the agent is fed extra noisy inputs which might be unrelated to the duty at hand.
In “The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Studying”, a highlight paper at NeurIPS 2021, we discover permutation invariant neural community brokers, which require every of their sensory neurons (receptors that obtain sensory inputs from the atmosphere) to determine the that means and context of its enter sign, moderately than explicitly assuming a set that means. Our experiments present that such brokers are sturdy to observations that include extra redundant or noisy data, and to observations which might be corrupt and incomplete.
 |
 |
| Permutation invariant reinforcement studying brokers adapting to sensory substitutions. Left: The ordering of the ant’s 28 observations are randomly shuffled each 200 time-steps. Not like the usual coverage, our coverage just isn’t affected by the abruptly permuted inputs. Proper: Cart-pole agent given many redundant noisy inputs (Interactive web-demo). |
Along with adapting to sensory substitutions in state-observation environments (just like the ant and cart-pole examples), we present that these brokers also can adapt to sensory substitutions in advanced visual-observation environments (equivalent to a CarRacing sport that makes use of solely pixel observations) and might carry out when the stream of enter photos is consistently being reshuffled:
 |
 |
| We partition the visible enter from CarRacing right into a 2D grid of small patches, and shuffled their ordering. With none extra coaching, our agent nonetheless performs even when the unique coaching background (left) is changed with new photos (proper). |
Technique
Our method takes observations from the atmosphere at every time-step and feeds every ingredient of the commentary into distinct, however similar neural networks (referred to as “sensory neurons”), every with no fastened relationship with each other. Every sensory neuron integrates over time data from solely their explicit sensory enter channel. As a result of every sensory neuron receives solely a small a part of the complete image, they should self-organize via communication to ensure that a worldwide coherent conduct to emerge.
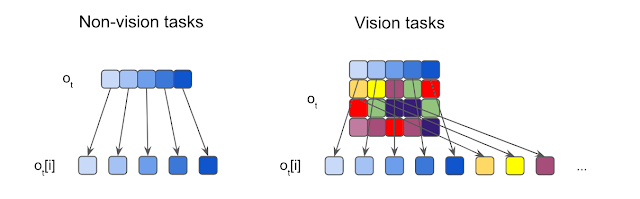 |
| Illustration of commentary segmentation.We section every enter into components, that are then fed to unbiased sensory neurons. For non-vision duties the place the inputs are normally 1D vectors, every ingredient is a scalar. For imaginative and prescient duties, we crop every enter picture into non-overlapping patches. |
We encourage neurons to speak with one another by coaching them to broadcast messages. Whereas receiving data regionally, every particular person sensory neuron additionally frequently broadcasts an output message at every time-step. These messages are consolidated and mixed into an output vector, referred to as the international latent code, utilizing an consideration mechanism much like that utilized within the Transformer structure. A coverage community then makes use of the worldwide latent code to supply the motion that the agent will use to work together with the atmosphere. This motion can also be fed again into every sensory neuron within the subsequent time-step, closing the communication loop.
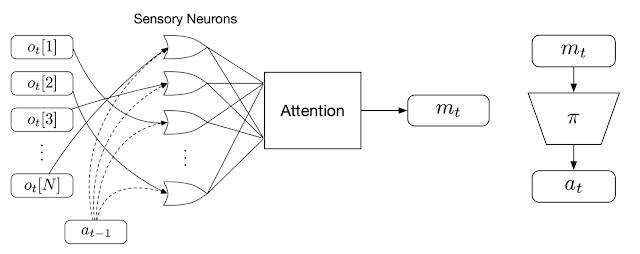 |
| Overview of the permutation-invariant RL technique. We first feed every particular person commentary (ot) into a selected sensory neuron (together with the agent’s earlier motion, at-1). Every neuron then produces and broadcasts a message independently, and an consideration mechanism summarizes them into a worldwide latent code (mt) that’s given to the agent’s downstream coverage community (𝜋) to supply the agent’s motion at. |
Why is this technique permutation invariant? Every sensory neuron is a similar neural community that’s not confined to solely course of data from one explicit sensory enter. In reality, in our setup, the inputs to every sensory neuron are usually not outlined. As a substitute, every neuron should determine the that means of its enter sign by listening to the inputs obtained by the opposite sensory neurons, moderately than explicitly assuming a set that means. This encourages the agent to course of the complete enter as an unordered set, making the system to be permutation invariant to its enter. Moreover, in precept, the agent can use as many sensory neurons as required, thus enabling it to course of observations of arbitrary size. Each of those properties will assist the agent adapt to sensory substitutions.
Outcomes
We display the robustness and adaptability of this method in less complicated, state-observation environments, the place the observations the agent receives as inputs are low-dimensional vectors holding details about the agent’s states, such because the place or velocity of its parts. The agent within the widespread Ant locomotion activity has a complete of 28 inputs with data that features positions and velocities. We shuffle the order of the enter vector a number of instances throughout a trial and present that the agent is quickly capable of adapt and continues to be capable of stroll ahead.
In cart-pole, the agent’s purpose is to swing up a cart-pole mounted on the middle of the cart and stability it upright. Usually the agent sees solely 5 inputs, however we modify the cartpole atmosphere to supply 15 shuffled enter alerts, 10 of that are pure noise, and the rest of that are the precise observations from the atmosphere. The agent continues to be capable of carry out the duty, demonstrating the system’s capability to work with a lot of inputs and attend solely to channels it deems helpful. Such flexibility might discover helpful functions for processing a big unspecified variety of alerts, most of that are noise, from ill-defined techniques.
We additionally apply this method to high-dimensional vision-based environments the place the commentary is a stream of pixel photos. Right here, we examine screen-shuffled variations of vision-based RL environments, the place every commentary body is split right into a grid of patches, and like a puzzle, the agent should course of the patches in a shuffled order to find out a plan of action to take. To display our method on vision-based duties, we created a shuffled model of Atari Pong.
 |
 |
| Shuffled Pong outcomes. Left: Pong agent skilled to play utilizing solely 30% of the patches matches efficiency of Atari opponent. Proper: With out additional coaching, after we give the agent extra puzzle items, its efficiency will increase. |
Right here the agent’s enter is a variable-length listing of patches, so not like typical RL brokers, the agent solely will get to “see” a subset of patches from the display screen. Within the puzzle pong experiment, we go to the agent a random pattern of patches throughout the display screen, that are then fastened via the rest of the sport. We discover that we are able to discard 70% of the patches (at these fixed-random areas) and nonetheless prepare the agent to carry out nicely towards the built-in Atari opponent. Curiously, if we then reveal extra data to the agent (e.g., permitting it entry to extra picture patches), its efficiency will increase, even with out extra coaching. When the agent receives all of the patches, in shuffled order, it wins 100% of the time, attaining the identical end result with brokers which might be skilled whereas seeing the complete display screen.
We discover that imposing extra issue throughout coaching by utilizing unordered observations has extra advantages, equivalent to bettering generalization to unseen variations of the duty, like when the background of the CarRacing coaching atmosphere is changed with a novel picture.
 |
 |
| Shuffled CarRacing outcomes. The agent has realized to focus its consideration (indicated by the highlighted patches) on the street boundaries. Left: Coaching atmosphere. Proper: Take a look at atmosphere with new background. |
Conclusion
The permutation invariant neural community brokers offered right here can deal with ill-defined, various commentary areas. Our brokers are sturdy to observations that include redundant or noisy data, or observations which might be corrupt and incomplete. We imagine that permutation invariant techniques open up quite a few potentialities in reinforcement studying.
In case you’re to be taught extra about this work, we invite readers to learn our interactive article (pdf model) or watch our video. We additionally launched code to breed our experiments.
1Quoted in Livewired, by David Eagleman. ↩
[ad_2]