
{kind=link}
[ad_1]
You’ve in all probability heard of Kaggle information science competitions, however do you know that Kaggle has many different options that may assist you along with your subsequent machine studying venture? For folks in search of datasets for his or her subsequent machine studying venture, Kaggle lets you entry public datasets by others and share your individual datasets. For these seeking to construct and prepare their very own machine studying fashions, Kaggle additionally presents an in-browser pocket book setting and a few free GPU hours. It’s also possible to have a look at different folks’s public notebooks as properly!
Aside from the web site, Kaggle additionally has a command-line interface (CLI) which you should utilize inside the command line to entry and obtain datasets.
Let’s dive proper in and discover what Kaggle has to supply!
After finishing this tutorial, you’ll be taught:
- What’s Kaggle?
- How you should utilize Kaggle as a part of your machine studying pipeline
- Utilizing Kaggle API’s Command Line Interface (CLI)
Let’s get began!

Utilizing Kaggle in Machine Studying Initiatives
Picture by Stefan Widua. Some rights reserved.
Overview
This tutorial is break up into 5 components; they’re:
- What’s Kaggle?
- Organising Kaggle Notebooks
- Utilizing Kaggle Notebooks with GPUs/TPUs
- Utilizing Kaggle Datasets with Kaggle Notebooks
- Utilizing Kaggle Datasets with Kaggle CLI software
What Is Kaggle?
Kaggle might be most well-known for the information science competitions that it hosts, with a few of them providing 5-figure prize swimming pools and seeing a whole lot of groups taking part. Apart from these competitions, Kaggle additionally permits customers to publish and seek for datasets, which they’ll use for his or her machine studying tasks. To make use of these datasets, you should utilize Kaggle notebooks inside your browser or Kaggle’s public API to obtain their datasets which you’ll be able to then use on your machine studying tasks.
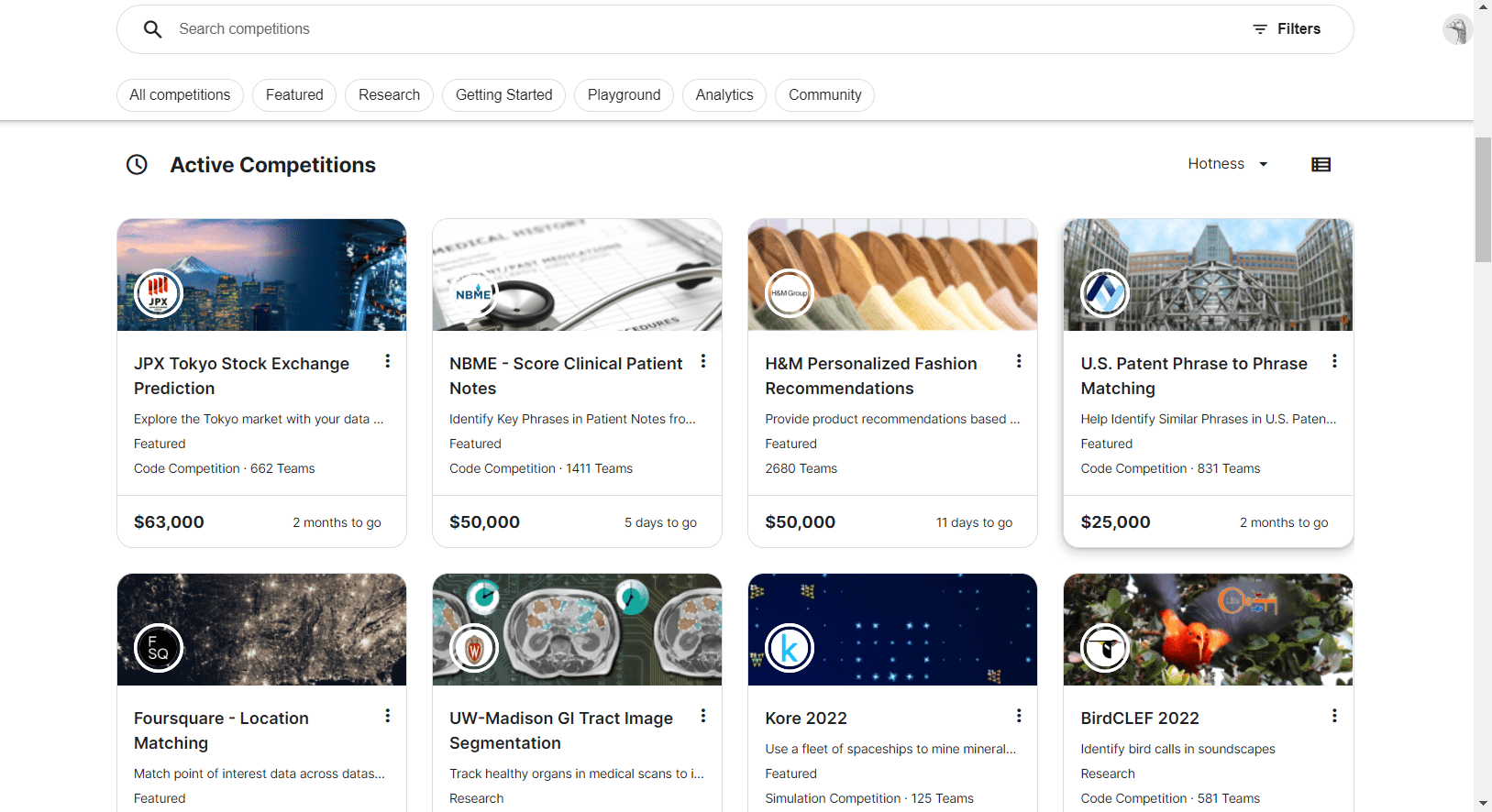
Kaggle Competitions
Along with that, Kaggle additionally presents some programs and a discussions web page so that you can be taught extra about machine studying and discuss with different machine studying practitioners!
For the remainder of this text, we’ll deal with how we will use Kaggle’s datasets and notebooks to assist us when engaged on our personal machine studying tasks or discovering new tasks to work on.
Organising Kaggle Notebooks
To get began with Kaggle Notebooks, you’ll must create a Kaggle account both utilizing an present Google account or creating one utilizing your e-mail.
Then, go to the “Code” web page.
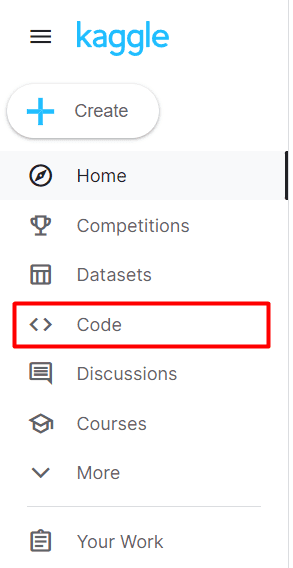
Left Sidebar of Kaggle Dwelling Web page, Code Tab
You’ll then be capable to see your individual notebooks in addition to public notebooks by others. To create your individual pocket book, click on on New Pocket book.
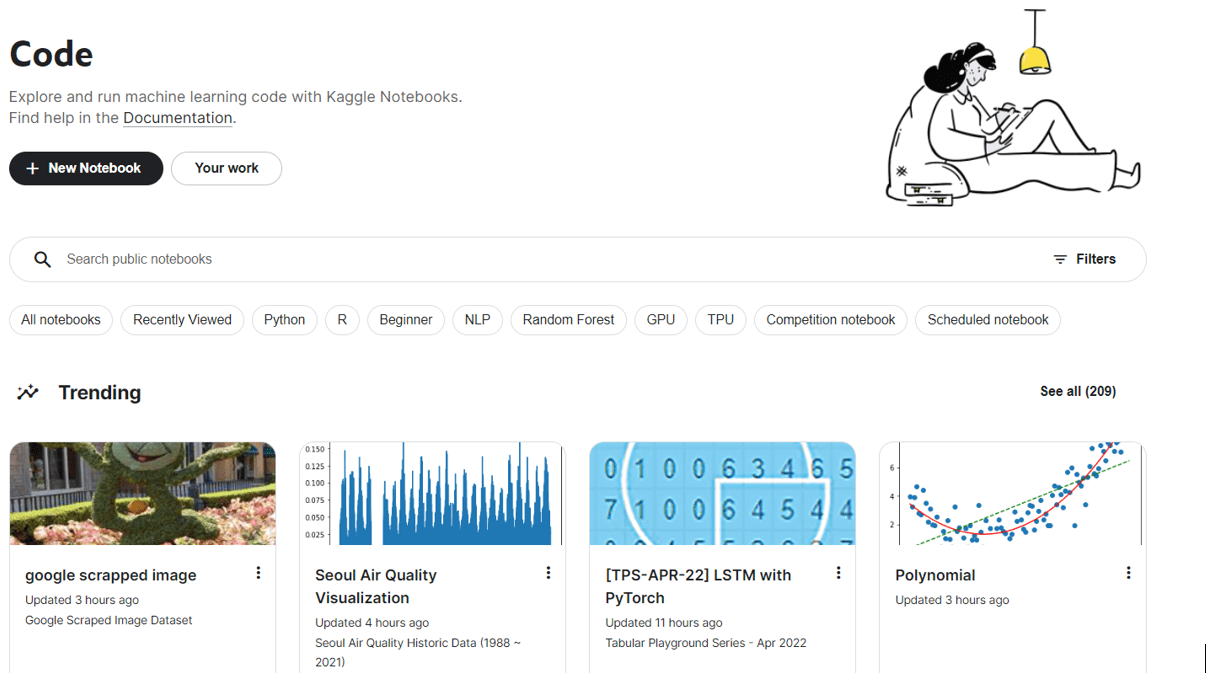
Kaggle Code Web page
It will create your new pocket book, which appears like a Jupyter pocket book, with many related instructions and shortcuts.
Kaggle Pocket book
It’s also possible to toggle between a pocket book editor and script editor by going to File -> Editor Sort.
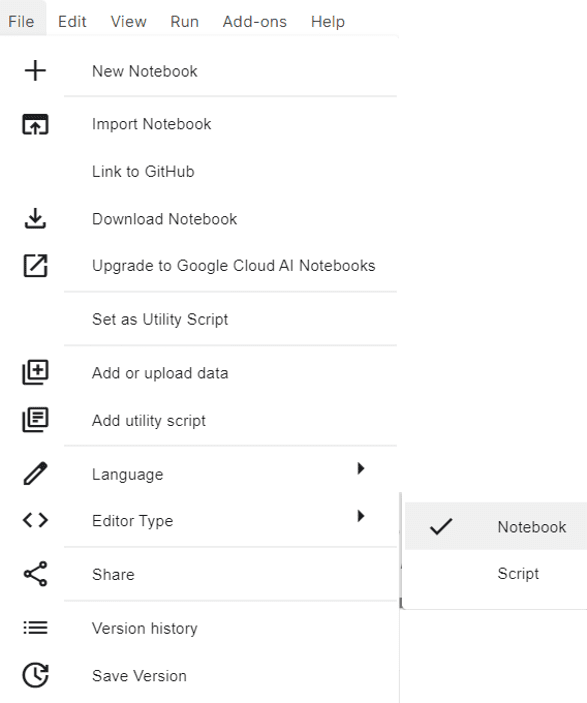
Altering Editor Sort in Kaggle Pocket book
Altering the editor sort to script exhibits this as a substitute:
Kaggle Pocket book Script Editor Sort
Utilizing Kaggle with GPUs/TPUs
Who doesn’t love free GPU time for machine studying tasks? GPUs may help to massively pace up the coaching and inference of machine studying fashions, particularly with deep studying fashions.
Kaggle comes with some free allocation of GPUs and TPUs, which you should utilize on your tasks. On the time of this writing, the supply is 30 hours per week for GPUs and 20 hours per week for TPUs after verifying your account with a cellphone quantity.
To connect an accelerator to your pocket book, go to Settings ▷ Setting ▷ Preferences.
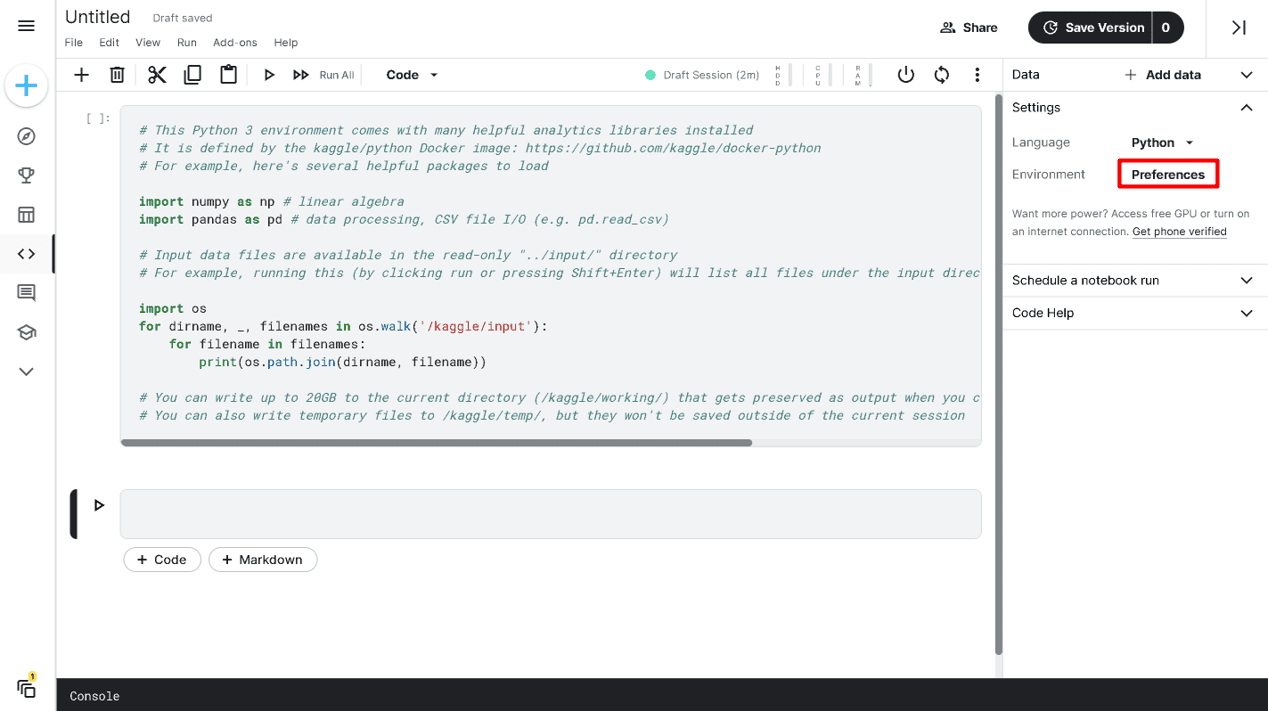
Altering Kaggle Pocket book Setting preferences
You’ll be requested to confirm your account with a cellphone quantity.

Confirm cellphone quantity
After which introduced with this web page which lists the quantity of availability you could have left and mentions that turning on GPUs will cut back the variety of CPUs obtainable, so it’s in all probability solely a good suggestion when doing coaching/inference with neural networks.

Including GPU Accelerator to Kaggle Pocket book
Utilizing Kaggle Datasets with Kaggle Notebooks
Machine studying tasks are data-hungry monsters, and discovering datasets for our present tasks or in search of datasets to start out new tasks is all the time a chore. Fortunately, Kaggle has a wealthy assortment of datasets contributed by customers and from competitions. These datasets could be a treasure trove for folks in search of information for his or her present machine studying venture or folks in search of new concepts for tasks.
Let’s discover how we will add these datasets to our Kaggle pocket book.
First, click on on Add information on the correct sidebar.
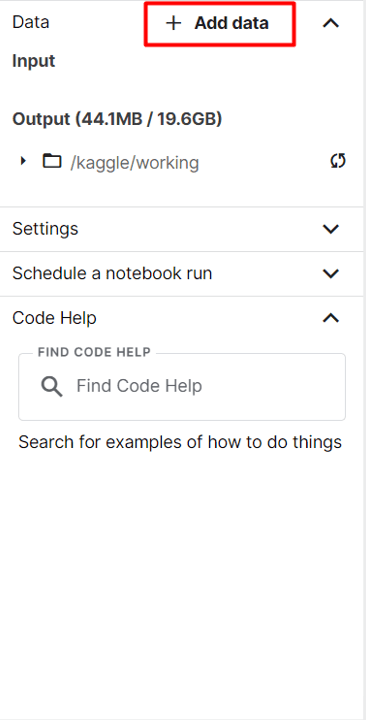
Including Datasets to Kaggle Pocket book Setting
A window ought to seem that exhibits you a number of the publicly obtainable datasets and offers you the choice to add your individual dataset to be used along with your Kaggle pocket book.
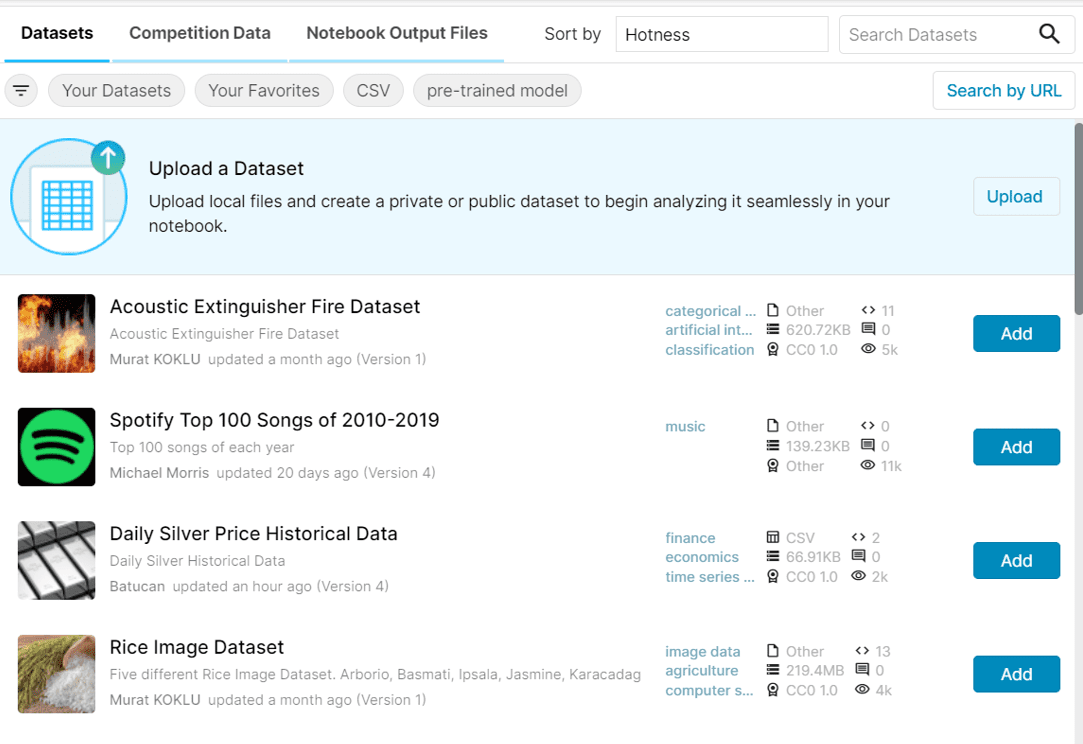
Looking out By Kaggle datasets
I’ll be utilizing the traditional titanic dataset as my instance for this tutorial, which you could find by keying your search phrases into the search bar on the highest proper of the window.
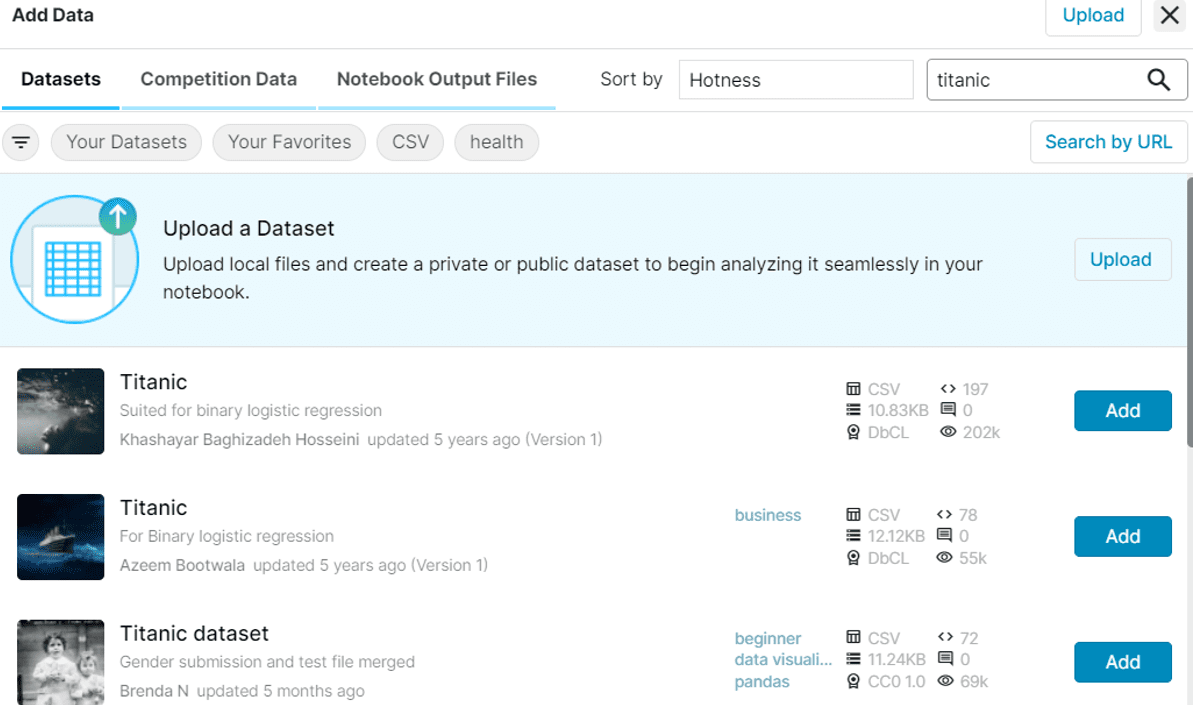
Kaggle Datasets Filtered with “Titanic” Key phrase
After that, the dataset is out there for use by the pocket book. To entry the information, check out the trail for the file and prepend ../enter/{path}. For instance, the file path for the titanic dataset is:
|
../enter/titanic/train_and_test2.csv |
Within the pocket book, we will learn the information utilizing:
|
import pandas
pandas.read_csv(“../enter/titanic/train_and_test2.csv”) |
This will get us the information from the file:
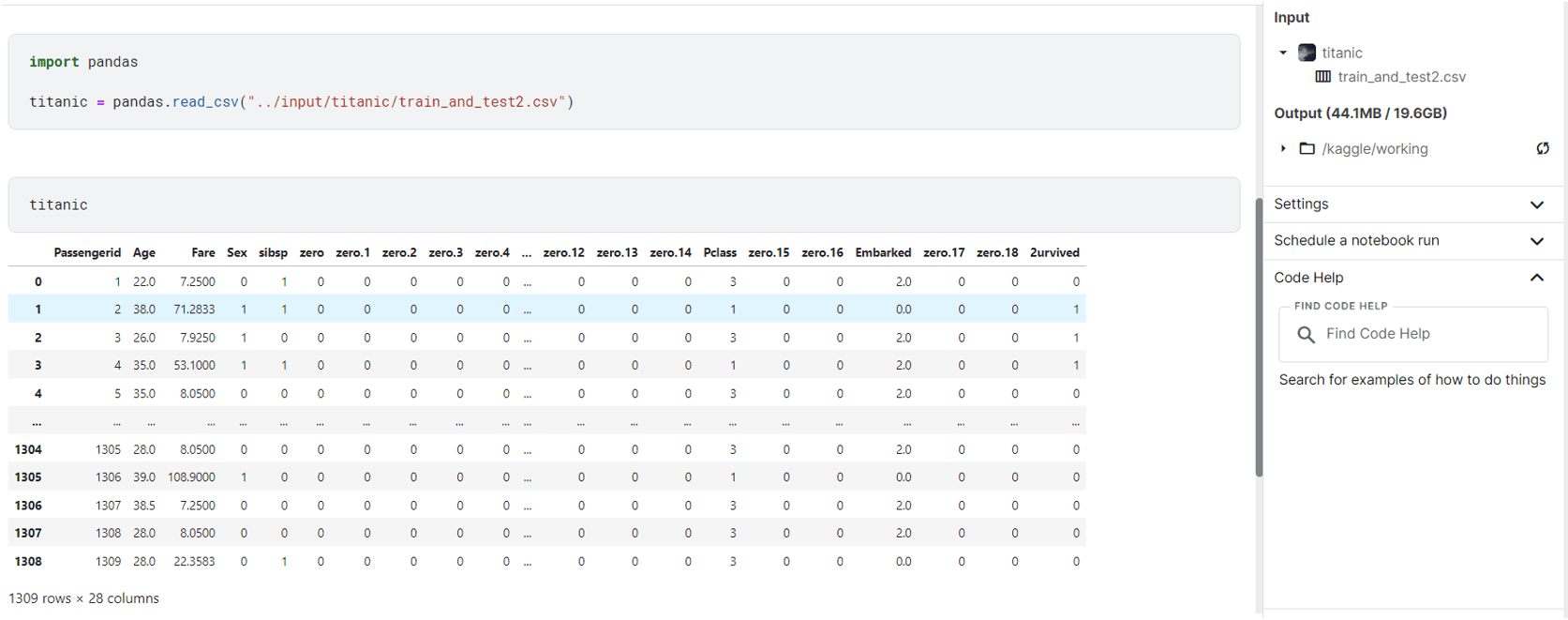
Utilizing Titanic Dataset in Kaggle Pocket book
Utilizing Kaggle Datasets with Kaggle CLI Device
Kaggle additionally has a public API with a CLI software which we will use to obtain datasets, work together with competitions, and way more. We’ll be taking a look at arrange and obtain Kaggle datasets utilizing the CLI software.
To get began, set up the CLI software utilizing:
For Mac/Linux customers, you would possibly want:
|
pip set up —person kaggle |
Then, you’ll must create an API token for authentication. Go to Kaggle’s webpage, click on in your profile icon within the prime proper nook and go to Account.
Going to Kaggle Account Settings
From there, scroll all the way down to Create New API Token:
Producing New API Token for Kaggle Public API
It will obtain a kaggle.json file that you simply’ll use to authenticate your self with the Kaggle CLI software. You’ll have to place it within the right location for it to work. For Linux/Mac/Unix-based working methods, this ought to be positioned at ~/.kaggle/kaggle.json, and for Home windows customers, it ought to be positioned at C:Customers<Home windows-username>.kagglekaggle.json. Putting it within the improper location and calling kaggle within the command line will give an error:
|
OSError: May not discover kaggle.json. Make positive it’s location in … Or use the setting technique |
Now, let’s get began on downloading these datasets!
To seek for datasets utilizing a search time period, e.g., titanic, we will use:
|
kaggle datasets checklist –s titanic |
Trying to find titanic, we get:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$ kaggle datasets checklist -s titanic ref title measurement lastUpdated downloadCount voteCount usabilityRating ———————————————————– ——————————————— —– ——————- ————- ——— ————— datasets/heptapod/titanic Titanic 11KB 2017-05-16 08:14:22 37681 739 0.7058824 datasets/azeembootwala/titanic Titanic 12KB 2017-06-05 12:14:37 13104 145 0.8235294 datasets/brendan45774/test-file Titanic dataset 11KB 2021-12-02 16:11:42 19348 251 1.0 datasets/rahulsah06/titanic Titanic 34KB 2019-09-16 14:43:23 3619 43 0.6764706 datasets/prkukunoor/TitanicDataset Titanic 135KB 2017-01-03 22:01:13 4719 24 0.5882353 datasets/hesh97/titanicdataset-traincsv Titanic-Dataset (prepare.csv) 22KB 2018-02-02 04:51:06 54111 377 0.4117647 datasets/fossouodonald/titaniccsv Titanic csv 1KB 2016-11-07 09:44:58 8615 50 0.5882353 datasets/broaniki/titanic titanic 717KB 2018-01-30 04:08:45 8004 128 0.1764706 datasets/pavlofesenko/titanic-extended Titanic prolonged dataset (Kaggle + Wikipedia) 134KB 2019-03-06 09:53:24 8779 130 0.9411765 datasets/jamesleslie/titanic-cleaned-data Titanic: cleaned information 36KB 2018-11-21 11:50:18 4846 53 0.7647059 datasets/kittisaks/testtitanic check titanic 22KB 2017-03-13 15:13:12 1658 32 0.64705884 datasets/yasserh/titanic-dataset Titanic Dataset 22KB 2021-12-24 14:53:06 1011 25 1.0 datasets/abhinavralhan/titanic titanic 22KB 2017-07-30 11:07:55 628 11 0.8235294 datasets/cities/titanic123 Titanic Dataset Evaluation 22KB 2017-02-07 23:15:54 1585 29 0.5294118 datasets/brendan45774/gender-submisson Titanic: all ones csv file 942B 2021-02-12 19:18:32 459 34 0.9411765 datasets/harunshimanto/titanic-solution-for-beginners-guide Titanic Answer for Newbie’s Information 34KB 2018-03-12 17:47:06 1444 21 0.7058824 datasets/ibrahimelsayed182/titanic-dataset Titanic dataset 6KB 2022-01-27 07:41:54 334 8 1.0 datasets/sureshbhusare/titanic-dataset-from-kaggle Titanic DataSet from Kaggle 33KB 2017-10-12 04:49:39 2688 27 0.4117647 datasets/shuofxz/titanic-machine-learning-from-disaster Titanic: Machine Studying from Catastrophe 33KB 2017-10-15 10:05:34 3867 55 0.29411766 datasets/vinicius150987/titanic3 The Full Titanic Dataset 277KB 2020-01-04 18:24:11 1459 23 0.64705884 |
To obtain the primary dataset in that checklist, we will use:
|
kaggle datasets obtain –d heptapod/titanic —unzip |
Utilizing a Jupyter pocket book to learn the file, much like the Kaggle pocket book instance, provides us:
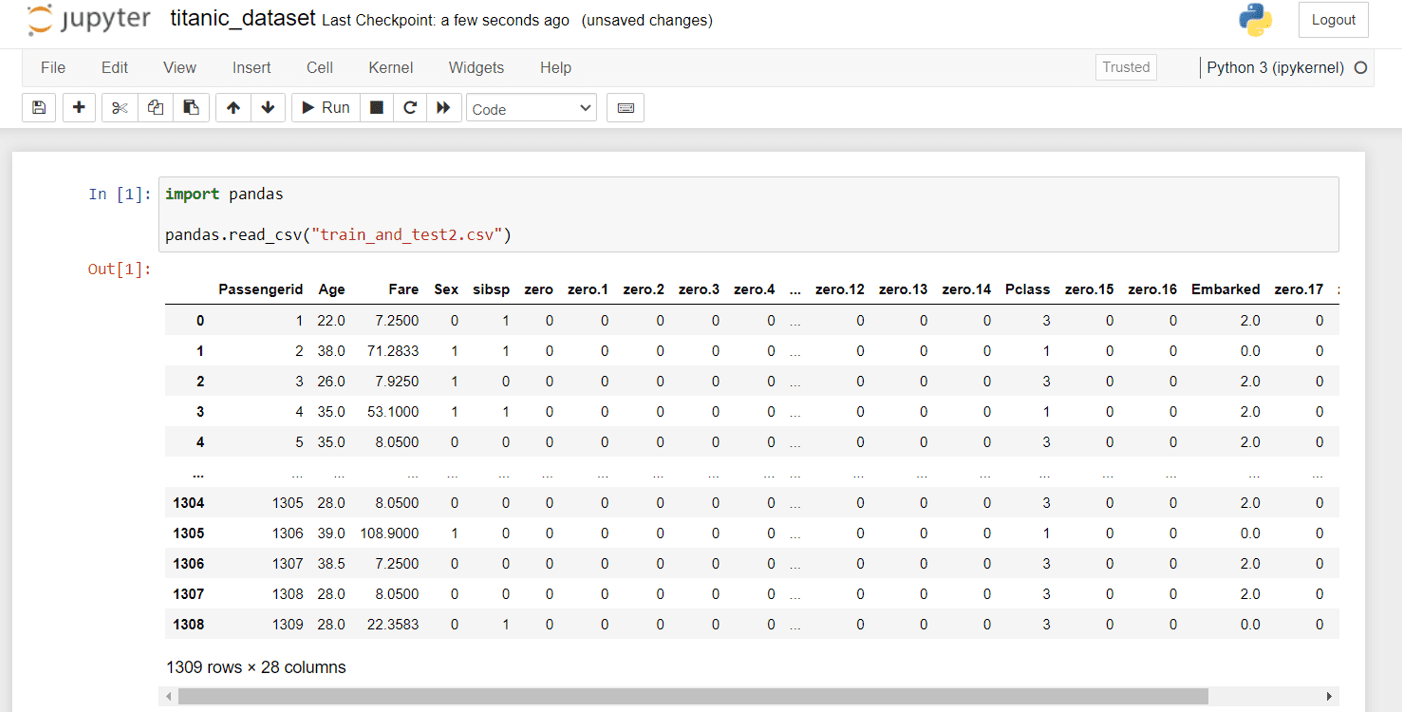
Utilizing Titanic Dataset in Jupyter Pocket book
In fact, some datasets are so giant in measurement that you could be not need to hold them by yourself disk. Nonetheless, this is likely one of the free sources offered by Kaggle on your machine studying tasks!
Additional Studying
This part offers extra sources if you happen to’re fascinated by going deeper into the subject.
Abstract
On this tutorial, you discovered what Kaggle is , how we will use Kaggle to get datasets, and even for some free GPU/TPU situations inside Kaggle Notebooks. You’ve additionally seen how we will use Kaggle API’s CLI software to obtain datasets for us to make use of in our native environments.
Particularly, you learnt:
- What’s Kaggle
- use Kaggle notebooks together with their GPU/TPU accelerator
- use Kaggle datasets in Kaggle notebooks or obtain them utilizing Kaggle’s CLI software
[ad_2]