

{kind=link}
[ad_1]
We’re touring by means of the period of Software program 2.0, through which the important thing parts of recent software program are more and more decided by the parameters of machine studying fashions, slightly than hard-coded within the language of for loops and if-else statements. There are critical challenges with such software program and fashions, together with the info they’re educated on, how they’re developed, how they’re deployed, and their affect on stakeholders. These challenges generally end in each algorithmic bias and lack of mannequin interpretability and explainability.
There’s one other essential difficulty, which is in some methods upstream to the challenges of bias and explainability: whereas we appear to be dwelling sooner or later with the creation of machine studying and deep studying fashions, we’re nonetheless dwelling within the Darkish Ages with respect to the curation and labeling of our coaching information: the overwhelming majority of labeling continues to be finished by hand.

Be taught quicker. Dig deeper. See farther.
There are important points with hand labeling information:
- It introduces bias, and hand labels are neither interpretable nor explainable.
- There are prohibitive prices handy labeling datasets (each monetary prices and the time of material specialists).
- There isn’t a such factor as gold labels: even essentially the most well-known hand labeled datasets have label error charges of no less than 5% (ImageNet has a label error charge of 5.8%!).
We live by means of an period through which we get to determine how human and machine intelligence work together to construct clever software program to deal with lots of the world’s hardest challenges. Labeling information is a basic a part of human-mediated machine intelligence, and hand labeling will not be solely essentially the most naive method but in addition probably the most costly (in lots of senses) and most harmful methods of bringing people within the loop. Furthermore, it’s simply not obligatory as many alternate options are seeing rising adoption. These embrace:
- Semi-supervised studying
- Weak supervision
- Switch studying
- Lively studying
- Artificial information technology
These methods are a part of a broader motion often called Machine Educating, a core tenet of which is getting each people and machines every doing what they do finest. We have to use experience effectively: the monetary price and time taken for specialists to hand-label each information level can break initiatives, reminiscent of diagnostic imaging involving life-threatening situations and safety and defense-related satellite tv for pc imagery evaluation. Hand labeling within the age of those different applied sciences is akin to scribes hand-copying books post-Gutenberg.
There may be additionally a burgeoning panorama of firms constructing merchandise round these applied sciences, reminiscent of Watchful (weak supervision and lively studying; disclaimer: one of many authors is CEO of Watchful), Snorkel (weak supervision), Prodigy (lively studying), Parallel Area (artificial information), and AI Reverie (artificial information).
Hand Labels and Algorithmic Bias
As Deb Raji, a Fellow on the Mozilla Basis, has identified, algorithmic bias “can begin anyplace within the system—pre-processing, post-processing, with job design, with modeling decisions, and many others.,” and the labeling of knowledge is a vital level at which bias can creep in.
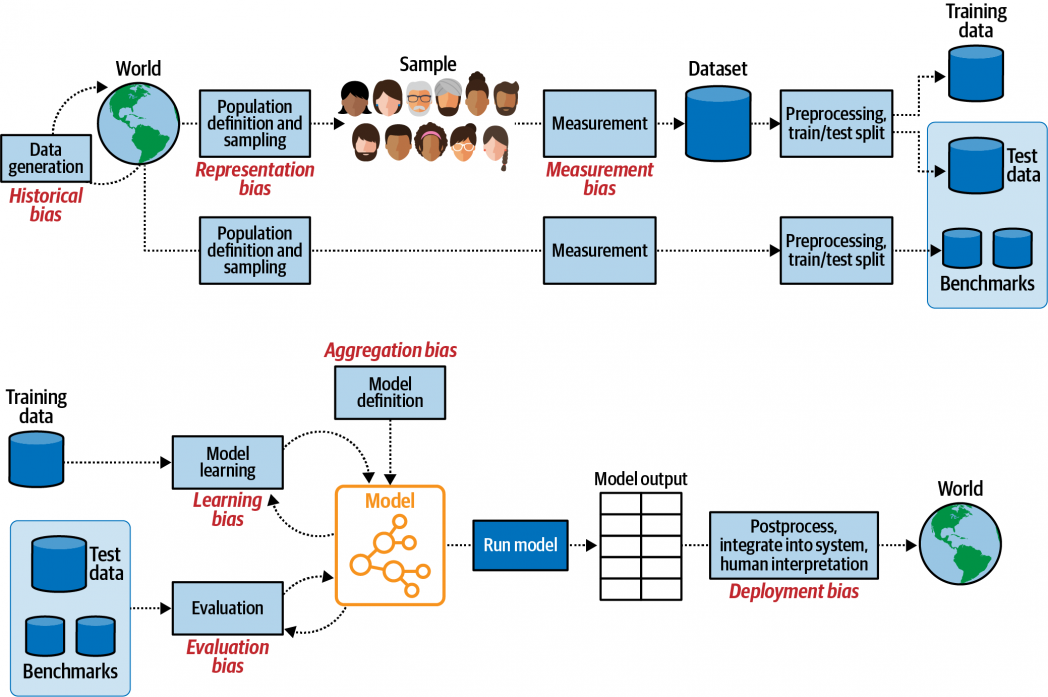
Excessive-profile circumstances of bias in coaching information leading to dangerous fashions embrace an Amazon recruiting device that “penalized resumes that included the phrase ‘girls’s,’ as in ‘girls’s chess membership captain.’” Don’t take our phrase for it. Play the tutorial sport Survival of the Finest Match the place you’re a CEO who makes use of a machine studying mannequin to scale their hiring selections and see how the mannequin replicates the bias inherent within the coaching information. This level is vital: as people, we possess all kinds of biases, some dangerous, others not so. Once we feed hand labeled information to a machine studying mannequin, it’s going to detect these patterns and replicate them at scale. Because of this David Donoho astutely noticed that maybe we must always name ML fashions recycled intelligence slightly than synthetic intelligence. In fact, given the quantity of bias in hand labeled information, it could be extra apt to seek advice from it as recycled stupidity (hat tip to synthetic stupidity).
The one method to interrogate the explanations for underlying bias arising from hand labels is to ask the labelers themselves their rationales for the labels in query, which is impractical, if not unattainable, within the majority of circumstances: there are not often data of who did the labeling, it’s typically outsourced by way of at-scale world APIs, reminiscent of Amazon’s Mechanical Turk and, when labels are created in-house, earlier labelers are sometimes now not a part of the group.
Uninterpretable, Unexplainable
This results in one other key level: the shortage of each interpretability and explainability in fashions constructed available labeled information. These are associated ideas, and broadly talking, interpretability is about correlation, whereas explainability is about causation. The previous entails desirous about which options are correlated with the output variable, whereas the latter is anxious with why sure options result in specific labels and predictions. We wish fashions that give us outcomes we will clarify and a few notion of how or why they work. For instance, within the ProPublica exposé of COMPAS recidivism threat mannequin, which made extra false predictions that Black folks would re-offend than it did for white folks, it’s important to grasp why the mannequin is making the predictions it does. Lack of explainability and transparency had been key elements of all of the deployed-at-scale algorithms recognized by Cathy O’Neil in Weapons of Math Destruction.
It might be counterintuitive that getting machines extra in-the-loop for labeling may end up in extra explainable fashions however think about a number of examples:
- There’s a rising space of weak supervision, through which SMEs specify heuristics that the system then makes use of to make inferences about unlabeled information, the system calculates some potential labels, after which the SME evaluates the labels to find out the place extra heuristics would possibly should be added or tweaked. For instance, when constructing a mannequin of whether or not surgical procedure was obligatory primarily based on medical transcripts, the SME could present the next heuristic: if the transcription comprises the time period “anaesthesia” (or a daily expression much like it), then surgical procedure possible occurred (try Russell Jurney’s “Hand labeling is the previous” article for extra on this).
- In diagnostic imaging, we have to begin cracking open the neural nets (reminiscent of CNNs and transformers)! SMEs might as soon as once more use heuristics to specify that tumors smaller than a sure measurement and/or of a specific form are benign or malignant and, by means of such heuristics, we might drill down into totally different layers of the neural community to see what representations are realized the place.
- When your data (by way of labels) is encoded in heuristics and features, as above, this additionally has profound implications for fashions in manufacturing. When information drift inevitably happens, you possibly can return to the heuristics encoded in features and edit them, as an alternative of regularly incurring the prices of hand labeling.
On Auditing
Amidst the rising concern about mannequin transparency, we’re seeing requires algorithmic auditing. Audits will play a key position in figuring out how algorithms are regulated and which of them are protected for deployment. One of many limitations to auditing is that high-performing fashions, reminiscent of deep studying fashions, are notoriously troublesome to elucidate and purpose about. There are a number of methods to probe this on the mannequin stage (reminiscent of SHAP and LIME), however that solely tells a part of the story. As we’ve seen, a serious explanation for algorithmic bias is that the info used to coach it’s biased or inadequate indirectly.
There at the moment aren’t some ways to probe for bias or insufficiency on the information stage. For instance, the one method to clarify hand labels in coaching information is to speak to the individuals who labeled it. Lively studying, then again, permits for the principled creation of smaller datasets which have been intelligently sampled to maximise utility for a mannequin, which in flip reduces the general auditable floor space. An instance of lively studying can be the next: as an alternative of hand labeling each information level, the SME can label a consultant subset of the info, which the system makes use of to make inferences concerning the unlabeled information. Then the system will ask the SME to label among the unlabeled information, cross-check its personal inferences and refine them primarily based on the SME’s labels. That is an iterative course of that terminates as soon as the system reaches a goal accuracy. Much less information means much less headache with respect to auditability.
Weak supervision extra straight encodes experience (and therefore bias) as heuristics and features, making it simpler to guage the place labeling went awry. For extra opaque strategies, reminiscent of artificial information technology, it may be a bit troublesome to interpret why a specific label was utilized, which can really complicate an audit. The strategies we select at this stage of the pipeline are necessary if we wish to be sure the system as a complete is explainable.
The Prohibitive Prices of Hand Labeling
There are important and differing types of prices related to hand labeling. Big industries have been erected to cope with the demand for data-labeling providers. Look no additional than Amazon Mechanical Turk and all different cloud suppliers at present. It’s telling that information labeling is turning into more and more outsourced globally, as detailed by Mary Grey in Ghost Work, and there are more and more critical considerations concerning the labor situations beneath which hand labelers work across the globe.
The sheer quantity of capital concerned was evidenced by Scale AI elevating $100 million in 2019 to convey their valuation to over $1 billion at a time when their enterprise mannequin solely revolved round utilizing contractors handy label information (it’s telling that they’re now doing greater than solely hand labels).
Cash isn’t the one price, and very often, isn’t the place the bottleneck or rate-limiting step happens. Slightly, it’s the bandwidth and time of specialists that’s the scarcest useful resource. As a scarce useful resource, that is typically costly however, a lot of the time it isn’t even accessible (on high of this, the time it additionally takes to appropriate errors in labeling by information scientists may be very costly). Take monetary providers, for instance, and the query of whether or not or not you must put money into an organization primarily based on details about the corporate scraped from varied sources. In such a agency, there’ll solely be a small handful of people that could make such a name, so labeling every information level can be extremely costly, and that’s if the SME even has the time.
This isn’t vertical-specific. The identical problem happens in labeling authorized texts for classification: is that this clause speaking about indemnification or not? And in medical analysis: is that this tumor benign or malignant? As dependence on experience will increase, so does the chance that restricted entry to SMEs turns into a bottleneck.
The third price is a value to accuracy, actuality, and floor reality: the truth that hand labels are sometimes so incorrect. The authors of a current examine from MIT recognized “label errors within the check units of 10 of essentially the most commonly-used pc imaginative and prescient, pure language, and audio datasets.” They estimated a mean error charge of three.4% throughout the datasets and present that ML mannequin efficiency will increase considerably as soon as labels are corrected, in some cases. Additionally, think about that in lots of circumstances floor reality isn’t straightforward to seek out, if it exists in any respect. Weak supervision makes room for these circumstances (that are the bulk) by assigning probabilistic labels with out counting on floor reality annotations. It’s time to assume statistically and probabilistically about our labels. There may be good work occurring right here, reminiscent of Aka et al.’s (Google) current paper Measuring Mannequin Biases within the Absence of Floor Fact.
The prices recognized above are usually not one-off. Once you practice a mannequin, you need to assume you’re going to coach it once more if it lives in manufacturing. Relying on the use case, that may very well be frequent. Should you’re labeling by hand, it’s not simply a big upfront price to construct a mannequin. It’s a set of ongoing prices each time.

The Efficacy of Automation Methods
By way of efficiency, even when getting machines to label a lot of your information ends in barely noisier labels, your fashions are sometimes higher off with 10 instances as many barely noisier labels. To dive a bit deeper into this, there are beneficial properties to be made by rising coaching set measurement even when it means lowering general label accuracy, however in case you’re coaching classical ML fashions, solely up to some extent (previous this level the mannequin begins to see a dip in predictive accuracy). “Scaling to Very Very Giant Corpora for Pure Language Disambiguation (Banko & Brill, 2001)” demonstrates this in a conventional ML setting by exploring the connection between hand labeled information, mechanically labeled information, and subsequent mannequin efficiency. A newer paper, “Deep Studying Scaling Is Predictable, Empirically (2017)”, explores the amount/high quality relationship relative to trendy cutting-edge mannequin architectures, illustrating the truth that SOTA architectures are information hungry, and accuracy improves as an influence regulation as coaching units develop:
We empirically validate that DL mannequin accuracy improves as a power-law as we develop coaching units for state-of-the-art (SOTA) mannequin architectures in 4 machine studying domains: machine translation, language modeling, picture processing, and speech recognition. These power-law studying curves exist throughout all examined domains, mannequin architectures, optimizers, and loss features.
The important thing query isn’t “ought to I hand label my coaching information or ought to I label it programmatically?” It ought to as an alternative be “which elements of my information ought to I hand label and which elements ought to I label programmatically?” In response to these papers, by introducing costly hand labels sparingly into largely programmatically generated datasets, you possibly can maximize the hassle/mannequin accuracy tradeoff on SOTA architectures that wouldn’t be doable in case you had hand labeled alone.
The stacked prices of hand labeling wouldn’t be so difficult had been they obligatory, however the truth of the matter is that there are such a lot of different attention-grabbing methods to get human data into fashions. There’s nonetheless an open query round the place and the way we wish people within the loop and what’s the precise design for these programs. Areas reminiscent of weak supervision, self-supervised studying, artificial information technology, and lively studying, for instance, together with the merchandise that implement them, present promising avenues for avoiding the pitfalls of hand labeling. People belong within the loop on the labeling stage, however so do machines. Briefly, it’s time to maneuver past hand labels.
Many due to Daeil Kim for suggestions on a draft of this essay.
[ad_2]