
[ad_1]
Fig 1. Measures of generalization efficiency for neural networks educated on 4 totally different boolean features (colours) with various coaching set dimension. For each MSE (left) and learnability (proper), theoretical predictions (curves) carefully match true efficiency (dots).
Deep studying has confirmed a surprising success for numerous issues of curiosity, however this success belies the truth that, at a elementary degree, we don’t perceive why it really works so properly. Many empirical phenomena, well-known to deep studying practitioners, stay mysteries to theoreticians. Maybe the best of those mysteries has been the query of generalization: why do the features realized by neural networks generalize so properly to unseen information? From the angle of classical ML, neural nets’ excessive efficiency is a shock on condition that they’re so overparameterized that they may simply symbolize numerous poorly-generalizing features.
Questions starting in “why” are troublesome to get a grip on, so we as a substitute take up the next quantitative drawback: given a community structure, a goal operate $f$, and a coaching set of $n$ random examples, can we effectively predict the generalization efficiency of the community’s realized operate $hat{f}$? A principle doing this may not solely clarify why neural networks generalize properly on sure features however would additionally inform us which operate lessons a given structure is well-suited for and probably even allow us to select the perfect structure for a given drawback from first ideas, in addition to serving as a basic framework for addressing a slew of different deep studying mysteries.
It seems that is attainable: in our latest paper, we derive a first-principles principle that permits one to make correct predictions of neural community generalization (no less than in sure settings). To take action, we make a series of approximations, first approximating an actual community as an idealized infinite-width community, which is thought to be equal to kernel regression, then deriving new approximate outcomes for the generalization of kernel regression to yield just a few easy equations that, regardless of these approximations, carefully predict the generalization efficiency of the unique community.
Finite community $approx$ infinite-width community $=$ kernel regression
A serious vein of deep studying principle in the previous few years has studied neural networks of infinite width. One would possibly guess that including extra parameters to a community would solely make it tougher to grasp, however, by outcomes akin to central restrict theorems for neural nets, infinite-width nets truly take quite simple analytical types. Particularly, a large community educated by gradient descent to zero MSE loss will at all times study the operate
[hat{f}(x) = K(x, mathcal{D}) K(mathcal{D}, mathcal{D})^{-1} f(mathcal{D}),]
the place $mathcal{D}$ is the dataset, $f$ and $hat{f}$ are the goal and realized features respectively, and $Ok$ is the community’s “neural tangent kernel” (NTK). This can be a matrix equation: $Ok(x, mathcal{D})$ is a row vector, $Ok(mathcal{D}, mathcal{D})$ is the “kernel matrix,” and $f(mathcal{D})$ is a column vector. The NTK is totally different for each structure class however (no less than for huge nets) the identical each time you initialize. Due to this equation’s similarity to the conventional equation of linear regression, it goes by the title of “kernel regression.”
The sheer simplicity of this equation would possibly make one suspect that an infinite-width web is an absurd idealization with little resemblance to helpful networks, however experiments present that, as with the common central restrict theorem, infinite-width outcomes normally kick in ahead of you’d anticipate, at widths in solely the lots of. Trusting that this primary approximation will bear weight, our problem now could be to grasp kernel regression.
Approximating the generalization of kernel regression
In deriving the generalization of kernel regression, we get plenty of mileage from a easy trick: we take a look at the training drawback within the eigenbasis of the kernel. Considered as a linear operator, the kernel has eigenvalue/vector pairs $(lambda_i, phi_i)$ outlined by the situation that
[intlimits_{text{input space}} ! ! ! ! ! ! K(x, x’) phi_i(x’) d x’ = lambda_i phi_i(x).]
Intuitively talking, a kernel is a similarity operate, and we are able to interpet its high-eigenvalue eigenfunctions as mapping “related” factors to related values.
The centerpiece of our evaluation is a measure of generalization we name “learnability” which quantifies the alignment of $f$ and $hat{f}$. With just a few minor approximations, we derive the very simple outcome that the learnability of every eigenfunction is given by
[mathcal{L}(phi_i) = frac{lambda_i}{lambda_i + C},]
the place $C$ is a continuing. Increased learnability is best, and thus this method tells us that higher-eigenvalue eigenfunctions are simpler to study! Furthermore, we present that, as examples are added to the coaching set, $C$ steadily decreases from $infty$ to $0$, which implies that every mode’s $mathcal{L}(phi_i)$ steadily will increase from $0$ to $1$, with increased eigenmodes realized first. Fashions of this way have a robust inductive bias in the direction of studying increased eigenmodes.
We finally derive expressions for not simply learnability however for all first- and second-order statistics of the realized operate, together with recovering earlier expressions for MSE. We discover that these expressions are fairly correct for not simply kernel regression however finite networks, too, as illustrated in Fig 1.
No free lunch for neural networks
Along with approximations for generalization efficiency, we additionally show a easy actual outcome we name the “no-free-lunch theorem for kernel regression.” The classical no-free-lunch theorem for studying algorithms roughly states that, averaged over all attainable goal features $f$, any supervised studying algorithm has the identical anticipated generalization efficiency. This makes intuitive sense – in spite of everything, most features seem like white noise, with no discernable patterns – however it is usually not very helpful for the reason that set of “all features” is normally huge. Our extension, particular to kernel regression, basically states that
[begin{align}
sum_i mathcal{L}(phi_i) = text{[training set size]}.
finish{align}]
That’s, the sum of learnabilities throughout all kernel eigenfunctions equals the coaching set dimension. This actual outcome paints a vivid image of a kernel’s inductive bias: the kernel has precisely $textual content{[training set size]}$ models of learnability to parcel out to its eigenmodes – no extra, no much less – and thus eigenmodes are locked in a zero-sum competitors to be realized. As proven in Fig 2, we discover that this primary conservation regulation holds precisely for NTK regression and even roughly for finite networks. To our information, that is the primary outcome quantifying such a tradeoff in kernel regression or deep studying. It additionally applies to linear regression, a particular case of kernel regression.
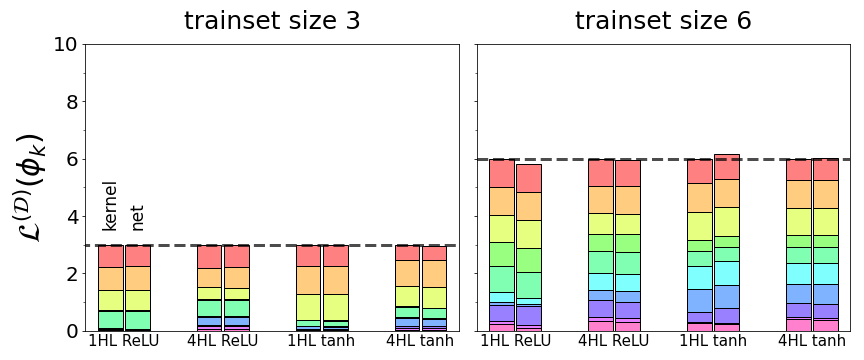
Fig 2. For 4 totally different community architectures (fully-connected $textual content{ReLU}$ and $textual content{tanh}$ nets with one or 4 hidden layers), complete learnability summed throughout all eigenfunctions is the same as the scale of the coaching set. Coloured elements present learnabilities of particular person eigenfunctions. For kernel regression with the community’s NTK (left bar in every pair), the sum is strictly the trainset dimension, whereas actual educated networks (proper bar in every pair) sum to roughly the trainset dimension.
Conclusion
These outcomes present that, regardless of neural nets’ infamous inscrutability, we are able to nonetheless hope to grasp when and why they work properly. As in different fields of science, if we take a step again, we are able to discover easy guidelines governing what naively seem like techniques of incomprehensible complexity. Extra work definitely stays to be carried out earlier than we really perceive deep studying – our principle solely applies to MSE loss, and the NTK’s eigensystem is but unknown in all however the easiest instances – however our outcomes up to now counsel now we have the makings of a bona fide principle of neural community generalization on our fingers.
This publish relies on the paper “Neural Tangent Kernel Eigenvalues Precisely Predict Generalization,” which is joint work with labmate Maddie Dickens and advisor Mike DeWeese. We offer code to breed all our outcomes. We’d be delighted to subject your questions or feedback.
[ad_2]