

{kind=link}
[ad_1]
Earlier than the introduction of the Transformer mannequin, using consideration for neural machine translation was being applied by RNN-based encoder-decoder architectures. The Transformer mannequin revolutionized the implementation of consideration by shelling out of recurrence and convolutions and, alternatively, relying solely on a self-attention mechanism.
We’ll first be specializing in the Transformer consideration mechanism on this tutorial, and subsequently reviewing the Transformer mannequin in a separate one.
On this tutorial, you’ll uncover the Transformer consideration mechanism for neural machine translation.
After finishing this tutorial, you’ll know:
- How the Transformer consideration differed from its predecessors.
- How the Transformer computes a scaled-dot product consideration.
- How the Transformer computes multi-head consideration.
Let’s get began.
The Transformer Consideration Mechanism
Photograph by Andreas Gücklhorn, some rights reserved.
Tutorial Overview
This tutorial is split into two components; they’re:
- Introduction to the Transformer Consideration
- The Transformer Consideration
- Scaled-Dot Product Consideration
- Multi-Head Consideration
Conditions
For this tutorial, we assume that you’re already accustomed to:
Introduction to the Transformer Consideration
We’ve, to date, familiarised ourselves with using an consideration mechanism at the side of an RNN-based encoder-decoder structure. We’ve seen that two of the preferred fashions that implement consideration on this method have been these proposed by Bahdanau et al. (2014) and Luong et al. (2015).
The Transformer structure revolutionized using consideration by shelling out of recurrence and convolutions, on which the formers had extensively relied.
… the Transformer is the primary transduction mannequin relying totally on self-attention to compute representations of its enter and output with out utilizing sequence-aligned RNNs or convolution.
– Consideration Is All You Want, 2017.
Of their paper, Consideration Is All You Want, Vaswani et al. (2017) clarify that the Transformer mannequin, alternatively, depends solely on using self-attention, the place the illustration of a sequence (or sentence) is computed by relating completely different phrases in the identical sequence.
Self-attention, generally known as intra-attention is an consideration mechanism relating completely different positions of a single sequence so as to compute a illustration of the sequence.
– Consideration Is All You Want, 2017.
The Transformer Consideration
The principle parts in use by the Transformer consideration are the next:
- $mathbf{q}$ and $mathbf{okay}$ denoting vectors of dimension, $d_k$, containing the queries and keys, respectively.
- $mathbf{v}$ denoting a vector of dimension, $d_v$, containing the values.
- $mathbf{Q}$, $mathbf{Ok}$ and $mathbf{V}$ denoting matrices packing collectively units of queries, keys and values, respectively.
- $mathbf{W}^Q$, $mathbf{W}^Ok$ and $mathbf{W}^V$ denoting projection matrices which are utilized in producing completely different subspace representations of the question, key and worth matrices.
- $mathbf{W}^O$ denoting a projection matrix for the multi-head output.
In essence, the eye perform could be thought of as a mapping between a question and a set of key-value pairs, to an output.
The output is computed as a weighted sum of the values, the place the burden assigned to every worth is computed by a compatibility perform of the question with the corresponding key.
– Consideration Is All You Want, 2017.
Vaswani et al. suggest a scaled dot-product consideration, after which construct on it to suggest multi-head consideration. Inside the context of neural machine translation, the question, keys and values which are used as inputs to the these consideration mechanisms, are completely different projections of the identical enter sentence.
Intuitively, due to this fact, the proposed consideration mechanisms implement self-attention by capturing the relationships between the completely different components (on this case, the phrases) of the identical sentence.
Scaled Dot-Product Consideration
The Transformer implements a scaled dot-product consideration, which follows the process of the normal consideration mechanism that we had beforehand seen.
Because the identify suggests, the scaled dot-product consideration first computes a dot product for every question, $mathbf{q}$, with the entire keys, $mathbf{okay}$. It, subsequently, divides every end result by $sqrt{d_k}$ and proceeds to use a softmax perform. In doing so, it obtains the weights which are used to scale the values, $mathbf{v}$.
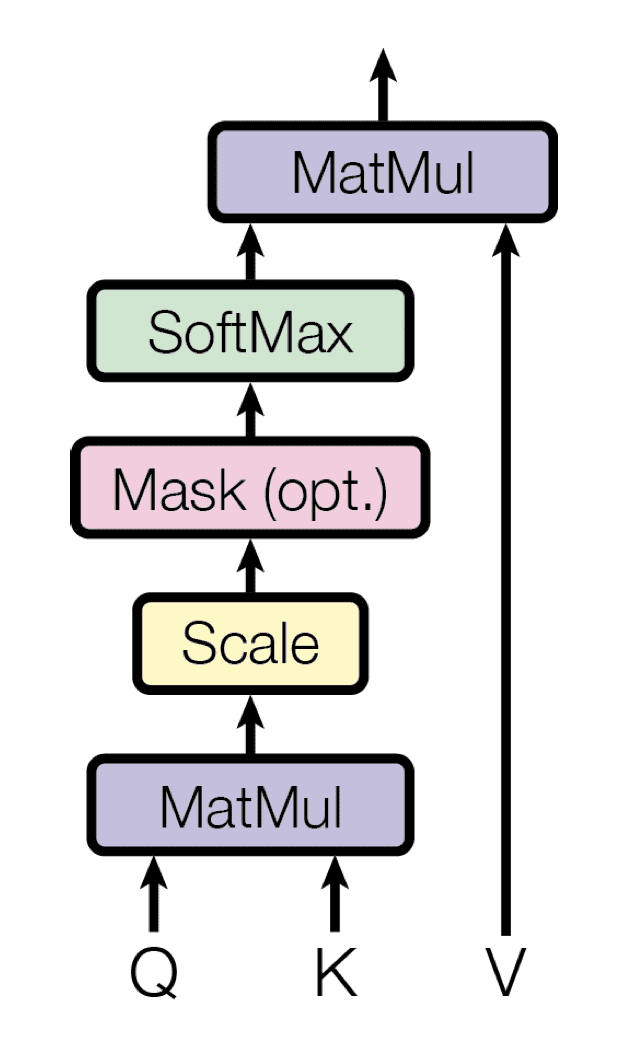
Scaled Dot-Product Consideration
Taken from “Consideration Is All You Want“
In observe, the computations carried out by the scaled dot-product consideration could be effectively utilized on your complete set of queries concurrently. So as to take action, the matrices, $mathbf{Q}$, $mathbf{Ok}$ and $mathbf{V}$, are equipped as inputs to the eye perform:
$$textual content{consideration}(mathbf{Q}, mathbf{Ok}, mathbf{V}) = textual content{softmax} left( frac{QK^T}{sqrt{d_k}} proper) V$$
Vaswani et al. clarify that their scaled dot-product consideration is an identical to the multiplicative consideration of Luong et al. (2015), apart from the added scaling issue of $tfrac{1}{sqrt{d_k}}$.
This scaling issue was launched to counteract the impact of getting the dot merchandise develop massive in magnitude for big values of $d_k$, the place the appliance of the softmax perform would then return extraordinarily small gradients that might result in the notorious vanishing gradients drawback. The scaling issue, due to this fact, serves to tug the outcomes generated by the dot product multiplication down, therefore stopping this drawback.
Vaswani et al. additional clarify that their alternative of choosing multiplicative consideration as a substitute of the additive consideration of Bahdanau et al. (2014), was based mostly on the computational effectivity related to the previous.
… dot-product consideration is far sooner and extra space-efficient in observe, since it may be applied utilizing extremely optimized matrix multiplication code.
– Consideration Is All You Want, 2017.
The step-by-step process for computing the scaled-dot product consideration is, due to this fact, the next:
- Compute the alignment scores by multiplying the set of queries packed in matrix, $mathbf{Q}$,with the keys in matrix, $mathbf{Ok}$. If matrix, $mathbf{Q}$, is of dimension $m occasions d_k$ and matrix, $mathbf{Ok}$, is of dimension, $n occasions d_k$, then the ensuing matrix will likely be of dimension $m occasions n$:
$$
mathbf{QK}^T =
start{bmatrix}
e_{11} & e_{12} & dots & e_{1n}
e_{21} & e_{22} & dots & e_{2n}
vdots & vdots & ddots & vdots
e_{m1} & e_{m2} & dots & e_{mn}
finish{bmatrix}
$$
- Scale every of the alignment scores by $tfrac{1}{sqrt{d_k}}$:
$$
frac{mathbf{QK}^T}{sqrt{d_k}} =
start{bmatrix}
tfrac{e_{11}}{sqrt{d_k}} & tfrac{e_{12}}{sqrt{d_k}} & dots & tfrac{e_{1n}}{sqrt{d_k}}
tfrac{e_{21}}{sqrt{d_k}} & tfrac{e_{22}}{sqrt{d_k}} & dots & tfrac{e_{2n}}{sqrt{d_k}}
vdots & vdots & ddots & vdots
tfrac{e_{m1}}{sqrt{d_k}} & tfrac{e_{m2}}{sqrt{d_k}} & dots & tfrac{e_{mn}}{sqrt{d_k}}
finish{bmatrix}
$$
- And comply with the scaling course of by making use of a softmax operation so as to get hold of a set of weights:
$$
textual content{softmax} left( frac{mathbf{QK}^T}{sqrt{d_k}} proper) =
start{bmatrix}
textual content{softmax} left( tfrac{e_{11}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{12}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{1n}}{sqrt{d_k}} proper)
textual content{softmax} left( tfrac{e_{21}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{22}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{2n}}{sqrt{d_k}} proper)
vdots & vdots & ddots & vdots
textual content{softmax} left( tfrac{e_{m1}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{m2}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{mn}}{sqrt{d_k}} proper)
finish{bmatrix}
$$
- Lastly, apply the ensuing weights to the values in matrix, $mathbf{V}$, of dimension, $n occasions d_v$:
$$
start{aligned}
& textual content{softmax} left( frac{mathbf{QK}^T}{sqrt{d_k}} proper) cdot mathbf{V}
=&
start{bmatrix}
textual content{softmax} left( tfrac{e_{11}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{12}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{1n}}{sqrt{d_k}} proper)
textual content{softmax} left( tfrac{e_{21}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{22}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{2n}}{sqrt{d_k}} proper)
vdots & vdots & ddots & vdots
textual content{softmax} left( tfrac{e_{m1}}{sqrt{d_k}} proper) & textual content{softmax} left( tfrac{e_{m2}}{sqrt{d_k}} proper) & dots & textual content{softmax} left( tfrac{e_{mn}}{sqrt{d_k}} proper)
finish{bmatrix}
cdot
start{bmatrix}
v_{11} & v_{12} & dots & v_{1d_v}
v_{21} & v_{22} & dots & v_{2d_v}
vdots & vdots & ddots & vdots
v_{n1} & v_{n2} & dots & v_{nd_v}
finish{bmatrix}
finish{aligned}
$$
Multi-Head Consideration
Constructing on their single consideration perform that takes matrices, $mathbf{Q}$, $mathbf{Ok}$, and $mathbf{V}$, as enter, as we’ve got simply reviewed, Vaswani et al. additionally suggest a multi-head consideration mechanism.
Their multi-head consideration mechanism linearly initiatives the queries, keys and values $h$ occasions, every time utilizing a special discovered projection. The only consideration mechanism is then utilized to every of those $h$ projections in parallel, to provide $h$ outputs, which in flip are concatenated and projected once more to provide a last end result.

Multi-Head Consideration
Taken from “Consideration Is All You Want“
The thought behind multi-head consideration is to permit the eye perform to extract info from completely different illustration subspaces, which might, in any other case, not be attainable with a single consideration head.
The multi-head consideration perform could be represented as follows:
$$textual content{multihead}(mathbf{Q}, mathbf{Ok}, mathbf{V}) = textual content{concat}(textual content{head}_1, dots, textual content{head}_h) mathbf{W}^O$$
Right here, every $textual content{head}_i$, $i = 1, dots, h$, implements a single consideration perform characterised by its personal discovered projection matrices:
$$textual content{head}_i = textual content{consideration}(mathbf{QW}^Q_i, mathbf{KW}^K_i, mathbf{VW}^V_i)$$
The step-by-step process for computing multi-head consideration is, due to this fact, the next:
- Compute the linearly projected variations of the queries, keys and values by means of a multiplication with the respective weight matrices, $mathbf{W}^Q_i$, $mathbf{W}^K_i$ and $mathbf{W}^V_i$, one for every $textual content{head}_i$.
- Apply the one consideration perform for every head by (1) multiplying the queries and keys matrices, (2) making use of the scaling and softmax operations, and (3) weighting the values matrix, to generate an output for every head.
- Concatenate the outputs of the heads, $textual content{head}_i$, $i = 1, dots, h$.
- Apply a linear projection to the concatenated output by means of a multiplication with the burden matrix, $mathbf{W}^O$, to generate the ultimate end result.
Additional Studying
This part offers extra sources on the subject in case you are seeking to go deeper.
Books
Papers
Abstract
On this tutorial, you found the Transformer consideration mechanism for neural machine translation.
Particularly, you discovered:
- How the Transformer consideration differed from its predecessors.
- How the Transformer computes a scaled-dot product consideration.
- How the Transformer computes multi-head consideration.
Do you might have any questions?
Ask your questions within the feedback beneath and I’ll do my greatest to reply.
[ad_2]