
{kind=link}
[ad_1]
Machine studying (ML) fashions have gotten more and more beneficial for improved efficiency throughout quite a lot of shopper merchandise, from suggestions to computerized picture classification. Nonetheless, regardless of aggregating giant quantities of knowledge, in principle it’s attainable for fashions to encode traits of particular person entries from the coaching set. For instance, experiments in managed settings have proven that language fashions skilled utilizing electronic mail datasets could generally encode delicate info included within the coaching information and will have the potential to reveal the presence of a selected consumer’s information within the coaching set. As such, you will need to stop the encoding of such traits from particular person coaching entries. To those ends, researchers are more and more using federated studying approaches.
Differential privateness (DP) supplies a rigorous mathematical framework that enables researchers to quantify and perceive the privateness ensures of a system or an algorithm. Throughout the DP framework, privateness ensures of a system are normally characterised by a optimistic parameter ε, referred to as the privateness loss certain, with smaller ε corresponding to higher privateness. One normally trains a mannequin with DP ensures utilizing DP-SGD, a specialised coaching algorithm that gives DP ensures for the skilled mannequin.
Nonetheless coaching with DP-SGD sometimes has two main drawbacks. First, most present implementations of DP-SGD are inefficient and gradual, which makes it laborious to make use of on giant datasets. Second, DP-SGD coaching usually considerably impacts utility (akin to mannequin accuracy) to the purpose that fashions skilled with DP-SGD could change into unusable in apply. In consequence most DP analysis papers consider DP algorithms on very small datasets (MNIST, CIFAR-10, or UCI) and don’t even attempt to carry out analysis of bigger datasets, akin to ImageNet.
In “Towards Coaching at ImageNet Scale with Differential Privateness”, we share preliminary outcomes from our ongoing effort to coach a big picture classification mannequin on ImageNet utilizing DP whereas sustaining excessive accuracy and minimizing computational price. We present that the mix of varied coaching strategies, akin to cautious selection of the mannequin and hyperparameters, giant batch coaching, and switch studying from different datasets, can considerably enhance accuracy of an ImageNet mannequin skilled with DP. To substantiate these discoveries and encourage follow-up analysis, we’re additionally releasing the related supply code.
Testing Differential Privateness on ImageNet
We select ImageNet classification as an illustration of the practicality and efficacy of DP as a result of: (1) it’s an bold activity for DP, for which no prior work exhibits enough progress; and (2) it’s a public dataset on which different researchers can function, so it represents a chance to collectively enhance the utility of real-life DP coaching. Classification on ImageNet is difficult for DP as a result of it requires giant networks with many parameters. This interprets into a big quantity of noise added into the computation, as a result of the noise added scales with the scale of the mannequin.
Scaling Differential Privateness with JAX
Exploring a number of architectures and coaching configurations to analysis what works for DP could be debilitatingly gradual. To streamline our efforts, we used JAX, a high-performance computational library based mostly on XLA that may do environment friendly auto-vectorization and just-in-time compilation of the mathematical computations. Utilizing these JAX options was beforehand really useful as a great way to hurry up DP-SGD within the context of smaller datasets akin to CIFAR-10.
We created our personal implementation of DP-SGD on JAX and benchmarked it towards the massive ImageNet dataset (the code is included in our launch). The implementation in JAX was comparatively easy and resulted in noticeable efficiency beneficial properties merely due to utilizing the XLA compiler. In comparison with different implementations of DP-SGD, akin to that in Tensorflow Privateness, the JAX implementation is persistently a number of occasions quicker. It’s sometimes even quicker in comparison with the custom-built and optimized PyTorch Opacus.
Every step of our DP-SGD implementation takes roughly two forward-backward passes via the community. Whereas that is slower than non-private coaching, which requires solely a single forward-backward cross, it’s nonetheless the best identified strategy to coach with the per-example gradients obligatory for DP-SGD. The graph beneath exhibits coaching runtimes for 2 fashions on ImageNet with DP-SGD vs. non-private SGD, every on JAX. Total, we discover DP-SGD on JAX sufficiently quick to run giant experiments simply by barely decreasing the variety of coaching runs used to seek out optimum hyperparameters in comparison with non-private coaching. That is considerably higher than alternate options, akin to Tensorflow Privateness, which we discovered to be ~5x–10x slower on our CIFAR10 and MNIST benchmarks.
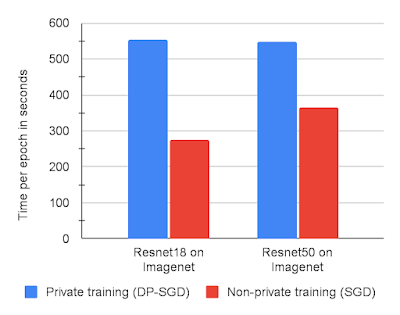 |
| Time in seconds per coaching epoch on ImageNet utilizing a Resnet18 or Resnet50 structure with 8 V100 GPUs. |
Combining Methods for Improved Accuracy
It’s attainable that future coaching algorithms could enhance DP’s privacy-utility tradeoff. Nonetheless, with present algorithms, akin to DP-SGD, our expertise factors to an engineering “bag-of-tricks” strategy to make DP extra sensible on difficult duties like ImageNet.
As a result of we are able to practice fashions quicker with JAX, we are able to iterate rapidly and discover a number of configurations to seek out what works nicely for DP. We report the next mixture of strategies as helpful to attain non-trivial accuracy and privateness on ImageNet:
- Full-batch coaching
Theoretically, it’s identified that bigger minibatch sizes enhance the utility of DP-SGD, with full-batch coaching (i.e., the place a full dataset is one batch) giving the most effective utility [1, 2], and empirical outcomes are rising to help this principle. Certainly, our experiments exhibit that rising the batch dimension together with the variety of coaching epochs results in a lower in ε whereas nonetheless sustaining accuracy. Nonetheless, coaching with extraordinarily giant batches is non-trivial because the batch can not match into GPU/TPU reminiscence. So, we employed digital large-batch coaching by accumulating gradients for a number of steps earlier than updating the weights as a substitute of making use of gradient updates on every coaching step.
Batch dimension 1024 4 × 1024 16 × 1024 64 × 1024 Variety of epochs 10 40 160 640 Accuracy 56% 57.5% 57.9% 57.2% Privateness loss certain ε 9.8 × 108 6.1 × 107 3.5 × 106 6.7 × 104 - Switch studying from public information
Pre-training on public information adopted by DP fine-tuning on non-public information has beforehand been proven to enhance accuracy on different benchmarks [3, 4]. A query that is still is what public information to make use of for a given activity to optimize switch studying. On this work we simulate a non-public/public information cut up through the use of ImageNet as “non-public” information and utilizing Places365, one other picture classification dataset, as a proxy for “public” information. We pre-trained our fashions on Places365 earlier than fine-tuning them with DP-SGD on ImageNet. Places365 solely has pictures of landscapes and buildings, not of animals as ImageNet, so it’s fairly completely different, making it a very good candidate to exhibit the flexibility of the mannequin to switch to a unique however associated area.
We discovered that switch studying from Places365 gave us 47.5% accuracy on ImageNet with an affordable stage of privateness (ε = 10). That is low in comparison with the 70% accuracy of the same non-private mannequin, however in comparison with naïve DP coaching on ImageNet, which yields both very low accuracy (2 – 5%) or no privateness (ε=109), that is fairly good.
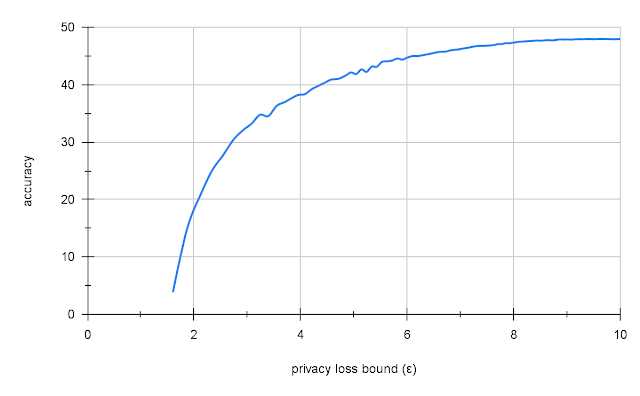 |
| Privateness-accuracy tradeoff for Resnet-18 on ImageNet utilizing large-batch coaching with switch studying from Places365. |
Subsequent Steps
We hope these early outcomes and supply code present an impetus for different researchers to work on bettering DP for bold duties akin to ImageNet as a proxy for difficult production-scale duties. With the a lot quicker DP-SGD on JAX, we urge DP and ML researchers to discover various coaching regimes, mannequin architectures, and algorithms to make DP extra sensible. To proceed advancing the state of the sphere, we suggest researchers begin with a baseline that comes with full-batch coaching plus switch studying.
Acknowledgments
This work was carried out with the help of the Google Visiting Researcher Program whereas Prof. Geambasu, an Affiliate Professor with Columbia College, was on sabbatical with Google Analysis. This work acquired substantial contributions from Steve Chien, Shuang Tune, Andreas Terzis and Abhradeep Guha Thakurta.
[ad_2]