

{kind=link}
[ad_1]

An instance of our methodology deployed on a Clearpath Jackal floor robotic (left) exploring a suburban setting to discover a visible goal (inset). (Proper) Selfish observations of the robotic.
Think about you’re in an unfamiliar neighborhood with no home numbers and I provide you with a photograph that I took a number of days in the past of my home, which isn’t too far-off. Should you tried to search out my home, you would possibly observe the streets and go across the block in search of it. You would possibly take a number of improper turns at first, however finally you’ll find my home. Within the course of, you’ll find yourself with a psychological map of my neighborhood. The subsequent time you’re visiting, you’ll seemingly be capable of navigate to my home straight away, with out taking any improper turns.
Such exploration and navigation habits is simple for people. What would it not take for a robotic studying algorithm to allow this type of intuitive navigation functionality? To construct a robotic able to exploring and navigating like this, we have to study from various prior datasets in the actual world. Whereas it’s potential to gather a considerable amount of information from demonstrations, and even with randomized exploration, studying significant exploration and navigation habits from this information might be difficult – the robotic must generalize to unseen neighborhoods, acknowledge visible and dynamical similarities throughout scenes, and study a illustration of visible observations that’s sturdy to distractors like climate situations and obstacles. Since such components might be onerous to mannequin and switch from simulated environments, we sort out these issues by educating the robotic to discover utilizing solely real-world information.
Formally, we studied the issue of goal-directed exploration for visible navigation in novel environments. A robotic is tasked with navigating to a purpose location (G), specified by a picture (o_G) taken at (G). Our methodology makes use of an offline dataset of trajectories, over 40 hours of interactions within the real-world, to study navigational affordances and builds a compressed illustration of perceptual inputs. We deploy our methodology on a cellular robotic system in industrial and leisure out of doors areas across the metropolis of Berkeley. RECON can uncover a brand new purpose in a beforehand unexplored setting in beneath 10 minutes, and within the course of construct a “psychological map” of that setting that enables it to then attain targets once more in simply 20 seconds. Moreover, we make this real-world offline dataset publicly obtainable to be used in future analysis.
RECON, or Rapid Exploration Controllers for Outcome-driven Navigation, explores new environments by “imagining” potential purpose pictures and trying to succeed in them. This exploration permits RECON to incrementally collect details about the brand new setting.
Our methodology consists of two elements that allow it to discover new environments. The primary element is a discovered illustration of targets. This illustration ignores task-irrelevant distractors, permitting the agent to rapidly adapt to novel settings. The second element is a topological graph. Our methodology learns each elements utilizing datasets or real-world robotic interactions gathered in prior work. Leveraging such giant datasets permits our methodology to generalize to new environments and scale past the unique dataset.
Studying to Signify Objectives
A helpful technique to study advanced goal-reaching habits in an unsupervised method is for an agent to set its personal targets, based mostly on its capabilities, and try to succeed in them. In actual fact, people are very proficient at setting summary targets for themselves in an effort to study various abilities. Latest progress in reinforcement studying and robotics has additionally proven that educating brokers to set its personal targets by “imagining” them can lead to studying of spectacular unsupervised goal-reaching abilities. To have the ability to “think about”, or pattern, such targets, we have to construct a previous distribution over the targets seen throughout coaching.
For our case, the place targets are represented by high-dimensional pictures, how ought to we pattern targets for exploration? As a substitute of explicitly sampling purpose pictures, we as a substitute have the agent study a compact illustration of latent targets, permitting us to carry out exploration by sampling new latent purpose representations, quite than by sampling pictures. This illustration of targets is discovered from context-goal pairs beforehand seen by the robotic. We use a variational data bottleneck to study these representations as a result of it supplies two essential properties. First, it learns representations that throw away irrelevant data, resembling lighting and pixel noise. Second, the variational data bottleneck packs the representations collectively in order that they seem like a selected prior distribution. That is helpful as a result of we will then pattern imaginary representations by sampling from this prior distribution.
The structure for studying a previous distribution for these representations is proven under. Because the encoder and decoder are conditioned on the context, the illustration (Z_t^g) solely encodes details about relative location of the purpose from the context – this permits the mannequin to characterize possible targets. If, as a substitute, we had a typical VAE (wherein the enter pictures are autoencoded), the samples from the prior over these representations wouldn’t essentially characterize targets which might be reachable from the present state. This distinction is essential when exploring new environments, the place most states from the coaching environments should not legitimate targets.
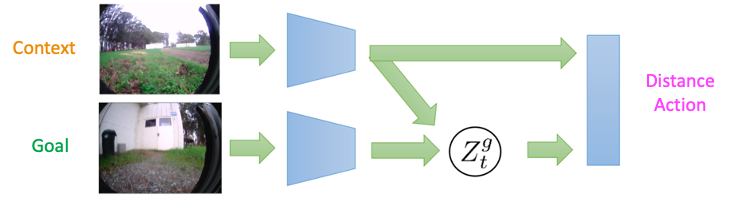
The structure for studying a previous over targets in RECON. The context-conditioned embedding learns to characterize possible targets.
To grasp the significance of studying this illustration, we run a easy experiment the place the robotic is requested to discover in an undirected method ranging from the yellow circle within the determine under. We discover that sampling representations from the discovered prior enormously accelerates the variety of exploration trajectories and permits a wider space to be explored. Within the absence of a previous over beforehand seen targets, utilizing random actions to discover the setting might be fairly inefficient. Sampling from the prior distribution and trying to succeed in these “imagined” targets permits RECON to discover the setting effectively.
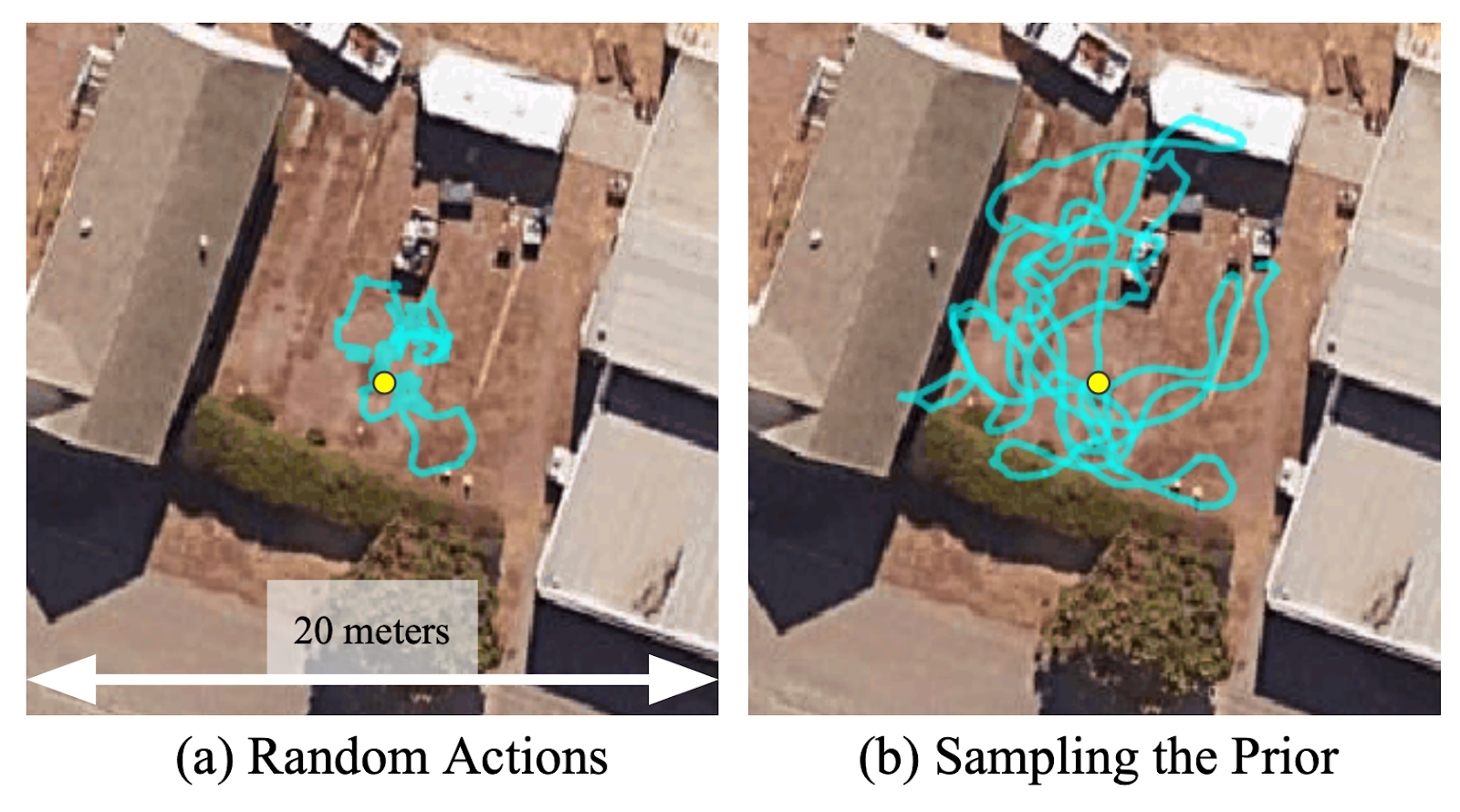
Sampling from a discovered prior permits the robotic to discover 5 instances sooner than utilizing random actions.
Aim-Directed Exploration with a Topological Reminiscence
We mix this purpose sampling scheme with a topological reminiscence to incrementally construct a “psychological map” of the brand new setting. This map supplies an estimate of the exploration frontier in addition to steering for subsequent exploration. In a brand new setting, RECON encourages the robotic to discover on the frontier of the map – whereas the robotic will not be on the frontier, RECON directs it to navigate to a beforehand seen subgoal on the frontier of the map.
On the frontier, RECON makes use of the discovered purpose illustration to study a previous over targets it could reliably navigate to and are thus, possible to succeed in. RECON makes use of this purpose illustration to pattern, or “think about”, a possible purpose that helps it discover the setting. This successfully signifies that, when positioned in a brand new setting, if RECON doesn’t know the place the goal is, it “imagines” an appropriate subgoal that it could drive in the direction of to discover and collects data, till it believes it could attain the goal purpose picture. This enables RECON to “search” for the purpose in an unknown setting, all of the whereas build up its psychological map. Observe that the target of the topological graph is to construct a compact map of the setting and encourage the robotic to succeed in the frontier; it doesn’t inform purpose sampling as soon as the robotic is on the frontier.
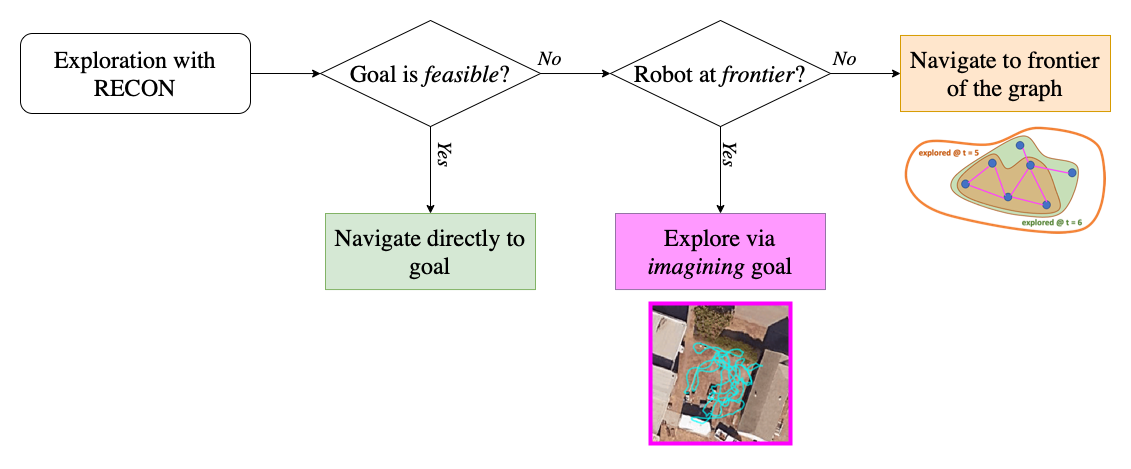
Illustration of the exploration algorithm of RECON.
Studying from Numerous Actual-world Knowledge
We practice these fashions in RECON solely utilizing offline information collected in a various vary of out of doors environments. Curiously, we have been capable of practice this mannequin utilizing information collected for 2 unbiased tasks within the fall of 2019 and spring of 2020, and have been profitable in deploying the mannequin to discover novel environments and navigate to targets throughout late 2020 and the spring of 2021. This offline dataset of trajectories consists of over 40 hours of knowledge, together with off-road navigation, driving by way of parks in Berkeley and Oakland, parking tons, sidewalks and extra, and is a wonderful instance of noisy real-world information with visible distractors like lighting, seasons (rain, twilight and many others.), dynamic obstacles and many others. The dataset consists of a mix of teleoperated trajectories (2-3 hours) and open-loop security controllers programmed to gather random information in a self-supervised method. This dataset presents an thrilling benchmark for robotic studying in real-world environments because of the challenges posed by offline studying of management, illustration studying from high-dimensional visible observations, generalization to out-of-distribution environments and test-time adaptation.
We’re releasing this dataset publicly to assist future analysis in machine studying from real-world interplay datasets, try the dataset web page for extra data.

We practice from various offline information (high) and check in new environments (backside).
RECON in Motion
Placing these elements collectively, let’s see how RECON performs when deployed in a park close to Berkeley. Observe that the robotic has by no means seen pictures from this park earlier than. We positioned the robotic in a nook of the park and supplied a goal picture of a white cabin door. Within the animation under, we see RECON exploring and efficiently discovering the specified purpose. “Run 1” corresponds to the exploration course of in a novel setting, guided by a user-specified goal picture on the left. After it finds the purpose, RECON makes use of the psychological map to distill its expertise within the setting to search out the shortest path for subsequent traversals. In “Run 2”, RECON follows this path to navigate on to the purpose with out trying round.
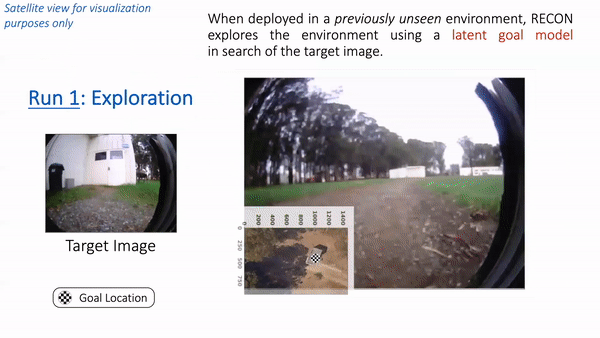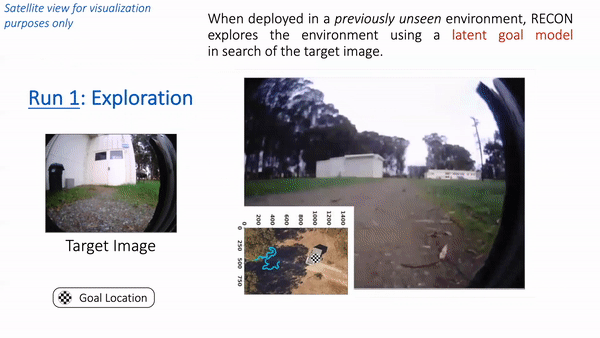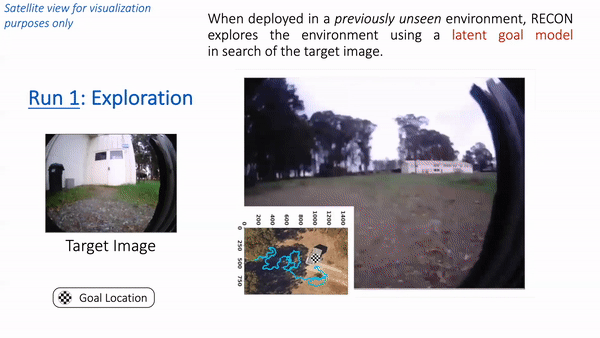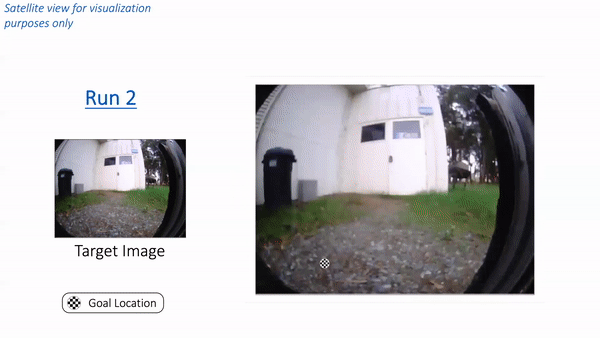
In “Run 1”, RECON explores a brand new setting and builds a topological psychological map. In “Run 2”, it makes use of this psychological map to rapidly navigate to a user-specified purpose within the setting.
An illustration of this two-step course of from an overhead view is present under, displaying the paths taken by the robotic in subsequent traversals of the setting:
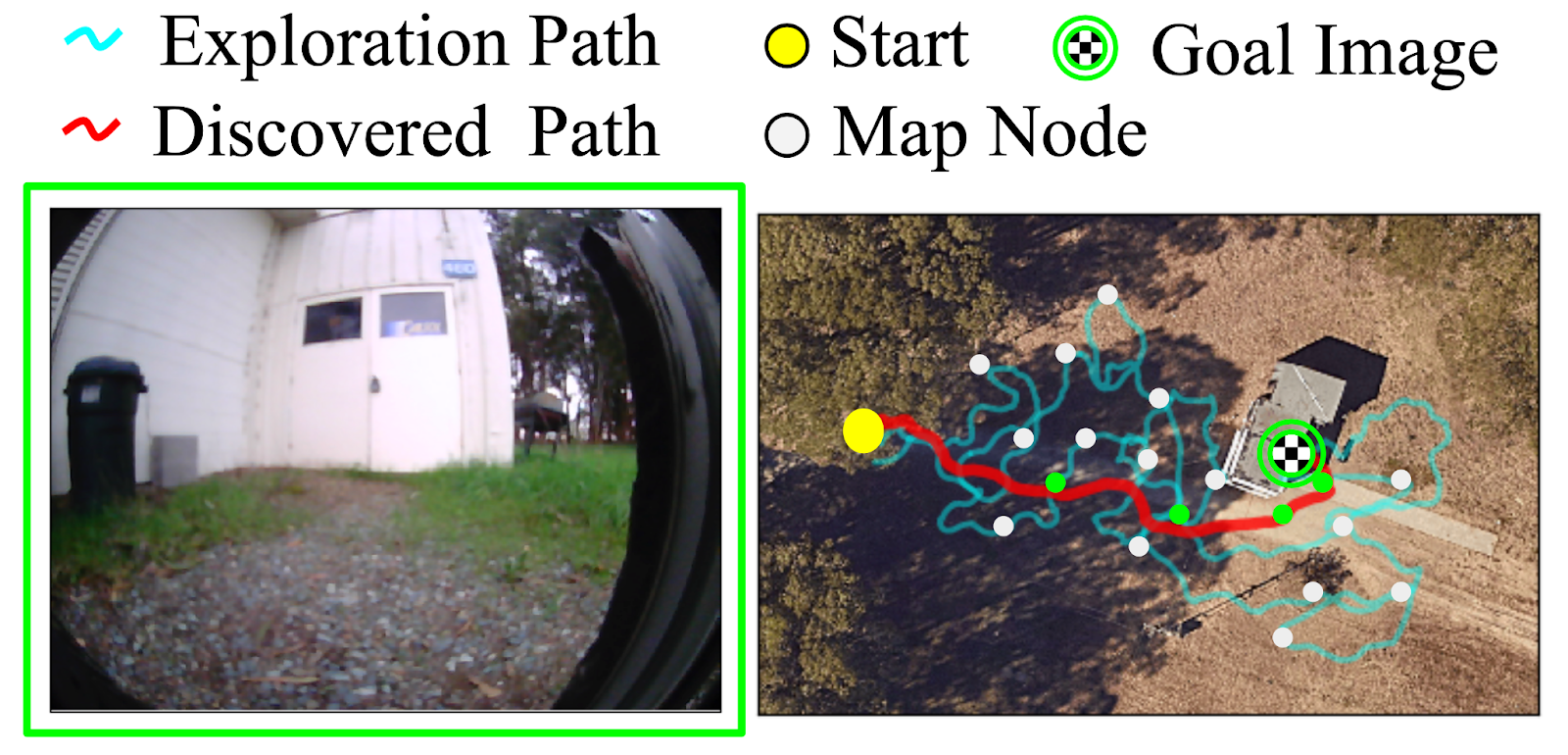
(Left) The purpose specified by the person. (Proper) The trail taken by the robotic when exploring for the primary time (proven in cyan) to construct a psychological map with nodes (proven in white), and the trail it takes when revisiting the identical purpose utilizing the psychological map (proven in purple).
To guage the efficiency of RECON in novel environments, research its habits beneath a variety of perturbations and perceive the contributions of its elements, we run intensive real-world experiments within the hills of Berkeley and Richmond, which have a various terrain and all kinds of testing environments.
We examine RECON to 5 baselines – RND, InfoBot, Lively Neural SLAM, ViNG and Episodic Curiosity – every skilled on the identical offline trajectory dataset as our methodology, and fine-tuned within the goal setting with on-line interplay. Observe that this information is collected from previous environments and accommodates no information from the goal setting. The determine under reveals the trajectories taken by the completely different strategies for one such setting.
We discover that solely RECON (and a variant) is ready to efficiently uncover the purpose in over half-hour of exploration, whereas all different baselines end in collision (see determine for an overhead visualization). We visualize profitable trajectories found by RECON in 4 different environments under.
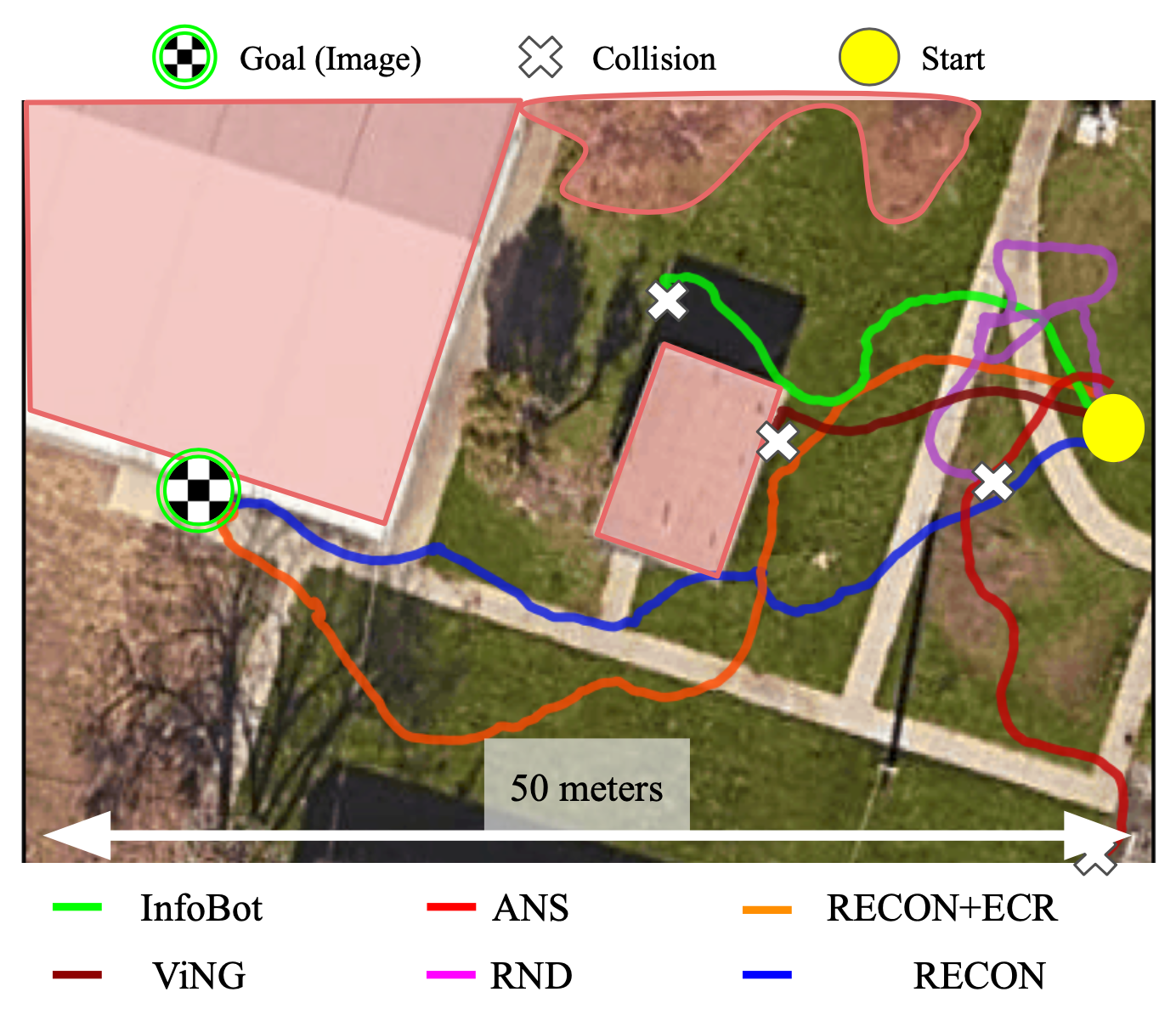
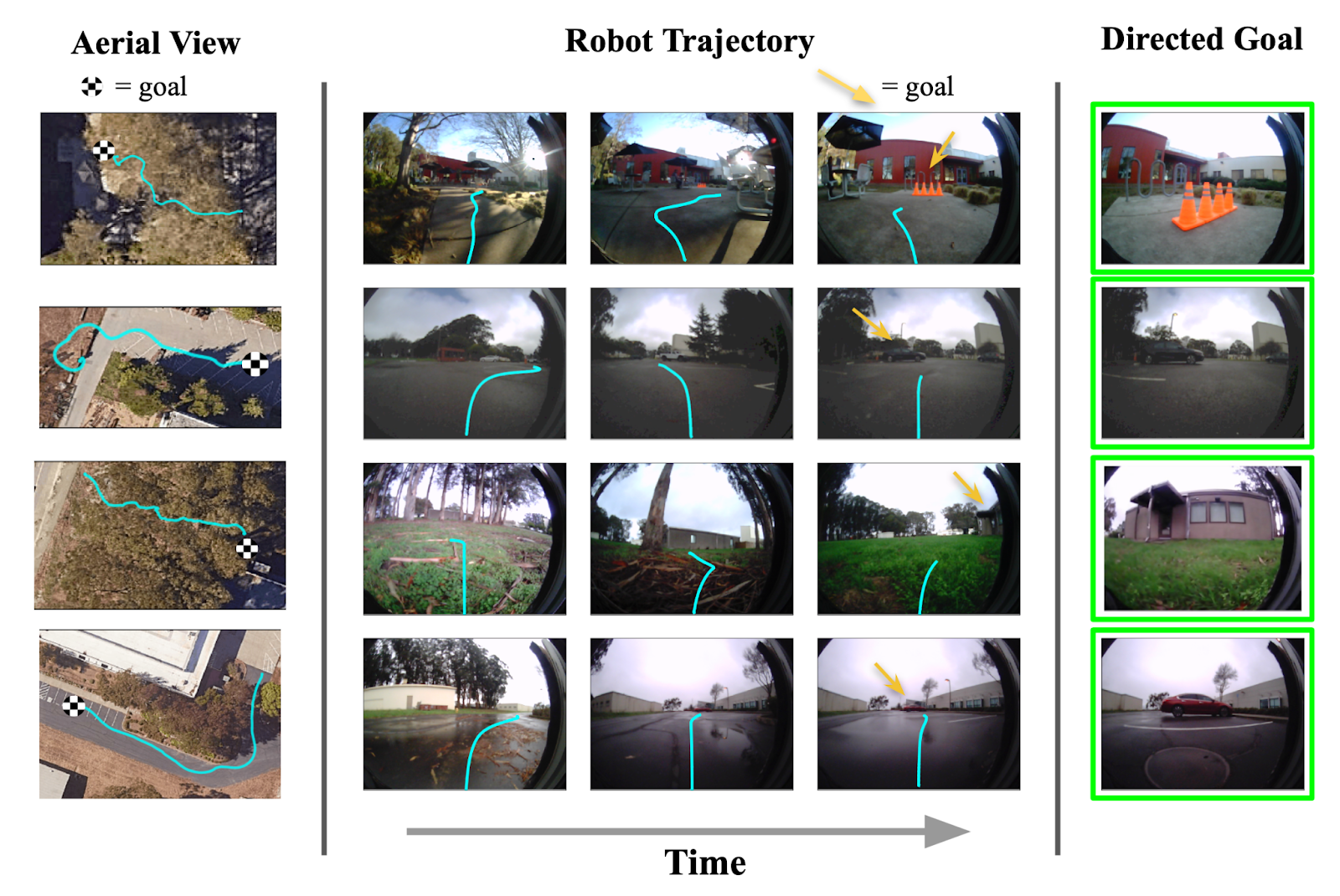
(Left) When evaluating to different baselines, solely RECON is ready to efficiently discover the purpose. (Proper) Trajectories to targets in 4 different environments found by RECON.
Quantitatively, we observe that our methodology finds targets over 50% sooner than the perfect prior methodology; after discovering the purpose and constructing a topological map of the setting, it could navigate to targets in that setting over 25% sooner than the perfect various methodology.
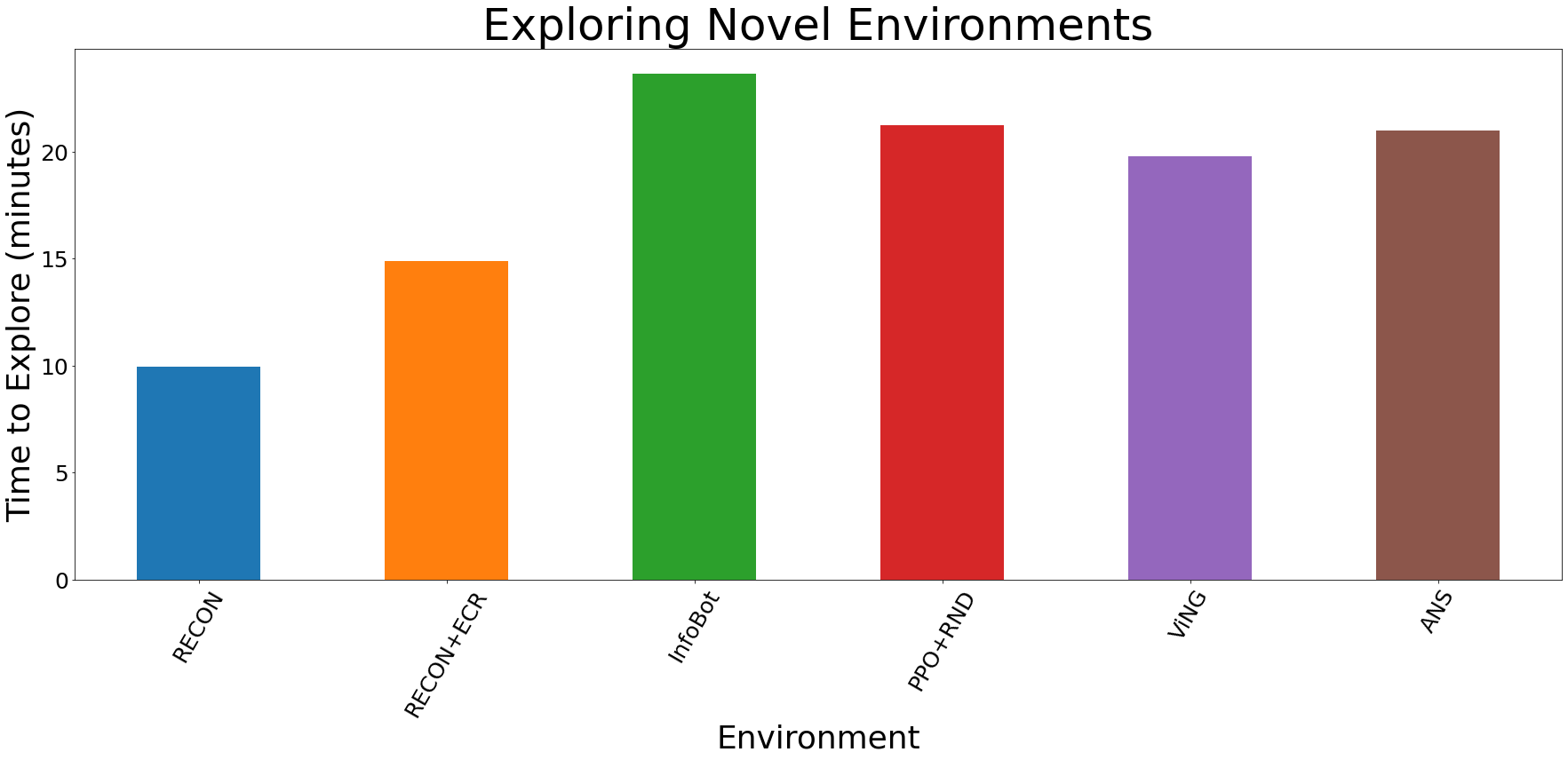
Quantitative ends in novel environments. RECON outperforms all baselines by over 50%.
Exploring Non-Stationary Environments
One of many essential challenges in designing real-world robotic navigation programs is dealing with variations between coaching situations and testing situations. Sometimes, programs are developed in well-controlled environments, however are deployed in much less structured environments. Additional, the environments the place robots are deployed typically change over time, so tuning a system to carry out effectively on a cloudy day would possibly degrade efficiency on a sunny day. RECON makes use of specific illustration studying in makes an attempt to deal with this type of non-stationary dynamics.
Our ultimate experiment examined how adjustments within the setting affected the efficiency of RECON. We first had RECON discover a brand new “junkyard” to study to succeed in a blue dumpster. Then, with none extra supervision or exploration, we evaluated the discovered coverage when offered with beforehand unseen obstacles (trash cans, visitors cones, a automotive) and climate situations (sunny, overcast, twilight). As proven under, RECON is ready to efficiently navigate to the purpose in these situations, displaying that the discovered representations are invariant to visible distractors that don’t have an effect on the robotic’s selections to succeed in the purpose.


First-person movies of RECON efficiently navigating to a “blue dumpster” within the presence of novel obstacles (above) and ranging climate situations (under).
The issue setup studied on this paper – utilizing previous expertise to speed up studying in a brand new setting – is reflective of a number of real-world robotics situations. RECON supplies a strong approach to clear up this downside through the use of a mixture of purpose sampling and topological reminiscence.
A cellular robotic able to reliably exploring and visually observing real-world environments is usually a useful gizmo for all kinds of helpful functions resembling search and rescue, inspecting giant places of work or warehouses, discovering leaks in oil pipelines or making rounds at a hospital, delivering mail in suburban communities. We demonstrated simplified variations of such functions in an earlier challenge, the place the robotic has prior expertise within the deployment setting; RECON allows these outcomes to scale past the coaching set of environments and ends in a really open-world studying system that may adapt to novel environments on deployment.
We’re additionally releasing the aforementioned offline trajectory dataset, with over XX hours of real-world interplay of a cellular floor robotic in a wide range of out of doors environments. We hope that this dataset can assist future analysis in machine studying utilizing real-world information for visible navigation functions. The dataset can be a wealthy supply of sequential information from a mess of sensors and can be utilized to check sequence prediction fashions together with, however not restricted to, video prediction, LiDAR, GPS and many others. Extra details about the dataset might be discovered within the full-text article.
This weblog publish is predicated on our paper Speedy Exploration for Open-World Navigation with Latent Aim Fashions, which shall be offered as an Oral Speak on the fifth Annual Convention on Robotic Studying in London, UK on November 8-11, 2021. You could find extra details about our outcomes and the dataset launch on the challenge web page.
Huge due to Sergey Levine and Benjamin Eysenbach for useful feedback on an earlier draft of this text.
[ad_2]