

{kind=link}
[ad_1]
We’ve got already familiarized ourselves with the idea of self-attention as applied by the Transformer consideration mechanism for neural machine translation. We’ll now be shifting our concentrate on the main points of the Transformer structure itself, to find how self-attention may be applied with out counting on using recurrence and convolutions.
On this tutorial, you’ll uncover the community structure of the Transformer mannequin.
After finishing this tutorial, you’ll know:
- How the Transformer structure implements an encoder-decoder construction with out recurrence and convolutions.
- How the Transformer encoder and decoder work.
- How the Transformer self-attention compares to using recurrent and convolutional layers.
Let’s get began.
The Transformer Mannequin
Photograph by Samule Solar, some rights reserved.
Tutorial Overview
This tutorial is split into three elements; they’re:
- The Transformer Structure
- Sum Up: The Transformer Mannequin
- Comparability to Recurrent and Convolutional Layers
Conditions
For this tutorial, we assume that you’re already conversant in:
The Transformer Structure
The Transformer structure follows an encoder-decoder construction, however doesn’t depend on recurrence and convolutions with the intention to generate an output.

The Encoder-Decoder Construction of the Transformer Structure
Taken from “Consideration Is All You Want“
In a nutshell, the duty of the encoder, on the left half of the Transformer structure, is to map an enter sequence to a sequence of steady representations, which is then fed right into a decoder.
The decoder, on the proper half of the structure, receives the output of the encoder along with the decoder output on the earlier time step, to generate an output sequence.
At every step the mannequin is auto-regressive, consuming the beforehand generated symbols as extra enter when producing the subsequent.
– Consideration Is All You Want, 2017.
The Encoder
The Encoder Block of the Transformer Structure
Taken from “Consideration Is All You Want“
The encoder consists of a stack of $N$ = 6 equivalent layers, the place every layer consists of two sublayers:
- The primary sublayer implements a multi-head self-attention mechanism. We had seen that the multi-head mechanism implements $h$ heads that obtain a (completely different) linearly projected model of the queries, keys and values every, to supply $h$ outputs in parallel which are then used to generate a ultimate outcome.
- The second sublayer is a completely linked feed-forward community, consisting of two linear transformations with Rectified Linear Unit (ReLU) activation in between:
$$textual content{FFN}(x) = textual content{ReLU}(mathbf{W}_1 x + b_1) mathbf{W}_2 + b_2$$
The six layers of the Transformer encoder apply the identical linear transformations to all the phrases within the enter sequence, however every layer employs completely different weight ($mathbf{W}_1, mathbf{W}_2$) and bias ($b_1, b_2$) parameters to take action.
Moreover, every of those two sublayers has a residual connection round it.
Every sublayer can also be succeeded by a normalization layer, $textual content{layernorm}(.)$, which normalizes the sum computed between the sublayer enter, $x$, and the output generated by the sublayer itself, $textual content{sublayer}(x)$:
$$textual content{layernorm}(x + textual content{sublayer}(x))$$
An essential consideration to remember is that the Transformer structure can’t inherently seize any details about the relative positions of the phrases within the sequence, because it doesn’t make use of recurrence. This data must be injected by introducing positional encodings to the enter embeddings.
The positional encoding vectors are of the identical dimension because the enter embeddings, and are generated utilizing sine and cosine capabilities of various frequencies. Then, they’re merely summed to the enter embeddings with the intention to inject the positional data.
The Decoder
The Decoder Block of the Transformer Structure
Taken from “Consideration Is All You Want“
The decoder shares a number of similarities with the encoder.
The decoder additionally consists of a stack of $N$ = 6 equivalent layers which are, every, composed of three sublayers:
- The primary sublayer receives the earlier output of the decoder stack, augments it with positional data, and implements multi-head self-attention over it. Whereas the encoder is designed to take care of all phrases within the enter sequence, regardless of their place within the sequence, the decoder is modified to attend solely to the previous phrases. Therefore, the prediction for a phrase at place, $i$, can solely depend upon the recognized outputs for the phrases that come earlier than it within the sequence. Within the multi-head consideration mechanism (which implements a number of, single consideration capabilities in parallel), that is achieved by introducing a masks over the values produced by the scaled multiplication of matrices $mathbf{Q}$ and $mathbf{Okay}$. This masking is applied by suppressing the matrix values that may, in any other case, correspond to unlawful connections:
$$
textual content{masks}(mathbf{QK}^T) =
textual content{masks} left( start{bmatrix}
e_{11} & e_{12} & dots & e_{1n}
e_{21} & e_{22} & dots & e_{2n}
vdots & vdots & ddots & vdots
e_{m1} & e_{m2} & dots & e_{mn}
finish{bmatrix} proper) =
start{bmatrix}
e_{11} & -infty & dots & -infty
e_{21} & e_{22} & dots & -infty
vdots & vdots & ddots & vdots
e_{m1} & e_{m2} & dots & e_{mn}
finish{bmatrix}
$$
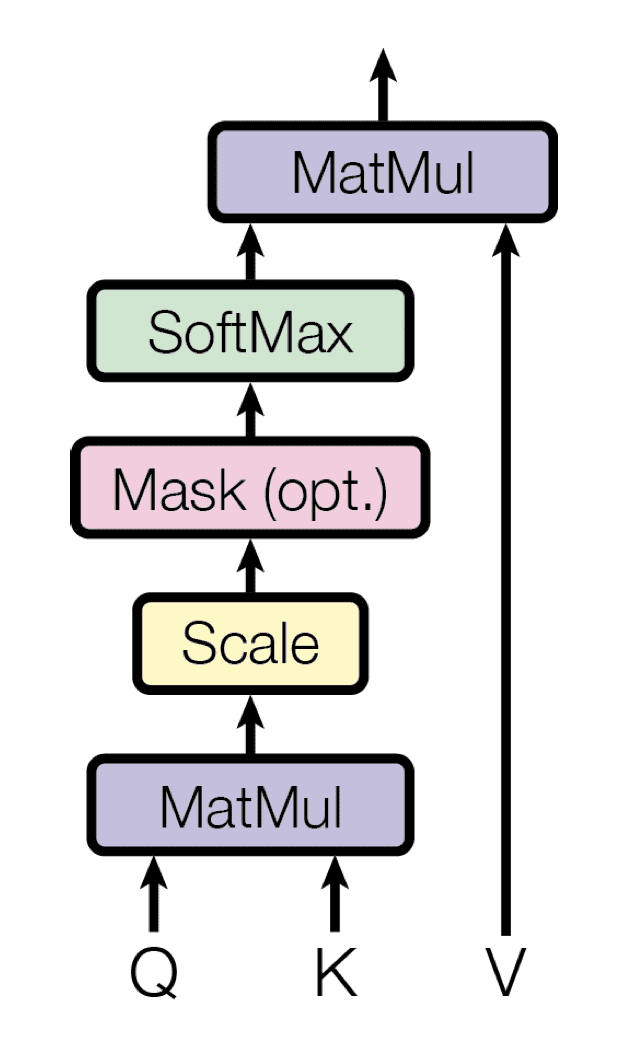
The Multi-Head Consideration within the Decoder Implements A number of Masked, Single Consideration Features
Taken from “Consideration Is All You Want“
The masking makes the decoder unidirectional (in contrast to the bidirectional encoder).
– Superior Deep Studying with Python, 2019.
- The second layer implements a multi-head self-attention mechanism, which is analogous to the one applied within the first sublayer of the encoder. On the decoder facet, this multi-head mechanism receives the queries from the earlier decoder sublayer, and the keys and values from the output of the encoder. This enables the decoder to take care of all the phrases within the enter sequence.
- The third layer implements a completely linked feed-forward community, which is analogous to the one applied within the second sublayer of the encoder.
Moreover, the three sublayers on the decoder facet even have residual connections round them, and are succeeded by a normalization layer.
Positional encodings are additionally added to the enter embeddings of the decoder, in the identical method as beforehand defined for the encoder.
Sum Up: The Transformer Mannequin
The Transformer mannequin runs as follows:
- Every phrase forming an enter sequence is reworked right into a $d_{textual content{mannequin}}$-dimensional embedding vector.
- Every embedding vector representing an enter phrase is augmented by summing it (element-wise) to a positional encoding vector of the identical $d_{textual content{mannequin}}$ size, therefore introducing positional data into the enter.
- The augmented embedding vectors are fed into the encoder block, consisting of the 2 sublayers defined above. For the reason that encoder attends to all phrases within the enter sequence, irrespective in the event that they precede or succeed the phrase into consideration, then the Transformer encoder is bidirectional.
- The decoder receives as enter its personal predicted output phrase at time-step, $t – 1$.
- The enter to the decoder can also be augmented by positional encoding, in the identical method as that is carried out on the encoder facet.
- The augmented decoder enter is fed into the three sublayers comprising the decoder block defined above. Masking is utilized within the first sublayer, with the intention to cease the decoder from attending to succeeding phrases. On the second sublayer, the decoder additionally receives the output of the encoder, which now permits the decoder to take care of all the phrases within the enter sequence.
- The output of the decoder lastly passes via a completely linked layer, adopted by a softmax layer, to generate a prediction for the subsequent phrase of the output sequence.
Comparability to Recurrent and Convolutional Layers
Vaswani et al. (2017) clarify that their motivation for abandoning using recurrence and convolutions was based mostly on a number of elements:
- Self-attention layers had been discovered to be quicker than recurrent layers for shorter sequence lengths, and may be restricted to think about solely a neighbourhood within the enter sequence for very lengthy sequence lengths.
- The variety of sequential operations required by a recurrent layer relies upon the sequence size, whereas this quantity stays fixed for a self-attention layer.
- In convolutional neural networks, the kernel width instantly impacts the long-term dependencies that may be established between pairs of enter and output positions. Monitoring long-term dependencies would require using giant kernels, or stacks of convolutional layers that would enhance the computational value.
Additional Studying
This part offers extra assets on the subject in case you are seeking to go deeper.
Books
Papers
Abstract
On this tutorial, you found the community structure of the Transformer mannequin.
Particularly, you discovered:
- How the Transformer structure implements an encoder-decoder construction with out recurrence and convolutions.
- How the Transformer encoder and decoder work.
- How the Transformer self-attention compares to recurrent and convolutional layers.
Do you might have any questions?
Ask your questions within the feedback beneath and I’ll do my greatest to reply.
[ad_2]