

{kind=link}
[ad_1]
Many experimental works have noticed that generalization in deep RL seems to be troublesome: though RL brokers can be taught to carry out very complicated duties, they don’t appear to generalize over numerous activity distributions in addition to the wonderful generalization of supervised deep nets may lead us to count on. On this weblog submit, we’ll purpose to clarify why generalization in RL is basically more durable, and certainly harder even in concept.
We’ll present that making an attempt to generalize in RL induces implicit partial observability, even when the RL downside we are attempting to unravel is a regular fully-observed MDP. This induced partial observability can considerably complicate the sorts of insurance policies wanted to generalize nicely, doubtlessly requiring counterintuitive methods like information-gathering actions, recurrent non-Markovian habits, or randomized methods. Ordinarily, this isn’t crucial in totally noticed MDPs however surprisingly turns into crucial once we take into account generalization from a finite coaching set in a completely noticed MDP. This weblog submit will stroll by why partial observability can implicitly come up, what it means for the generalization efficiency of RL algorithms, and the way strategies can account for partial observability to generalize nicely.
Studying By Instance
Earlier than formally analyzing generalization in RL, let’s start by strolling by two examples that illustrate what could make generalizing nicely in RL issues troublesome.
The Picture Guessing Sport: On this sport, an RL agent is proven a picture every episode, and should guess its label as rapidly as attainable (Determine 1). Every timestep, the agent makes a guess; if the agent is right, then the episode ends, but when incorrect, the agent receives a detrimental reward, and should make one other guess for a similar picture on the subsequent timestep. Since every picture has a novel label (that’s, there may be some “true” labelling perform $f_{true}: x mapsto y$) and the agent receives the picture as commentary, it is a fully-observable RL atmosphere.
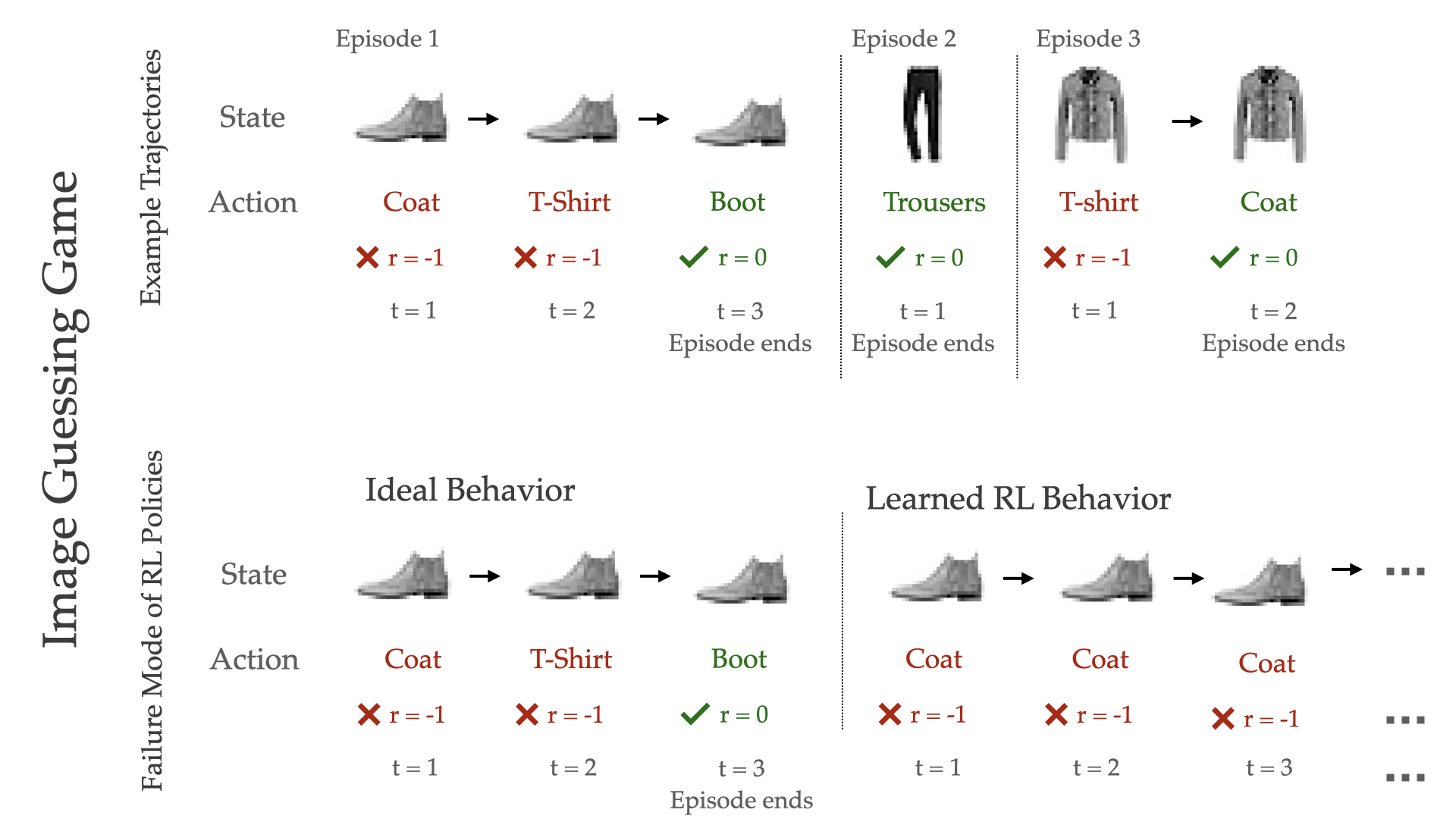
Fig 1. The picture guessing sport, which requires an agent to repeatedly guess labels for a picture till it will get it right. RL learns insurance policies that guess the identical label repeatedly, a method that generalizes poorly to check photographs (backside row, proper).
Suppose we had entry to an infinite variety of coaching photographs, and realized a coverage utilizing a regular RL algorithm. This coverage will be taught to deterministically predict the true label ($y := f_{true}(x)$), since that is the best return technique within the MDP (as a sanity test, recall that the optimum coverage in an MDP is deterministic and memoryless). If we solely have a restricted set of coaching photographs, an RL algorithm will nonetheless be taught the identical technique, deterministically predicting the label it believes matches the picture. However, does this coverage generalize nicely? On an unseen take a look at picture, if the agent’s predicted label is right, the best attainable reward is attained; if incorrect, the agent receives catastrophically low return, because it by no means guesses the proper label. This catastrophic failure mode is ever-present, since regardless that trendy deep nets enhance generalization and cut back the prospect of misclassification, error on the take a look at set can’t be fully diminished to 0.
Can we do higher than this deterministic prediction technique? Sure, for the reason that realized RL technique ignores two salient options of the guessing sport: 1) the agent receives suggestions by an episode as as to whether its guesses are right, and a couple of) the agent can change its guess in future timesteps. One technique that higher takes benefit of those options is process-of-elimination; first, deciding on the label it considers most definitely, and if incorrect, eliminating it and adapting to the subsequent most-likely label, and so forth. This sort of adaptive memory-based technique, nonetheless, can by no means be realized by a regular RL algorithm like Q-learning, since they optimize MDP targets and solely be taught deterministic and memoryless insurance policies.
Maze-Fixing: A staple of RL generalization benchmarks, the maze-solving downside requires an agent to navigate to a purpose in a maze given a birds-eye view of the entire maze. This activity is fully-observed, for the reason that agent’s commentary exhibits the entire maze. Because of this, the optimum coverage is memoryless and deterministic: taking the motion that strikes the agent alongside the shortest path to the purpose. Simply as within the image-guessing sport, by maximizing return inside the coaching maze layouts, an RL algorithm will be taught insurance policies akin to this “optimum” technique – at any state, deterministically taking the motion that it considers most definitely to be on the shortest path to the purpose.
This RL coverage generalizes poorly, since if the realized coverage ever chooses an incorrect motion, like working right into a wall or doubling again on its outdated path, it would proceed to loop the identical mistake and by no means clear up the maze. This failure mode is totally avoidable, since even when the RL agent initially takes such an “incorrect” motion, after making an attempt to comply with it, the agent receives info (e.g. the subsequent commentary) as as to whether or not this was a superb motion. To generalize in addition to attainable, an agent ought to adapt its chosen actions if the unique actions led to surprising outcomes , however this habits eludes customary RL targets.
Fig 2. Within the maze activity, RL insurance policies generalize poorly: once they make an error, they repeatedly make the identical error, resulting in failure (left). An agent that generalizes nicely should still make errors, however has the potential of adapting and recovering from these errors (proper). This habits isn’t realized by customary RL targets for generalization.
What’s Going On? RL and Epistemic Uncertainty
In each the guessing sport and the maze activity, the hole between habits realized by customary RL algorithms and by insurance policies that truly generalize nicely, appeared to come up when the agent incorrectly (or couldn’t) recognized how the dynamics of the world behave. Let’s dig deeper into this phenomenon.
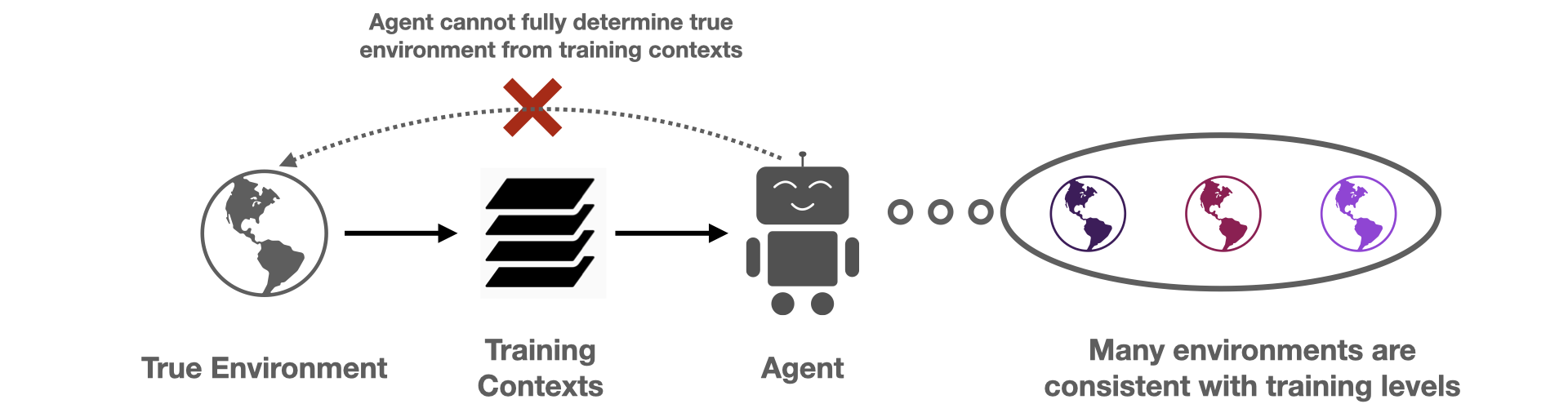
Fig 3. The restricted coaching dataset prevents an agent from precisely recovering the true atmosphere. As an alternative, there may be an implicit partial observability, as an agent doesn’t know which amongst the set of “constant” environments is the true atmosphere.
When the agent is given a small coaching set of contexts, there are a lot of dynamics fashions that match the supplied coaching contexts, however differ on held-out contexts. These conflicting hypotheses epitomize the agent’s epistemic uncertainty from the restricted coaching set. Whereas uncertainty isn’t particular to RL, how it may be dealt with in RL is exclusive as a result of sequential resolution making loop. For instance, the agent can actively regulate how a lot epistemic uncertainty it’s uncovered to, for instance by selecting a coverage that solely visits states the place the agent is very assured concerning the dynamics. Much more importantly, the agent can change its epistemic uncertainty at analysis time by accounting for the data that it receives by the trajectory. Suppose for a picture within the guessing sport, the agent is initially unsure between the t-shirt / coat labels. If the agent guesses “t-shirt” and receives suggestions that this was incorrect, the agent modifications its uncertainty and turns into extra assured concerning the “coat” label, which means it ought to consequently adapt and guess “coat” as a substitute.
Epistemic POMDPs and Implicit Partial Observability
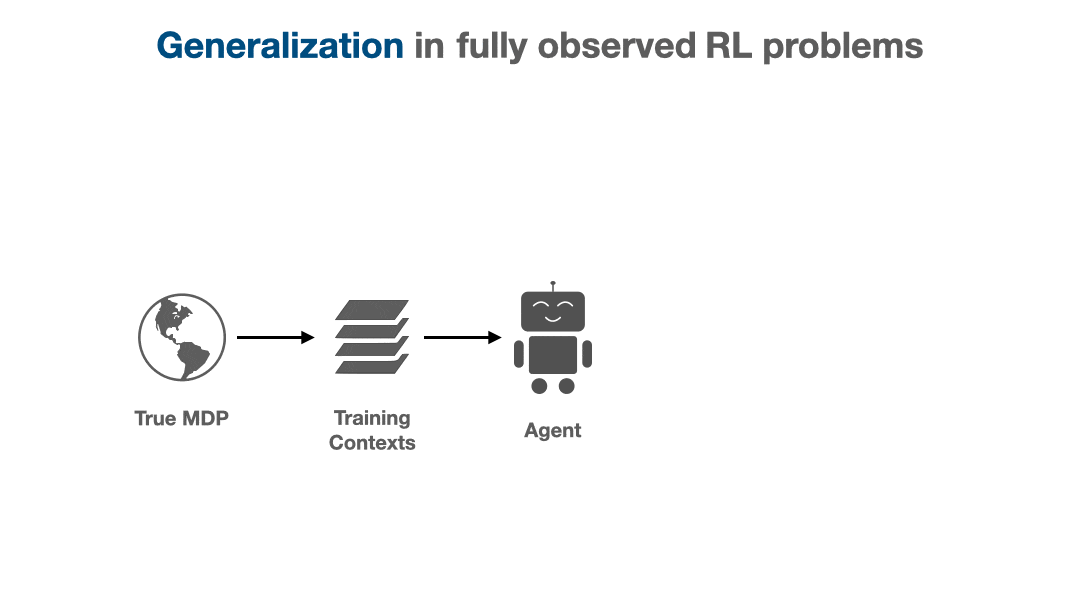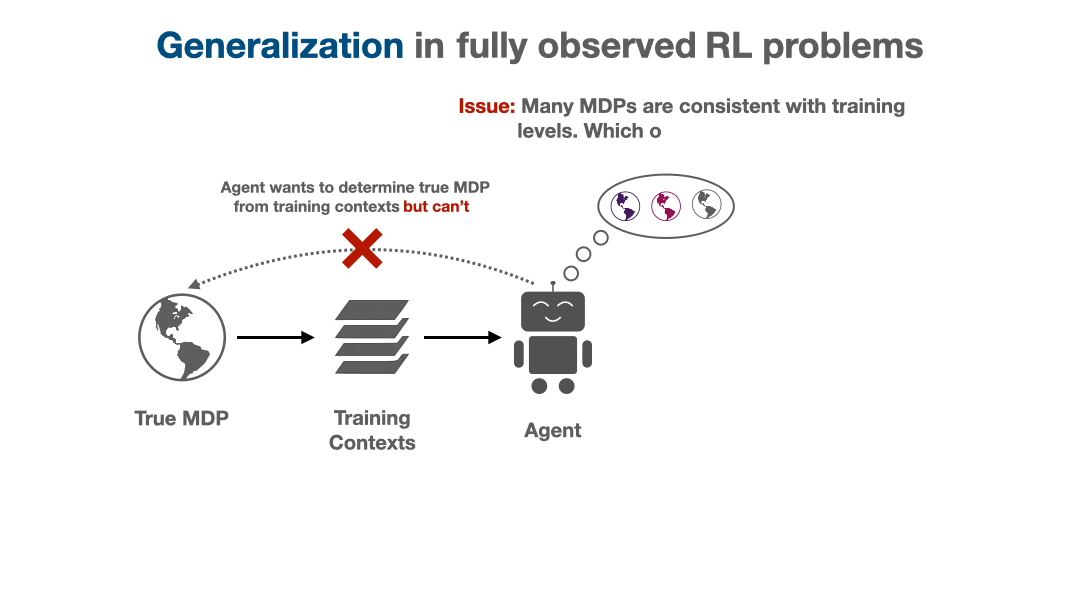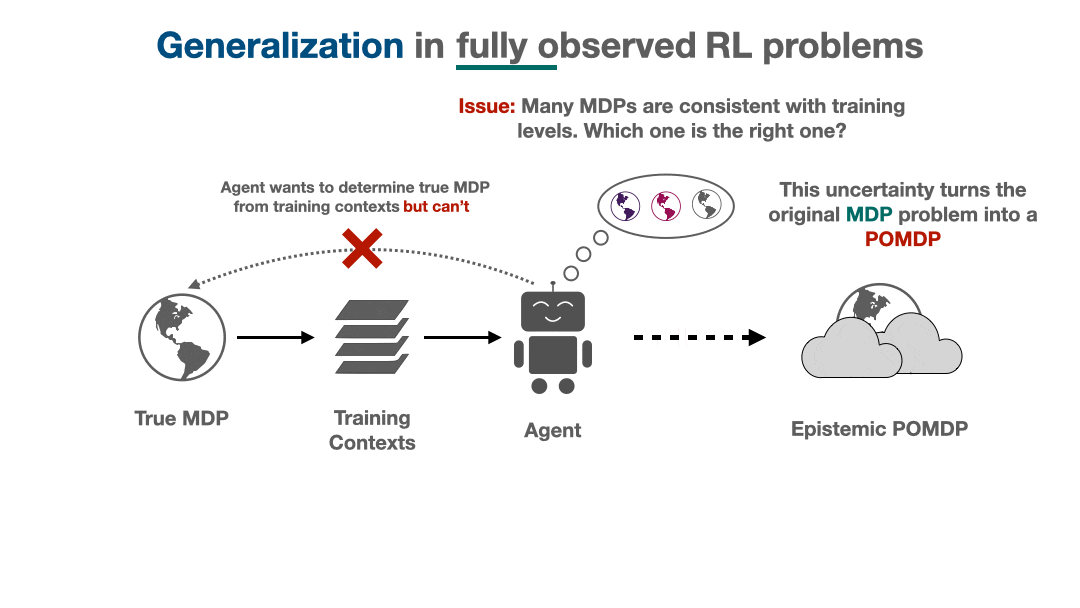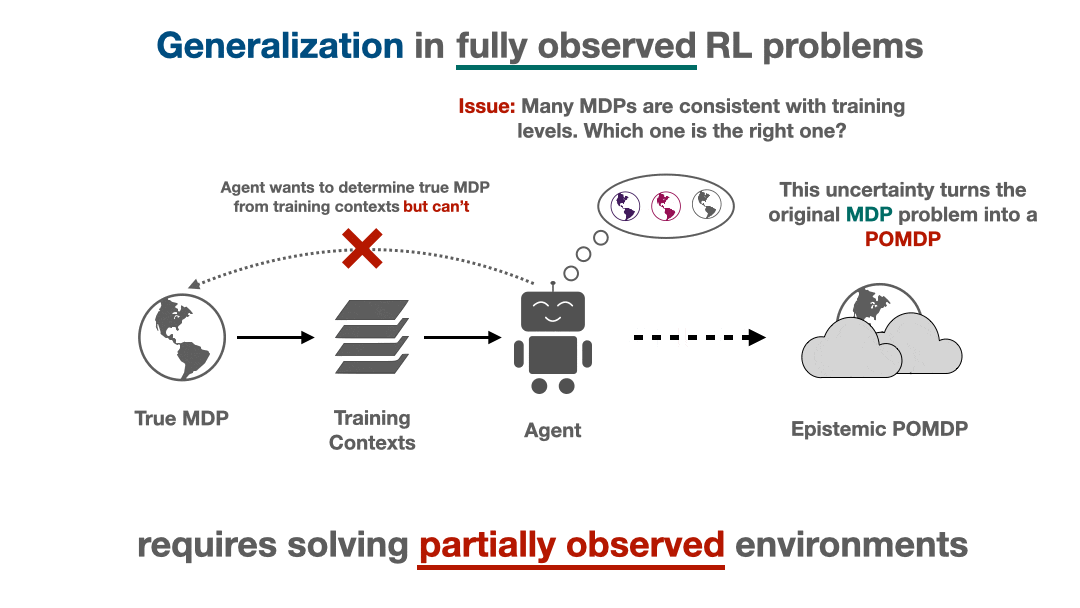
Actively steering in the direction of areas of low uncertainty or taking information-gathering actions are two of a mess of avenues an RL agent has to deal with its epistemic uncertainty. Two essential questions stay unanswered: is there a “finest” approach to deal with uncertainty? In that case, how can we describe it? From the Bayesian perspective, it seems there may be an optimum answer: generalizing optimally requires us to unravel {a partially} noticed MDP (POMDP) that’s implicitly created from the agent’s epistemic uncertainty.
This POMDP, which we name the epistemic POMDP, works as follows. Recall that as a result of the agent has solely seen a restricted coaching set, there are a lot of attainable environments which are according to the coaching contexts supplied. The set of constant environments might be encoded by a Bayesian posterior over environments $P(M mid D)$. Every episode within the epistemic POMDP, an agent is dropped into one in all these “constant” environments $M sim P(M mid D)$, and requested to maximise return inside it, however with the next essential element: the agent isn’t informed which atmosphere $M$ it was positioned in.
This technique corresponds to a POMDP (partially noticed MDP), for the reason that related info wanted to behave is just partially observable to the agent: though the state $s$ inside the atmosphere is noticed, the identification of the atmosphere $M$ that’s producing these states is hidden from the agent. The epistemic POMDP gives an instantiation of the generalization downside into the Bayesian RL framework (see survey right here), which extra typically research optimum habits underneath distributions over MDPs.
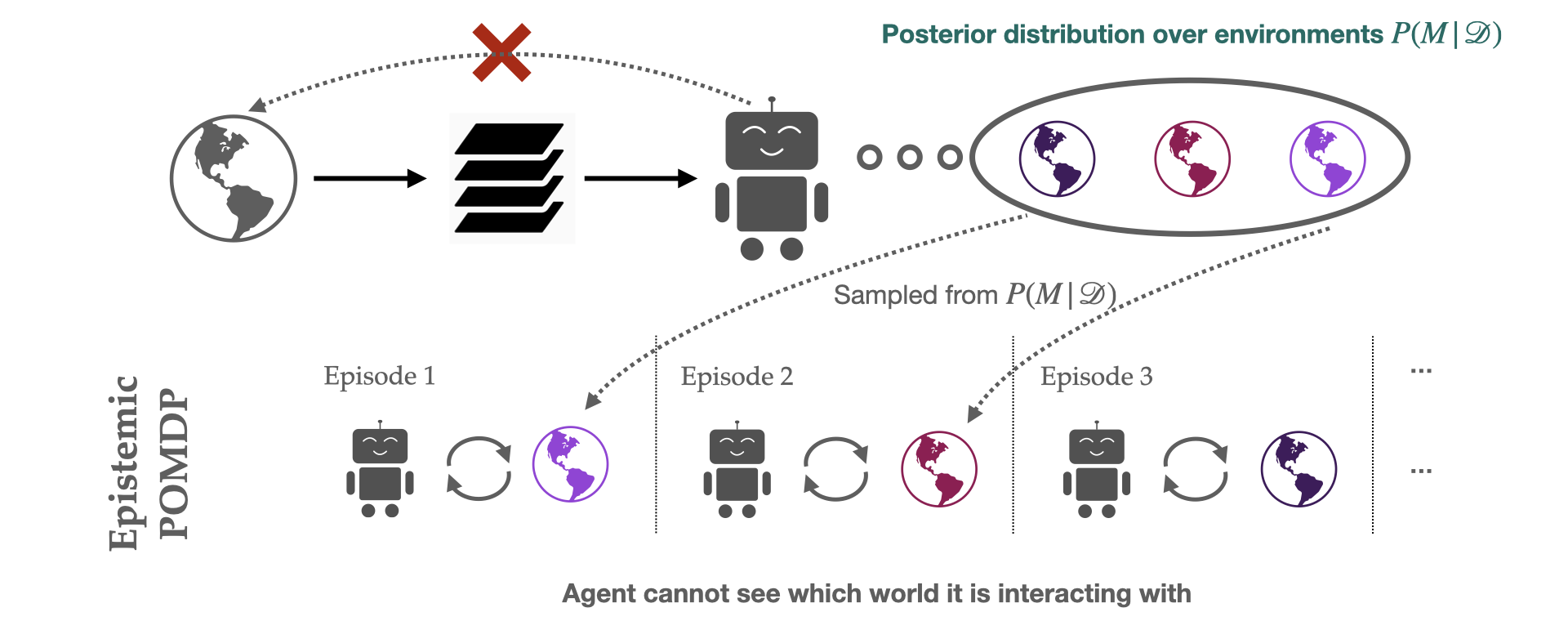
Fig 4. Within the epistemic POMDP, an agent interacts with a special “constant” atmosphere in every episode, however doesn’t know which one it’s interacting with, resulting in partial observability. To do nicely, an agent should make use of a (doubtlessly memory-based) technique that works nicely irrespective of which of those environments it’s positioned in.
Let’s stroll by an instance of what the epistemic POMDP seems like. For the guessing sport, the agent is unsure about precisely how photographs are labelled, so every attainable atmosphere $M sim P(M mid D)$ corresponds to a special picture labeller that’s according to the coaching dataset: $f_M: X to Y$. Within the epistemic POMDP for the guessing sport, every episode, a picture $x$ and labeller $f_M$ are chosen at random, and the agent required to output the label that’s assigned by the sampled classifier $y = f_M(x)$. The agent can not do that instantly, as a result of the identification of the classifier $f_M$ is not supplied to the agent, solely the picture $x$. If all of the labellers $f_M$ within the posterior agree on the label for a sure picture, the agent can simply output this label (no partial observability). Nevertheless, if totally different classifiers assign totally different labels, the agent should use a method that works nicely on common, no matter which of the labellers was used to label the info (for instance, by adaptive process-of-elimination guessing or randomized guessing).
What makes the epistemic POMDP notably thrilling is the next equivalence:
An RL agent is Bayes-optimal for generalization if and provided that it maximizes anticipated return within the corresponding epistemic POMDP. Extra typically, the efficiency of an agent within the epistemic POMDP dictates how nicely it’s anticipated to generalize at analysis time.
That generalization efficiency is dictated by efficiency within the epistemic POMDP hints at a couple of classes for bridging the hole between the “optimum” approach to generalize in RL and present practices. For instance, it’s comparatively well-known that the optimum coverage in a POMDP is usually non-Markovian (adaptive primarily based on historical past), and will take information-gathering actions to scale back the diploma of partial observability. Which means to generalize optimally, we’re more likely to want adaptive information-gathering behaviors as a substitute of the static Markovian insurance policies which are normally skilled.
The epistemic POMDP additionally highlights the perils of our predominant strategy to studying insurance policies from a restricted coaching set of contexts: working a fully-observable RL algorithm on the coaching set. These algorithms mannequin the atmosphere as an MDP and be taught MDP-optimal methods, that are deterministic and Markov. These insurance policies don’t account for partial observability, and due to this fact are likely to generalize poorly (for instance, within the guessing sport and maze duties). This means a mismatch between the MDP-based coaching targets which are customary in trendy algorithms and the epistemic POMDP coaching goal that truly dictates how nicely the realized coverage generalizes.
Shifting Ahead with Generalization in RL
The implicit presence of partial observability at take a look at time might clarify why customary RL algorithms, which optimize fully-observed MDP targets, fail to generalize. What ought to we do as a substitute to be taught RL insurance policies that generalize higher? The epistemic POMDP gives a prescriptive answer: when the agent’s posterior distribution over environments might be calculated, then setting up the epistemic POMDP and working a POMDP-solving algorithm on it would yield insurance policies that generalize Bayes-optimally.
Sadly, in most fascinating issues, this can’t be precisely achieved. Nonetheless, the epistemic POMDP can function a lodestar for designing RL algorithms that generalize higher. As a primary step, in our NeurIPS 2021 paper, we introduce an algorithm referred to as LEEP, which makes use of statistical bootstrapping to be taught a coverage in an approximation of the epistemic POMDP. On Procgen, a difficult generalization benchmark for RL brokers, LEEP improves considerably in test-time efficiency over PPO (Determine 3). Whereas solely a crude approximation, LEEP gives some indication that making an attempt to be taught a coverage within the epistemic POMDP could be a fruitful avenue for growing extra generalizable RL algorithms.
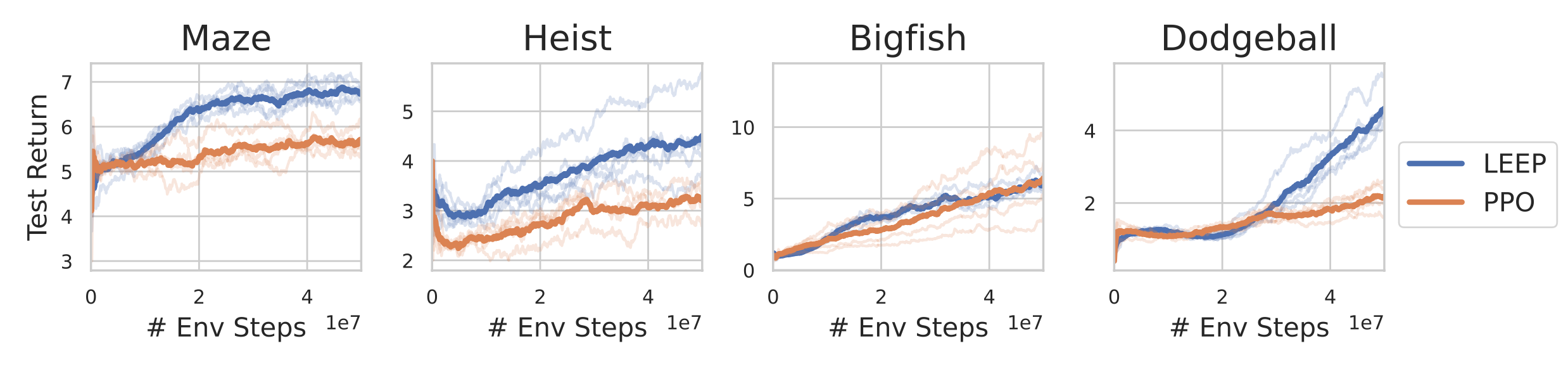
Fig 5. LEEP, an algorithm primarily based on the epistemic POMDP goal, generalizes higher than PPO in 4 Procgen duties.
When you take one lesson from this weblog submit…
In supervised studying, optimizing for efficiency on the coaching set interprets to good generalization efficiency, and it’s tempting to suppose that generalization in RL might be solved in the identical method. That is surprisingly not true; restricted coaching information in RL introduces implicit partial observability into an in any other case fully-observable downside. This implicit partial observability, as formalized by the epistemic POMDP, signifies that generalizing nicely in RL necessitates adaptive or stochastic behaviors, hallmarks of POMDP issues.
Finally, this highlights the incompatibility that afflicts generalization of our deep RL algorithms: with restricted coaching information, our MDP-based RL targets are misaligned with the implicit POMDP goal that finally dictates generalization efficiency.
This submit is predicated on the paper “Why Generalization in RL is Troublesome: Epistemic POMDPs and Implicit Partial Observability,” which is joint work with Jad Rahme (equal contribution), Aviral Kumar, Amy Zhang, Ryan P. Adams, and Sergey Levine. Because of Sergey Levine and Katie Kang for useful suggestions on the weblog submit.
[ad_2]