
{kind=link}
[ad_1]
Machine studying (ML) brokers are more and more deployed in the actual world to make choices and help individuals of their every day lives. Making cheap predictions in regards to the future at various timescales is without doubt one of the most vital capabilities for such brokers as a result of it allows them to foretell modifications on the earth round them, together with different brokers’ behaviors, and plan learn how to act subsequent. Importantly, profitable future prediction requires each capturing significant transitions within the surroundings (e.g., dough remodeling into bread) and adapting to how transitions unfold over time in an effort to make choices.
Earlier work in future prediction from visible observations has largely been constrained by the format of its output (e.g., pixels that symbolize a picture) or a manually-defined set of human actions (e.g., predicting if somebody will hold strolling, sit down, or bounce). These are both too detailed and laborious to foretell or lack vital details about the richness of the actual world. For instance, predicting “particular person leaping” doesn’t seize why they’re leaping, what they’re leaping onto, and so forth. Additionally, with only a few exceptions, earlier fashions had been designed to make predictions at a mounted offset into the long run, which is a limiting assumption as a result of we not often know when significant future states will occur.
For instance, in a video about making ice cream (depicted under), the significant transition from “cream” to “ice cream” happens over 35 seconds, so fashions predicting such transitions would wish to look 35 seconds forward. However this time interval varies a big quantity throughout completely different actions and movies — significant transitions happen at any distance into the long run. Studying to make such predictions at versatile intervals is difficult as a result of the specified floor reality could also be comparatively ambiguous. For instance, the proper prediction could possibly be the just-churned ice cream within the machine, or scoops of the ice cream in a bowl. As well as, amassing such annotations at scale (i.e., frame-by-frame for tens of millions of movies) is infeasible. Nevertheless, many present educational movies include speech transcripts, which frequently provide concise, common descriptions all through complete movies. This supply of knowledge can information a mannequin’s consideration towards vital elements of the video, obviating the necessity for guide labeling and permitting a versatile, data-driven definition of the long run.
In “Studying Temporal Dynamics from Cycles in Narrated Video”, printed at ICCV 2021, we suggest an method that’s self-supervised, utilizing a current massive unlabeled dataset of various human motion. The ensuing mannequin operates at a excessive degree of abstraction, could make predictions arbitrarily far into the long run, and chooses how far into the long run to foretell primarily based on context. Known as Multi-Modal Cycle Consistency (MMCC), it leverages narrated educational video to study a robust predictive mannequin of the long run. We exhibit how MMCC could be utilized, with out fine-tuning, to quite a lot of difficult duties, and qualitatively look at its predictions. Within the instance under, MMCC predicts the long run (d) from current body (a), fairly than much less related potential futures (b) or (c).
 |
| This work makes use of cues from imaginative and prescient and language to foretell high-level modifications (similar to cream turning into ice cream) in video (video from HowTo100M). |
Viewing Movies as Graphs
The muse of our methodology is to symbolize narrated movies as graphs. We view movies as a group of nodes, the place nodes are both video frames (sampled at 1 body per second) or segments of narrated textual content (extracted with computerized speech recognition methods), encoded by neural networks. Throughout coaching, MMCC constructs a graph from the nodes, utilizing cross-modal edges to attach video frames and textual content segments that check with the identical state, and temporal edges to attach the current (e.g., strawberry-flavored cream) and the long run (e.g., soft-serve ice cream). The temporal edges function on each modalities equally — they’ll begin from both a video body, some textual content, or each, and may hook up with a future (or previous) state in both modality. MMCC achieves this by studying a latent illustration shared by frames and textual content after which making predictions on this illustration house.
Multi-modal Cycle Consistency
To study the cross-modal and temporal edge capabilities with out supervision, we apply the concept of cycle consistency. Right here, cycle consistency refers back to the building of cycle graphs, during which the mannequin constructs a collection of edges from an preliminary node to different nodes and again once more: Given a begin node (e.g., a pattern video body), the mannequin is anticipated to seek out its cross-modal counterpart (i.e., textual content describing the body) and mix them because the current state. To do that, firstly of coaching, the mannequin assumes that frames and textual content with the identical timestamps are counterparts, however then relaxes this assumption later. The mannequin then predicts a future state, and the node most just like this prediction is chosen. Lastly, the mannequin makes an attempt to invert the above steps by predicting the current state backward from the long run node, and thus connecting the long run node again with the beginning node.
The discrepancy between the mannequin’s prediction of the current from the long run and the precise current is the cycle-consistency loss. Intuitively, this coaching goal requires the expected future to include sufficient details about its previous to be invertible, resulting in predictions that correspond to significant modifications to the identical entities (e.g., tomato turning into marinara sauce, or flour and eggs in a bowl turning into dough). Furthermore, the inclusion of cross-modal edges ensures future predictions are significant in both modality.
To study the temporal and cross-modal edge capabilities end-to-end, we use the smooth consideration approach, which first outputs how seemingly every node is to be the goal node of the sting, after which “picks” a node by taking the weighted common amongst all potential candidates. Importantly, this cyclic graph constraint makes few assumptions for the sort of temporal edges the mannequin ought to study, so long as they find yourself forming a constant cycle. This permits the emergence of long-term temporal dynamics vital for future prediction with out requiring guide labels of significant modifications.
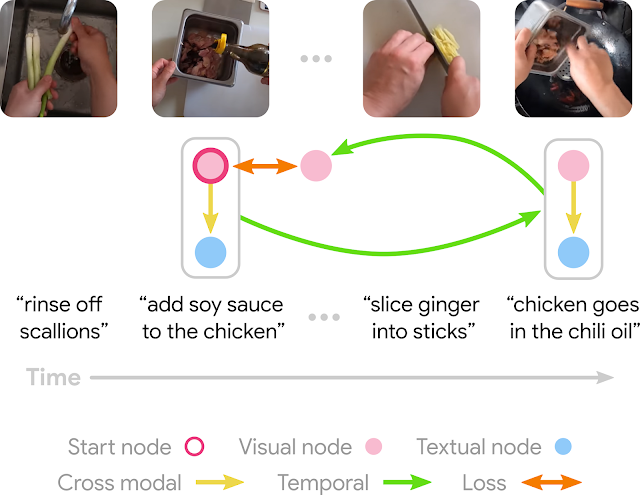 |
| An instance of the coaching goal: A cycle graph is anticipated to be constructed between the rooster with soy sauce and the rooster in chili oil as a result of they’re two adjoining steps within the rooster’s preparation (video from HowTo100M). |
Discovering Cycles in Actual-World Video
MMCC is skilled with none express floor reality, utilizing solely lengthy video sequences and randomly sampled beginning circumstances (a body or textual content excerpt) and asking the mannequin to seek out temporal cycles. After coaching, MMCC can determine significant cycles that seize advanced modifications in video.
 |
| Given frames as enter (left), MMCC selects related textual content from video narrations and makes use of each modalities to foretell a future body (center). It then finds textual content related to this future and makes use of it to foretell the previous (proper). Utilizing its data of how objects and scenes change over time, MMCC “closes the cycle” and finally ends up the place it began (movies from HowTo100M). |
 |
| The mannequin may begin from narrated textual content fairly than frames and nonetheless discover related transitions (movies from HowTo100M). |
Zero-Shot Purposes
For MMCC to determine significant transitions over time in a complete video, we outline a “seemingly transition rating” for every pair (A, B) of frames in a video, based on the mannequin’s predictions — the nearer B is to our mannequin’s prediction of the way forward for A, the upper the rating assigned. We then rank all pairs based on this rating and present the highest-scoring pairs of current and future frames detected in beforehand unseen movies (examples under).
 |
| The best-scoring pairs from eight random movies, which showcase the flexibility of the mannequin throughout a variety of duties (movies from HowTo100M). |
We will use this similar method to temporally kind an unordered assortment of video frames with none fine-tuning by discovering an ordering that maximizes the general confidence scores between all adjoining frames within the sorted sequence.
 |
| Left: Shuffled frames from three movies. Proper: MMCC unshuffles the frames. The true order is proven beneath every body. Even when MMCC doesn’t predict the bottom reality, its predictions typically seem cheap, and so, it might current an alternate ordering (movies from HowTo100M). |
Evaluating Future Prediction
We consider the mannequin’s capability to anticipate motion, probably minutes prematurely, utilizing the top-k recall metric, which right here measures a mannequin’s capability to retrieve the proper future (greater is healthier). On CrossTask, a dataset of instruction movies with labels describing key steps, MMCC outperforms the earlier self-supervised state-of-the-art fashions in inferring potential future actions.
| Recall | |||||||
| Mannequin | High-1 | High-5 | High-10 | ||||
| Cross-modal | 2.9 | 14.2 | 24.3 | ||||
| Repr. Ant. | 3.0 | 13.3 | 26.0 | ||||
| MemDPC | 2.9 | 15.8 | 27.4 | ||||
| TAP | 4.5 | 17.1 | 27.9 | ||||
| MMCC | 5.4 | 19.9 | 33.8 | ||||
Conclusions
We’ve got launched a self-supervised methodology to study temporal dynamics by biking by way of narrated educational movies. Regardless of the simplicity of the mannequin’s structure, it might uncover significant long-term transitions in imaginative and prescient and language, and could be utilized with out additional coaching to difficult downstream duties, similar to anticipating far-away motion and ordering collections of photos. An attention-grabbing future route is transferring the mannequin to brokers to allow them to use it to conduct long-term planning.
Acknowledgements
The core crew consists of Dave Epstein, Jiajun Wu, Cordelia Schmid, and Chen Solar. We thank Alexei Efros, Mia Chiquier, and Shiry Ginosar for his or her suggestions, and Allan Jabri for inspiration in determine design. Dave wish to thank Dídac Surís and Carl Vondrick for insightful early discussions on biking by way of time in video.
[ad_2]