
{kind=link}
[ad_1]
For a lot of ideas, there is no such thing as a direct one-to-one translation from one language to a different, and even when there’s, such translations usually carry completely different associations and connotations which might be simply misplaced for a non-native speaker. In such circumstances, nonetheless, the which means could also be extra apparent when grounded in visible examples. Take, for example, the phrase “wedding ceremony”. In English, one usually associates a bride in a white costume and a groom in a tuxedo, however when translated into Hindi (शादी), a extra acceptable affiliation could also be a bride sporting vibrant colours and a groom sporting a sherwani. What every particular person associates with the phrase might fluctuate significantly, but when they’re proven a picture of the meant idea, the which means turns into extra clear.
 |
| The phrase “wedding ceremony” in English and Hindi conveys completely different psychological pictures. Photos are taken from wikipedia, credited to Psoni2402 (left) and David McCandless (proper) with CC BY-SA 4.0 license. |
With present advances in neural machine translation and picture recognition, it’s potential to scale back this kind of ambiguity in translation by presenting a textual content paired with a supporting picture. Prior analysis has made a lot progress in studying picture–textual content joint representations for high-resource languages, equivalent to English. These illustration fashions try to encode the picture and textual content into vectors in a shared embedding area, such that the picture and the textual content describing it are shut to one another in that area. For instance, ALIGN and CLIP have proven that coaching a dual-encoder mannequin (i.e., one educated with two separate encoders) on picture–textual content pairs utilizing a contrastive studying loss works remarkably properly when supplied with ample coaching knowledge.
Sadly, such picture–textual content pair knowledge doesn’t exist on the identical scale for almost all of languages. In truth, greater than 90% of this kind of internet knowledge belongs to the top-10 highly-resourced languages, equivalent to English and Chinese language, with a lot much less knowledge for under-resourced languages. To beat this challenge, one may both attempt to manually gather picture–textual content pair knowledge for under-resourced languages, which might be prohibitively tough because of the scale of the enterprise, or one may search to leverage pre-existing datasets (e.g., translation pairs) that might inform the required discovered representations for a number of languages.
In “MURAL: Multimodal, Multitask Representations Throughout Languages”, offered at Findings of EMNLP 2021, we describe a illustration mannequin for picture–textual content matching that makes use of multitask studying utilized to picture–textual content pairs together with translation pairs overlaying 100+ languages. This know-how may permit customers to precise phrases that will not have a direct translation right into a goal language utilizing pictures as an alternative. For instance, the phrase “valiha”, refers to a sort of tube zither performed by the Malagasy individuals, which lacks a direct translation into most languages, however may very well be simply described utilizing pictures. Empirically, MURAL exhibits constant enhancements over state-of-the-art fashions, different benchmarks, and aggressive baselines throughout the board. Furthermore, MURAL does remarkably properly for almost all of the under-resourced languages on which it was examined. Moreover, we uncover fascinating linguistic correlations discovered by MURAL representations.
MURAL Structure
The MURAL structure is predicated on the construction of ALIGN, however employed in a multitask vogue. Whereas ALIGN makes use of a dual-encoder structure to attract collectively representations of pictures and related textual content descriptions, MURAL employs the dual-encoder construction for a similar objective whereas additionally extending it throughout languages by incorporating translation pairs. The dataset of picture–textual content pairs is similar as that used for ALIGN, and the interpretation pairs are these used for LaBSE.
MURAL solves two contrastive studying duties: 1) picture–textual content matching and a couple of) textual content–textual content (bitext) matching, with each duties sharing the textual content encoder module. The mannequin learns associations between pictures and textual content from the picture–textual content knowledge, and learns the representations of lots of of numerous languages from the interpretation pairs. The concept is {that a} shared encoder will switch the picture–textual content affiliation discovered from high-resource languages to under-resourced languages. We discover that the perfect mannequin employs an EfficientNet-B7 picture encoder and a BERT-large textual content encoder, each educated from scratch. The discovered illustration can be utilized for downstream visible and vision-language duties.
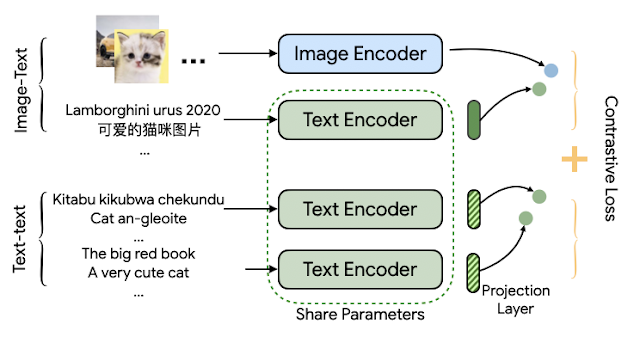 |
| The structure of MURAL depicts twin encoders with a shared text-encoder between the 2 duties educated utilizing a contrastive studying loss. |
Multilingual Picture-to-Textual content and Textual content-to-Picture Retrieval
To show MURAL’s capabilities, we select the duty of cross-modal retrieval (i.e., retrieving related pictures given a textual content and vice versa) and report the scores on numerous educational picture–textual content datasets overlaying well-resourced languages, equivalent to MS-COCO (and its Japanese variant, STAIR), Flickr30K (in English) and Multi30K (prolonged to German, French, Czech), XTD (test-only set with seven well-resourced languages: Italian, Spanish, Russian, Chinese language, Polish, Turkish, and Korean). Along with well-resourced languages, we additionally consider MURAL on the not too long ago revealed Wikipedia Picture–Textual content (WIT) dataset, which covers 108 languages, with a broad vary of each well-resourced (English, French, Chinese language, and so forth.) and under-resourced (Swahili, Hindi, and so forth.) languages.
MURAL constantly outperforms prior state-of-the-art fashions, together with M3P, UC2, and ALIGN, in each zero-shot and fine-tuned settings evaluated on well-resourced and under-resourced languages. We see exceptional efficiency positive factors for under-resourced languages when in comparison with the state-of-the-art mannequin, ALIGN.
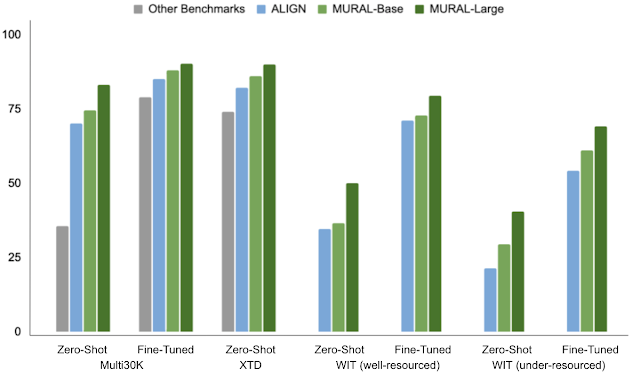 |
| Imply recall on numerous multilingual picture–textual content retrieval benchmarks. Imply recall is a typical metric used to judge cross-modal retrieval efficiency on picture–textual content datasets (increased is best). It measures the Recall@N (i.e., the possibility that the bottom reality picture seems within the first N retrieved pictures) averaged over six measurements: Picture→Textual content and Textual content→Picture retrieval for N=[1, 5, 10]. Observe that XTD scores report Recall@10 for Textual content→Picture retrieval. |
Retrieval Evaluation
We additionally analyzed zero-shot retrieved examples on the WIT dataset evaluating ALIGN and MURAL for English (en) and Hindi (hello). For under-resourced languages like Hindi, MURAL exhibits improved retrieval efficiency in comparison with ALIGN that displays a greater grasp of the textual content semantics.
 |
| Comparability of the top-5 pictures retrieved by ALIGN and by MURAL for the Textual content→Picture retrieval process on the WIT dataset for the Hindi textual content, एक तश्तरी पर बिना मसाले या सब्ज़ी के रखी हुई सादी स्पगॅत्ती”, which interprets to the English, “A bowl containing plain noodles with none spices or greens”. |
Even for Picture→Textual content retrieval in a well-resourced language, like French, MURAL exhibits higher understanding for some phrases. For instance, MURAL returns higher outcomes for the question “cadran solaire” (“sundial”, in French) than ALIGN, which doesn’t retrieve any textual content describing sundials (under).
 |
| Comparability of the top-5 textual content outcomes from ALIGN and from MURAL on the Picture→Textual content retrieval process for a similar picture of a sundial. |
Embeddings Visualization
Beforehand, researchers have proven that visualizing mannequin embeddings can reveal fascinating connections amongst languages — for example, representations discovered by a neural machine translation (NMT) mannequin have been proven to kind clusters based mostly on their membership to a language household. We carry out the same visualization for a subset of languages belonging to the Germanic, Romance, Slavic, Uralic, Finnic, Celtic, and Finno-Ugric language households (extensively spoken in Europe and Western Asia). We examine MURAL’s textual content embeddings with LaBSE’s, which is a text-only encoder.
A plot of LabSE’s embeddings exhibits distinct clusters of languages influenced by language households. As an illustration, Romance languages (in purple, under) fall into a special area than Slavic languages (in brown, under). This discovering is in keeping with prior work that investigates intermediate representations discovered by a NMT system.
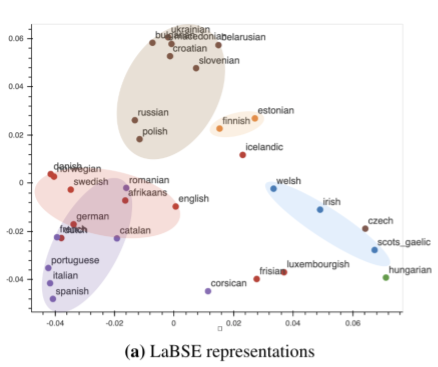 |
| Visualization of textual content representations of LaBSE for 35 languages. Languages are shade coded based mostly on their genealogical affiliation. Consultant languages embrace: Germanic (pink) — German, English, Dutch; Uralic (orange) — Finnish, Estonian; Slavic (brown) — Polish, Russian; Romance (purple) — Italian, Portuguese, Spanish; Gaelic (blue) — Welsh, Irish. |
In distinction to LaBSE’s visualization, MURAL’s embeddings, that are discovered with a multimodal goal, exhibits some clusters which might be consistent with areal linguistics (the place parts are shared by languages or dialects in a geographic space) and contact linguistics (the place languages or dialects work together and affect one another). Notably, within the MURAL embedding area, Romanian (ro) is nearer to the Slavic languages like Bulgarian (bg) and Macedonian (mk), which is consistent with the Balkan sprachbund, than it’s in LaBSE. One other potential language contact brings Finnic languages, Estonian (et) and Finnish (fi), nearer to the Slavic languages cluster. The truth that MURAL pivots on pictures in addition to translations seems so as to add a further view on language relatedness as discovered in deep representations, past the language household clustering noticed in a text-only setting.
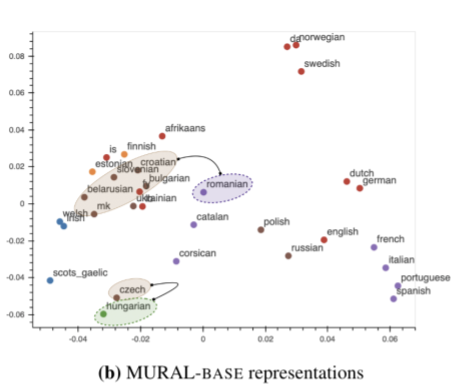 |
| Visualization of textual content representations of MURAL for 35 languages. Colour coding is similar because the determine above. |
Ultimate Remarks
Our findings present that coaching collectively utilizing translation pairs helps overcome the shortage of picture–textual content pairs for a lot of under-resourced languages and improves cross-modal efficiency. Moreover, it’s fascinating to look at hints of areal linguistics and phone linguistics within the textual content representations discovered through the use of a multimodal mannequin. This warrants extra probing into completely different connections discovered implicitly by multimodal fashions, equivalent to MURAL. Lastly, we hope this work promotes additional analysis within the multimodal, multilingual area the place fashions study representations of and connections between languages (expressed by way of pictures and textual content), past well-resourced languages.
Acknowledgements
This analysis is in collaboration with Mandy Guo, Krishna Srinivasan, Ting Chen, Sneha Kudugunta, Chao Jia, and Jason Baldridge. We thank Zarana Parekh, Orhan Firat, Yuqing Chen, Apu Shah, Anosh Raj, Daphne Luong, and others who supplied suggestions for the challenge. We’re additionally grateful for common assist from Google Analysis groups.
[ad_2]