

{kind=link}
[ad_1]
For all the joy about machine studying (ML), there are severe impediments to its widespread adoption. Not least is the broadening realization that ML fashions can fail. And that’s why mannequin debugging, the artwork and science of understanding and fixing issues in ML fashions, is so crucial to the way forward for ML. With out with the ability to troubleshoot fashions after they underperform or misbehave, organizations merely received’t have the ability to undertake and deploy ML at scale.
As a result of all ML fashions make errors, everybody who cares about ML also needs to care about mannequin debugging.[1] This contains C-suite executives, front-line knowledge scientists, and danger, authorized, and compliance personnel. This text is supposed to be a brief, comparatively technical primer on what mannequin debugging is, what you need to learn about it, and the fundamentals of tips on how to debug fashions in follow. These suggestions are primarily based on our expertise, each as a knowledge scientist and as a lawyer, targeted on managing the dangers of deploying ML.

Be taught sooner. Dig deeper. See farther.
What’s mannequin debugging?
Typically ML fashions are simply plain fallacious, however generally they’re fallacious and socially discriminatory, or hacked, or just unethical.[2],[3],[4] Present mannequin evaluation methods, like cross-validation or receiver operator attribute (ROC) and elevate curves, merely don’t inform us about all of the nasty issues that may occur when ML fashions are deployed as a part of massive, advanced, public-facing IT techniques.[5]
That’s the place mannequin debugging is available in. Mannequin debugging is an emergent self-discipline targeted on discovering and fixing issues in ML techniques. Along with newer improvements, the follow borrows from mannequin danger administration, conventional mannequin diagnostics, and software program testing. Mannequin debugging makes an attempt to check ML fashions like code (as a result of they’re often code) and to probe refined ML response capabilities and choice boundaries to detect and proper accuracy, equity, safety, and different issues in ML techniques.[6] Debugging could give attention to a wide range of failure modes (i.e., rather a lot can go fallacious with ML fashions), together with:
- Opaqueness: for a lot of failure modes, it’s essential to perceive what the mannequin is doing in an effort to perceive what went fallacious and tips on how to repair it. Crucially, transparency doesn’t assure reliable fashions. However transparency is often a prerequisite for debugging writ massive.
- Social discrimination: by now, there are lots of broadly publicized incidences of social discrimination in ML. These could cause hurt to the themes of the discriminatory mannequin’s selections and substantial reputational or regulatory harms to the mannequin’s house owners.[7]
- Safety vulnerabilities: adversarial actors can compromise the confidentiality, integrity, or availability of an ML mannequin or the info related to the mannequin, creating a number of undesirable outcomes. The research of safety in ML is a rising subject—and a rising drawback, as we documented in a latest Way forward for Privateness Discussion board report.[8]
- Privateness harms: fashions can compromise particular person privateness in a protracted (and rising) listing of the way.[8] Information about people might be decoded from ML fashions lengthy after they’ve skilled on that knowledge (via what’s often known as inversion or extraction assaults, for instance). Fashions might also violate the privateness of people by inferring delicate attributes from non-sensitive knowledge, amongst different harms.
- Mannequin decay: ML fashions and knowledge pipelines are notoriously “brittle.”[5] This implies surprising enter knowledge or small adjustments over time within the enter knowledge or knowledge pipeline can wreak havoc on a mannequin’s efficiency.
One of the simplest ways to forestall and put together for these sorts of issues is mannequin debugging. We’ll assessment strategies for debugging beneath.
How is debugging carried out at present?
There are at the least 4 main methods for knowledge scientists to search out bugs in ML fashions: sensitivity evaluation, residual evaluation, benchmark fashions, and ML safety audits.
Whereas our evaluation of every methodology could seem technical, we consider that understanding the instruments obtainable, and tips on how to use them, is crucial for all danger administration groups. Anybody, of any technical skill, ought to have the ability to at the least consider using mannequin debugging methods.
Sensitivity evaluation
Sensitivity evaluation, generally referred to as what-if? evaluation, is a mainstay of mannequin debugging. It’s a quite simple and highly effective concept: simulate knowledge that you just discover attention-grabbing and see what a mannequin predicts for that knowledge. As a result of ML fashions can react in very stunning methods to knowledge they’ve by no means seen earlier than, it’s most secure to check all your ML fashions with sensitivity evaluation.[9] Whereas it’s comparatively easy to conduct sensitivity evaluation and not using a formal framework, the What-If Instrument is a good way to begin enjoying with sure sorts of fashions within the TensorFlow household. Extra structured approaches to sensitivity evaluation embrace:
- Adversarial instance searches: this entails systematically trying to find rows of knowledge that evoke unusual or putting responses from an ML mannequin. Determine 1 illustrates an instance adversarial seek for an instance credit score default ML mannequin. In the event you’re utilizing Python and deep studying libraries, the CleverHans and Foolbox packages may make it easier to debug fashions and discover adversarial examples.
- Partial dependence, collected native impact (ALE), and particular person conditional expectation (ICE) plots: this includes systematically visualizing the consequences of adjusting a number of variables in your mannequin. There are a ton of packages for these methods: ALEPlot, DALEX, ICEbox, iml, and pdp in R; and PDPbox and PyCEbox in Python.
- Random assaults: exposing fashions to excessive volumes of random enter knowledge and seeing how they react. Random assaults can reveal every kind of surprising software program and math bugs. In the event you don’t know the place to start debugging an ML system, random assault is a good place to get began.
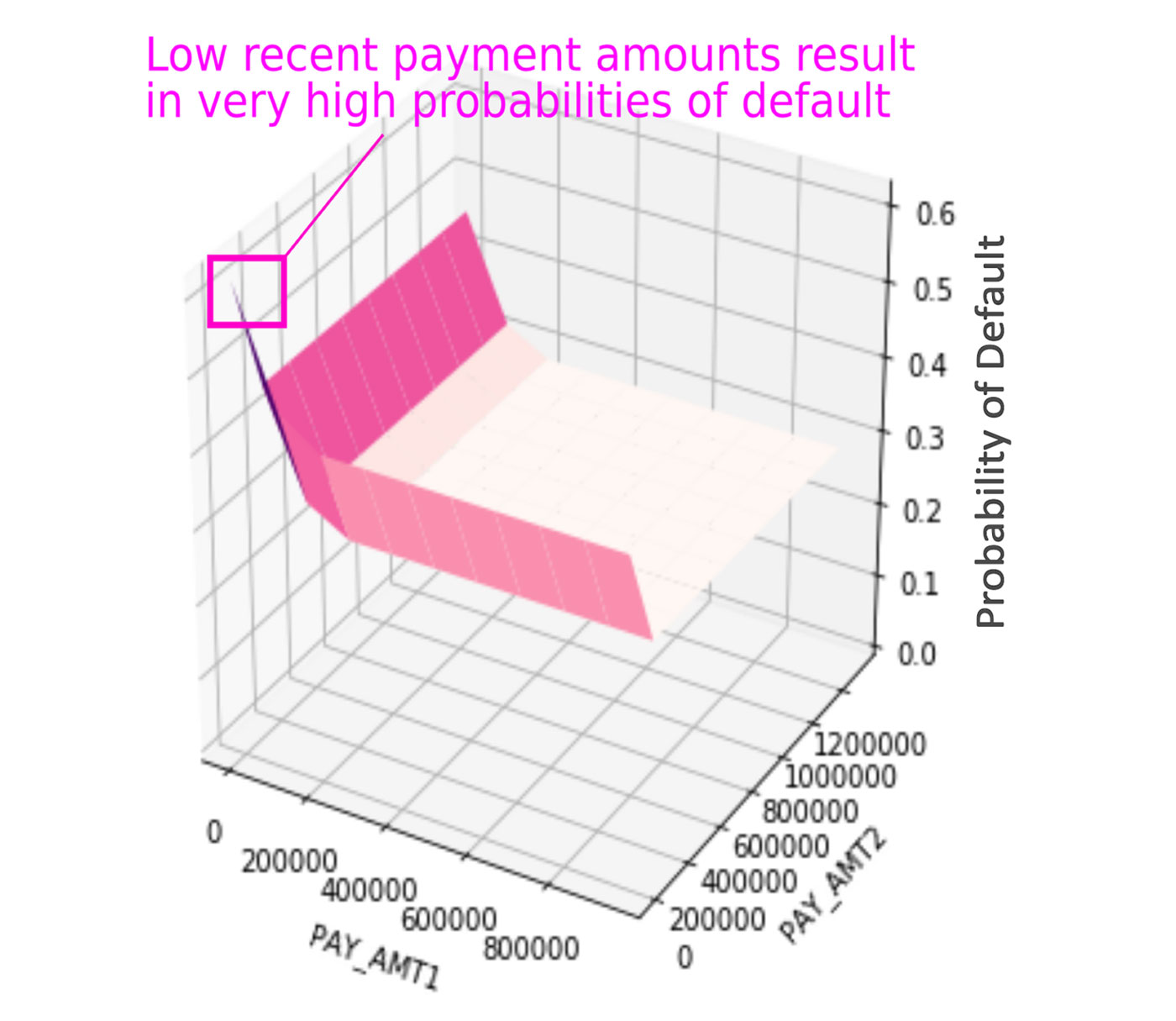
Residual evaluation
Residual evaluation is one other well-known household of mannequin debugging methods. Residuals are a numeric measurement of mannequin errors, primarily the distinction between the mannequin’s prediction and the identified true consequence. Small residuals often imply a mannequin is true, and enormous residuals often imply a mannequin is fallacious. Residual plots place enter knowledge and predictions right into a two-dimensional visualization the place influential outliers, data-quality issues, and different sorts of bugs usually change into plainly seen. The principle disadvantage of residual evaluation is that to calculate residuals, true outcomes are wanted. Meaning it may be onerous to work with residuals in some real-time mannequin monitoring settings, however residual evaluation ought to all the time be doable at mannequin coaching time.
Like in Determine 2, many discrimination detection methods take into account mannequin errors as effectively, particularly throughout completely different demographic teams. This primary bias detection train is usually referred to as disparate affect evaluation.[10] The Gender Shades line of analysis is a good instance of how analyzing errors throughout demographic teams is critical for fashions that have an effect on individuals.[3] There are a myriad of different instruments obtainable for discrimination detection. To be taught extra about testing ML fashions for discrimination, take a look at packages like aequitas, AIF360, Themis, and, extra typically, the content material created by the Equity, Accountability, and Transparency in ML (FATML) group.[11]

Benchmark fashions
Benchmark fashions are trusted, easy, or interpretable fashions to which ML fashions might be in contrast. It’s all the time a good suggestion to verify {that a} new advanced ML mannequin does truly outperform a less complicated benchmark mannequin. As soon as an ML mannequin passes this benchmark check, the benchmark mannequin can function a strong debugging device. Benchmark fashions can be utilized to ask questions like: “what predictions did my ML mannequin get fallacious that my benchmark mannequin bought proper, and why?” Evaluating benchmark mannequin and ML mannequin predictions in actual time may assist to catch accuracy, equity, or safety anomalies as they happen.
ML safety audits
There are a number of identified assaults towards machine studying fashions that may result in altered, dangerous mannequin outcomes or to publicity of delicate coaching knowledge.[8],[12] Once more, conventional mannequin evaluation measures don’t inform us a lot about whether or not a mannequin is safe. Along with different debugging steps, it could be prudent so as to add some or all the identified ML assaults into any white-hat hacking workout routines or red-team audits a corporation is already conducting.
We discovered one thing fallacious; what will we do?
So that you’ve carried out among the systematic methods to search out accuracy, equity, and safety issues in ML-based techniques that we’ve mentioned. You’ve even found a couple of issues together with your ML mannequin. What are you able to do? That’s the place remediation methods are available. We focus on seven remediation methods beneath.
Information augmentation
ML fashions be taught from knowledge to change into correct, and ML fashions require knowledge that’s really consultant of the complete drawback area being modeled. If a mannequin is failing, including consultant knowledge into its coaching set can work wonders. Information augmentation is usually a remediation technique for discrimination in ML fashions, too. One main supply of discrimination in ML is demographically unbalanced coaching knowledge. If a mannequin goes for use on every kind of individuals, it’s greatest to make sure the coaching knowledge has a consultant distribution of every kind of individuals as effectively.
Interpretable ML fashions and explainable ML
The debugging methods we suggest ought to work on nearly any type of ML-based predictive mannequin. However they are going to be simpler to execute on interpretable fashions or with explainable ML. For that reason, and others, we suggest interpretable and explainable ML for high-stakes use circumstances. Fortunately, technological progress has been made towards this finish lately. There are quite a lot of choices for interpretable and correct ML fashions and quite a lot of methods to elucidate and describe them.[13]
Mannequin enhancing
Some ML fashions are designed to be interpretable so it’s attainable to grasp how they work. A few of these fashions, like variants of choice timber or GA2M (i.e., explainable boosting machines) might be immediately editable by human customers. If there’s one thing objectionable within the interior workings of a GA2M mannequin, it’s not very onerous to search out it and alter the ultimate mannequin equation to eliminate it. Different fashions won’t be as simple to edit as GA2M or choice timber, but when they generate human-readable pc code, they are often edited.
Mannequin assertions
Mannequin assertions can enhance or override mannequin predictions in actual time.[14] Mannequin assertions are enterprise guidelines that act on mannequin predictions themselves. Examples might embrace checking the age of a buyer to whom a mannequin recommends promoting alcoholic drinks, or checking for giant prepayments for a prediction that claims a excessive web price particular person is about to default.
Discrimination remediation
There are quite a lot of methods to repair discrimination in ML fashions. Many non-technological options contain selling a range of experience and expertise on knowledge science groups, and guaranteeing numerous intellects are concerned in all levels of mannequin constructing.[15] Organizations ought to, if attainable, require that each one essential knowledge science tasks embrace personnel with experience in ethics, privateness, social sciences, or different associated disciplines.
From a technical perspective, discrimination remediation strategies fall into three main buckets: knowledge pre-processing, mannequin coaching and choice, and prediction post-processing. For pre-processing, cautious function choice, and sampling and reweighing rows to attenuate discrimination in coaching knowledge might be useful.
For mannequin coaching and choice, we suggest contemplating equity metrics when deciding on hyperparameters and choice cutoff thresholds. This will likely additionally contain coaching honest fashions immediately by studying honest representations (LFR) and adversarial debiasing in AIF360, or utilizing twin goal capabilities that take into account each accuracy and equity metrics. Final, for prediction post-processing, altering mannequin predictions after coaching, like reject-option classification in AIF360 or Themis ML, may assist to cut back undesirable bias.
Mannequin monitoring
Mannequin debugging will not be a one-and-done activity. The accuracy, equity, or safety traits of ML fashions should not static. They’ll change considerably over time primarily based on the mannequin’s working surroundings. We suggest monitoring ML fashions for accuracy, equity, and safety issues at common time intervals as soon as they’re deployed.
Anomaly detection
Unusual, anomalous enter and prediction values are all the time worrisome in ML, and might be indicative of an adversarial assault on an ML mannequin. Fortunately, anomalous inputs and predictions might be caught and corrected in actual time utilizing a wide range of instruments and methods: knowledge integrity constraints on enter knowledge streams, statistical course of management methodologies on inputs and predictions, anomaly detection via autoencoders and isolation forests, and likewise by evaluating ML predictions to benchmark mannequin predictions.
Conclusion and additional studying
Everybody desires reliable ML fashions. And that implies that as ML is extra broadly adopted, the significance of mannequin debugging will solely improve over time. That holds true for everybody from Kagglers to front-line knowledge scientists to authorized and danger administration personnel and for ML shoppers and choice topics. These excited about extra particulars can dig deeper into the code on GitHub used to create the examples on this submit.[16] Or, you may be taught extra about mannequin debugging within the ML analysis group by testing the 2019 Worldwide Convention on Studying Representations (ICLR) Debugging Machine Studying Fashions workshop proceedings.[17] Hopefully a few of these methods will give you the results you want and your group. If that’s the case, have enjoyable debugging!
[ad_2]