

{kind=link}
[ad_1]
In a world centered on buzzword-driven fashions and algorithms, you’d be forgiven for forgetting in regards to the unreasonable significance of information preparation and high quality: your fashions are solely nearly as good as the information you feed them. That is the rubbish in, rubbish out precept: flawed information getting into results in flawed outcomes, algorithms, and enterprise choices. If a self-driving automobile’s decision-making algorithm is educated on information of site visitors collected through the day, you wouldn’t put it on the roads at evening. To take it a step additional, if such an algorithm is educated in an atmosphere with automobiles pushed by people, how are you going to count on it to carry out nicely on roads with different self-driving automobiles? Past the autonomous driving instance described, the “rubbish in” facet of the equation can take many varieties—for instance, incorrectly entered information, poorly packaged information, and information collected incorrectly, extra of which we’ll deal with beneath.
When executives ask me tips on how to strategy an AI transformation, I present them Monica Rogati’s AI Hierarchy of Wants, which has AI on the high, and every little thing is constructed upon the inspiration of information (Rogati is an information science and AI advisor, former VP of information at Jawbone, and former LinkedIn information scientist):

Be taught sooner. Dig deeper. See farther.
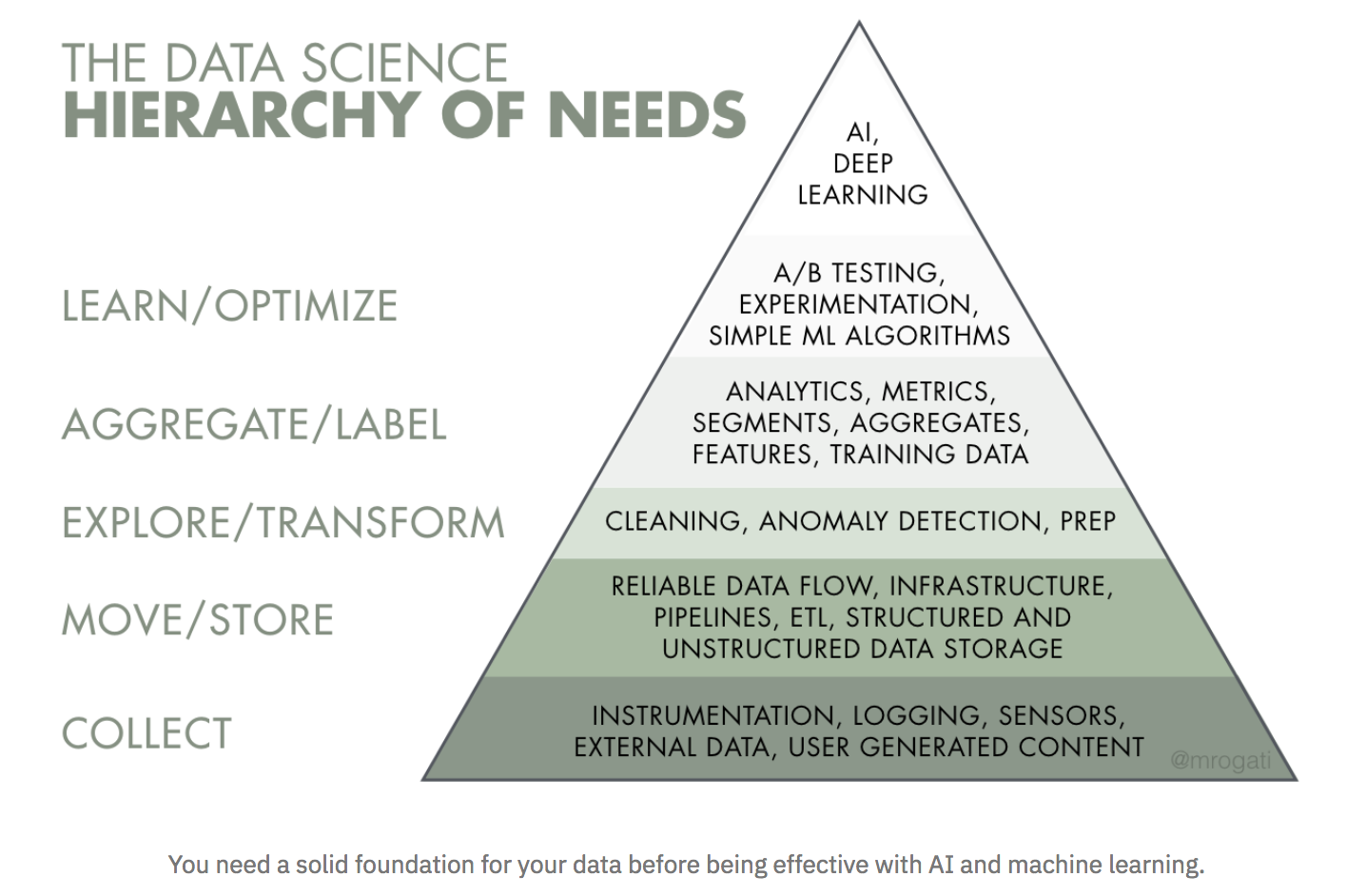
Why is high-quality and accessible information foundational? If you happen to’re basing enterprise choices on dashboards or the outcomes of on-line experiments, you have to have the correct information. On the machine studying facet, we’re coming into what Andrei Karpathy, director of AI at Tesla, dubs the Software program 2.0 period, a brand new paradigm for software program the place machine studying and AI require much less give attention to writing code and extra on configuring, choosing inputs, and iterating by information to create greater stage fashions that study from the information we give them. On this new world, information has turn into a first-class citizen, the place computation turns into more and more probabilistic and applications now not do the identical factor every time they run. The mannequin and the information specification turn into extra essential than the code.
Gathering the correct information requires a principled strategy that could be a operate of your corporation query. Information collected for one function can have restricted use for different questions. The assumed worth of information is a fantasy resulting in inflated valuations of start-ups capturing stated information. John Myles White, information scientist and engineering supervisor at Fb, wrote: “The largest threat I see with information science tasks is that analyzing information per se is usually a foul factor. Producing information with a pre-specified evaluation plan and working that evaluation is sweet. Re-analyzing current information is commonly very unhealthy.” John is drawing consideration to pondering fastidiously about what you hope to get out of the information, what query you hope to reply, what biases could exist, and what you have to appropriate earlier than leaping in with an evaluation[1]. With the correct mindset, you may get rather a lot out of analyzing current information—for instance, descriptive information is commonly fairly helpful for early-stage corporations[2].
Not too way back, “save every little thing” was a standard maxim in tech; you by no means knew if you happen to may want the information. Nevertheless, making an attempt to repurpose pre-existing information can muddy the water by shifting the semantics from why the information was collected to the query you hope to reply. Particularly, figuring out causation from correlation may be tough. For instance, a pre-existing correlation pulled from a corporation’s database must be examined in a brand new experiment and never assumed to suggest causation[3], as a substitute of this generally encountered sample in tech:
- A big fraction of customers that do X do Z
- Z is sweet
- Let’s get everyone to do X
Correlation in current information is proof for causation that then must be verified by amassing extra information.
The identical problem plagues scientific analysis. Take the case of Brian Wansink, former head of the Meals and Model Lab at Cornell College, who stepped down after a Cornell school evaluate reported he “dedicated tutorial misconduct in his analysis and scholarship, together with misreporting of analysis information, problematic statistical strategies [and] failure to correctly doc and protect analysis outcomes.” One in all his extra egregious errors was to repeatedly check already collected information for brand spanking new hypotheses till one caught, after his preliminary speculation failed[4]. NPR put it nicely: “the gold customary of scientific research is to make a single speculation, collect information to check it, and analyze the outcomes to see if it holds up. By Wansink’s personal admission within the weblog submit, that’s not what occurred in his lab.” He regularly tried to suit new hypotheses unrelated to why he collected the information till he received a null speculation with a suitable p-value—a perversion of the scientific technique.
Information professionals spend an inordinate quantity on time cleansing, repairing, and getting ready information
Earlier than you even take into consideration refined modeling, state-of-the-art machine studying, and AI, you have to make certain your information is prepared for evaluation—that is the realm of information preparation. Chances are you’ll image information scientists constructing machine studying fashions all day, however the widespread trope that they spend 80% of their time on information preparation is nearer to the reality.

That is outdated information in some ways, however it’s outdated information that also plagues us: a current O’Reilly survey discovered that lack of information or information high quality points was one of many important bottlenecks for additional AI adoption for corporations on the AI analysis stage and was the important bottleneck for corporations with mature AI practices.
Good high quality datasets are all alike, however each low-quality dataset is low-quality in its personal means[5]. Information may be low-quality if:
- It doesn’t suit your query or its assortment wasn’t fastidiously thought-about;
- It’s misguided (it could say “cicago” for a location), inconsistent (it could say “cicago” in a single place and “Chicago” in one other), or lacking;
- It’s good information however packaged in an atrocious means—e.g., it’s saved throughout a spread of siloed databases in a corporation;
- It requires human labeling to be helpful (akin to manually labeling emails as “spam” or “not” for a spam detection algorithm).
This definition of low-quality information defines high quality as a operate of how a lot work is required to get the information into an analysis-ready kind. Have a look at the responses to my tweet for information high quality nightmares that trendy information professionals grapple with.
The significance of automating information preparation
A lot of the dialog round AI automation entails automating machine studying fashions, a discipline generally known as AutoML. That is essential: contemplate what number of trendy fashions have to function at scale and in actual time (akin to Google’s search engine and the related tweets that Twitter surfaces in your feed). We additionally must be speaking about automation of all steps within the information science workflow/pipeline, together with these in the beginning. Why is it essential to automate information preparation?
- It occupies an inordinate period of time for information professionals. Information drudgery automation within the period of information smog will free information scientists up for doing extra attention-grabbing, inventive work (akin to modeling or interfacing with enterprise questions and insights). “76% of information scientists view information preparation because the least satisfying a part of their work,” based on a CrowdFlower survey.
- A collection of subjective information preparation micro-decisions can bias your evaluation. For instance, one analyst could throw out information with lacking values, one other could infer the lacking values. For extra on how micro-decisions in evaluation can impression outcomes, I like to recommend Many Analysts, One Information Set: Making Clear How Variations in Analytic Decisions Have an effect on Outcomes[6] (be aware that the analytical micro-decisions on this research usually are not solely information preparation choices). Automating information preparation received’t essentially take away such bias, however it’ll make it systematic, discoverable, auditable, unit-testable, and correctable. Mannequin outcomes will then be much less reliant on people making a whole lot of micro-decisions. An additional advantage is that the work will likely be reproducible and strong, within the sense that someone else (say, in one other division) can reproduce the evaluation and get the identical outcomes[7];
- For the rising variety of real-time algorithms in manufacturing, people must be taken out of the loop at runtime as a lot as attainable (and maybe be saved within the loop extra as algorithmic managers): if you use Siri to make a reservation on OpenTable by asking for a desk for 4 at a close-by Italian restaurant tonight, there’s a speech-to-text mannequin, a geographic search mannequin, and a restaurant-matching mannequin, all working collectively in actual time. No information analysts/scientists work on this information pipeline as every little thing should occur in actual time, requiring an automatic information preparation and information high quality workflow (e.g., to resolve if I say “eye-talian” as a substitute of “it-atian”).
The third level above speaks extra typically to the necessity for automation round all components of the information science workflow. This want will develop as good units, IoT, voice assistants, drones, and augmented and digital actuality turn into extra prevalent.
Automation represents a particular case of democratization, making information expertise simply accessible for the broader inhabitants. Democratization entails each schooling (which I give attention to in my work at DataCamp) and creating instruments that many individuals can use.
Understanding the significance of common automation and democratization of all components of the DS/ML/AI workflow, it’s essential to acknowledge that we’ve carried out fairly nicely at democratizing information assortment and gathering, modeling[8], and information reporting[9], however what stays stubbornly tough is the entire strategy of getting ready the information.
Fashionable instruments for automating information cleansing and information preparation
We’re seeing the emergence of contemporary instruments for automated information cleansing and preparation, akin to HoloClean and Snorkel coming from Christopher Ré’s group at Stanford. HoloClean decouples the duty of information cleansing into error detection (akin to recognizing that the placement “cicago” is misguided) and repairing misguided information (akin to altering “cicago” to “Chicago”), and formalizes the truth that “information cleansing is a statistical studying and inference downside.” All information evaluation and information science work is a mix of information, assumptions, and prior information. So if you’re lacking information or have “low-quality information,” you utilize assumptions, statistics, and inference to restore your information. HoloClean performs this routinely in a principled, statistical method. All of the person must do is “to specify high-level assertions that seize their area experience with respect to invariants that the enter information must fulfill. No different supervision is required!”
The HoloClean staff additionally has a system for automating the “constructing and managing [of] coaching datasets with out guide labeling” known as Snorkel. Having appropriately labeled information is a key a part of getting ready information to construct machine studying fashions[10]. As increasingly information is generated, manually labeling it’s unfeasible. Snorkel gives a method to automate labeling, utilizing a contemporary paradigm known as information programming, during which customers are in a position to “inject area data [or heuristics] into machine studying fashions in greater stage, greater bandwidth methods than manually labeling hundreds or tens of millions of particular person information factors.” Researchers at Google AI have tailored Snorkel to label information at industrial/net scale and demonstrated its utility in three eventualities: subject classification, product classification, and real-time occasion classification.
Snorkel doesn’t cease at information labeling. It additionally lets you automate two different key elements of information preparation:
- Information augmentation—that’s, creating extra labeled information. Contemplate a picture recognition downside during which you are attempting to detect automobiles in pictures on your self-driving automobile algorithm. Classically, you’ll want no less than a number of thousand labeled pictures on your coaching dataset. If you happen to don’t have sufficient coaching information and it’s too costly to manually acquire and label extra information, you may create extra by rotating and reflecting your photographs.
- Discovery of essential information subsets—for instance, determining which subsets of your information actually assist to differentiate spam from non-spam.
These are two of many present examples of the augmented information preparation revolution, which incorporates merchandise from IBM and DataRobot.
The way forward for information tooling and information preparation as a cultural problem
So what does the long run maintain? In a world with an rising variety of fashions and algorithms in manufacturing, studying from massive quantities of real-time streaming information, we want each schooling and tooling/merchandise for area consultants to construct, work together with, and audit the related information pipelines.
We’ve seen a variety of headway made in democratizing and automating information assortment and constructing fashions. Simply take a look at the emergence of drag-and-drop instruments for machine studying workflows popping out of Google and Microsoft. As we noticed from the current O’Reilly survey, information preparation and cleansing nonetheless take up a variety of time that information professionals don’t get pleasure from. For that reason, it’s thrilling that we’re now beginning to see headway in automated tooling for information cleansing and preparation. It will likely be attention-grabbing to see how this house grows and the way the instruments are adopted.
A vibrant future would see information preparation and information high quality as first-class residents within the information workflow, alongside machine studying, deep studying, and AI. Coping with incorrect or lacking information is unglamorous however obligatory work. It’s simple to justify working with information that’s clearly unsuitable; the one actual shock is the period of time it takes. Understanding tips on how to handle extra refined issues with information, akin to information that displays and perpetuates historic biases (for instance, actual property redlining) is a harder organizational problem. It will require trustworthy, open conversations in any group round what information workflows really appear like.
The truth that enterprise leaders are centered on predictive fashions and deep studying whereas information staff spend most of their time on information preparation is a cultural problem, not a technical one. If this a part of the information circulate pipeline goes to be solved sooner or later, everyone must acknowledge and perceive the problem.
Many due to Angela Bassa, Angela Bowne, Vicki Boykis, Joyce Chung, Mike Loukides, Mikhail Popov, and Emily Robinson for his or her priceless and demanding suggestions on drafts of this essay alongside the way in which.
[ad_2]