

{kind=link}
[ad_1]
Computerized speech recognition (ASR) has been intertwined with machine studying (ML) for the reason that early Fifties, however fashionable synthetic intelligence (AI) strategies—comparable to deep studying and transformer-based architectures—have revolutionized the sector. Consequently, automated speech recognition has developed from an costly area of interest know-how into an accessible, near-ubiquitous service. Medical, authorized, and customer support suppliers have relied on ASR to seize correct information for a few years. Now thousands and thousands of executives, content material creators, and customers additionally use it to take assembly notes, generate transcripts, or management smart-home gadgets. In 2023, the worldwide marketplace for speech and automated speech recognition know-how was valued at $12.6 billion—with progress anticipated to achieve almost $85 billion by 2032.
On this roundtable dialogue, two Toptal specialists discover the influence that the speedy enchancment in AI know-how has had on automated speech recognition. Alessandro Pedori is an AI developer, engineer, and marketing consultant with full-stack expertise in machine studying, pure language processing (NLP), and deep neural networks who has used speech-to-text know-how in purposes for transcribing and extracting actionable objects from voice messages, in addition to a co-pilot system for group facilitation and 1:1 teaching. Necati Demir, PhD, is a pc scientist, AI engineer, and AWS Licensed Machine Studying Specialist with current expertise implementing a video summarization system that makes use of state-of-the-art deep studying strategies.
This dialog has been edited for readability and size.
Exploring How Computerized Speech Recognition Works
First we delve into the small print of how automated speech recognition works below the hood, together with system architectures and customary algorithms, after which we focus on the trade-offs between completely different speech recognition methods.
What’s automated speech recognition (ASR)?
Demir: The fundamental performance of ASR might be defined in only one sentence: It’s used to translate spoken phrases into textual content.
Once we discuss, sound waves containing layers of frequencies are produced. In ASR, we obtain this audio data as enter and convert it into sequences of numbers, a format that machine studying fashions perceive. These numbers can then be transformed into the required end result, which is textual content.
Pedori: If you happen to’ve ever heard a international language being spoken, it doesn’t sound prefer it comprises separate phrases—it simply strikes you as an unbroken wall of sound. Fashionable ASR methods are educated to take this wall of sound waves (within the type of wave information) and extrapolate the phrases from it.
Demir: One other essential factor is that the purpose of automated speech recognition is to not perceive the intent of human speech itself. The purpose is simply to transform the information, or, in different phrases, to rework the speech into textual content. To make use of that knowledge in every other means, a separate, devoted system must be built-in with the ASR mannequin.
What’s voice recognition, and the way is it completely different from ASR?
Pedori: “Voice recognition” is a reasonably obscure time period. It’s usually used to imply “speaker identification,” or the verification of who’s at the moment talking by matching a sure voice to a selected particular person.
We even have voice detection, which consists of with the ability to inform whether or not a sure voice is talking. Think about a scenario the place you may have an audio recording with a number of audio system, however the particular person related to your venture is simply talking for five% of the time. On this case, you’d first run voice detection, which is commonly extra reasonably priced than ASR, on all the recording. Afterward, you’d use ASR to concentrate on the a part of the audio recording that you could examine; on this instance, that may be the chunks of dialog spoken by the related particular person.
The primary utility of voice recognition in audio transcription known as “diarization.” Let’s say we’ve a speaker named John. When analyzing an audio recording, diarization identifies and isolates John’s voice from different voices, segmenting the audio into sections based mostly on who’s talking at any given second.
Principally, voice recognition and ASR differ in how they deal with accents. In ASR, to know the phrases, you typically wish to ignore accents. In voice recognition, nonetheless, accents are an awesome asset: The stronger the accent your speaker has, the better they’re to determine.
One phrase of warning: Voice recognition is usually a cost-effective, invaluable instrument to make use of when analyzing speech, however it has limitations. For the time being, it’s changing into more and more simple to clone voices with the assistance of AI. You need to most likely be cautious of utilizing voice recognition in privacy-sensitive environments. For instance, chorus from utilizing voice recognition as a technique of official identification.
Demir: One other limitation that may current itself is when your recording comprises the voices of a number of folks speaking in a loud or casual setting. Voice recognition may show to be tougher in that scenario. For instance, this dialog we’re having wouldn’t be a main instance of unpolluted knowledge when in comparison with somebody recording an e-book in knowledgeable studio setting. This downside exists for ASR methods as properly. Nonetheless, if we’re speaking about voice detection, wake phrases or easy voice instructions—comparable to “Hey Siri”—are easier for the software program to know even in noisy acoustic environments.
How do ML fashions match into the ASR course of?
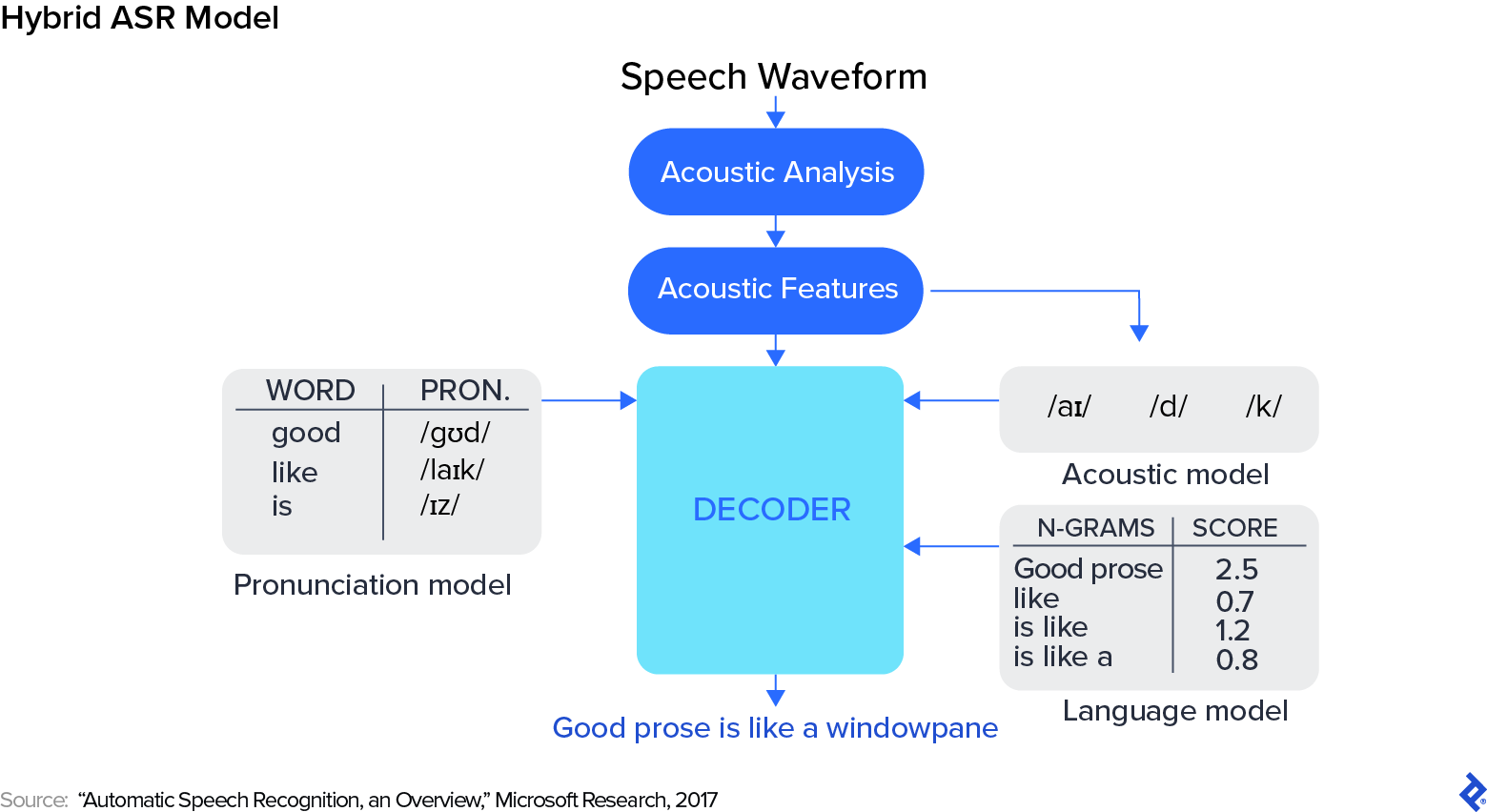
Demir: If we wished to, we might roughly break up the historical past of speech recognition into two phases: earlier than and after the arrival of deep studying. Earlier than deep studying, the researcher’s job was to determine the proper options in speech. There have been three steps: preprocessing the information, constructing a statistical mannequin, and postprocessing the mannequin’s output.
On the preprocessing stage, options are extracted from sound waves and transformed into numbers based mostly on handcrafted guidelines. After preprocessing is full, you may match the ensuing numbers right into a hidden Markov mannequin, which is able to try to predict every phrase. However right here’s the trick: Earlier than deep studying, we didn’t attempt to predict the phrase itself. We tried to foretell phonemes—the best way a phrase is pronounced. Take, as an example, the phrase “5”: That’s one phrase, however the best way it’s pronounced sounds one thing like “F-AY-V.” The system would predict these phonemes and attempt to convert them into the proper phrases.
Inside a hybrid system, three respective submodels deal with these three steps. The acoustic mannequin is in search of and attempting to foretell phonemes. The pronunciation mannequin takes the phonemes and predicts which phrases they need to match as much as. Lastly, the language mannequin—often an n-gram mannequin—makes one other prediction by grouping textual content into chunks to make sure the textual content is a statistical match. For instance, “a bear within the woods” is prone to be the proper grouping of phrases, versus the phrase “a naked within the woods,” which is statistically much less possible.
Which AI-powered automated speech recognition instruments do you discover helpful?
Demir: Relating to ASR instruments, OpenAI’s Whisper mannequin is widely known for its reliability. This single mannequin is able to precisely transcribing quite a lot of speech patterns and accents, even in noisy environments. Hugging Face, an organization and open-source group that contributes enormously to machine studying, supplies quite a lot of open-source machine studying fashions for speech recognition, considered one of which is Distil-Whisper. This mannequin is a standout instance of a high-quality system applied with deep neural networks. Distil-Whisper is predicated on the Whisper mannequin, and it maintains strong efficiency regardless of being significantly lighter. It’s an awesome alternative for builders working with smaller datasets.
Pedori: Hugging Face has greater than 16,000 fashions coping with some type of automated speech recognition. And Whisper itself might be run in actual time, regionally, and whilst an API. You’ll be able to even run Whisper in WebAssembly.
ASR developed from a really difficult system to implement into one thing easier—extra like optical character recognition (OCR). I don’t wish to say it’s a stroll within the park, however a developer can now count on a minimum of 95% precision of their outcomes except the audio could be very noisy or the audio system have very heavy accents. And except you may have considerably constrained sources, most ASR necessities might be successfully addressed with deep studying. The present transformer-based fashions are dominating the business.
Within the deep studying period, nonetheless, the method is “finish to finish”: We enter sound waves at one finish, and obtain the phrases—technically, “tokens”—on the different finish. In an end-to-end mannequin like Whisper, characteristic extraction isn’t achieved anymore. We’re simply getting the waveform from the acoustic evaluation, feeding it to the mannequin, and anticipating the mannequin to extract the acoustic options from the information itself, later making a prediction based mostly on these outcomes.
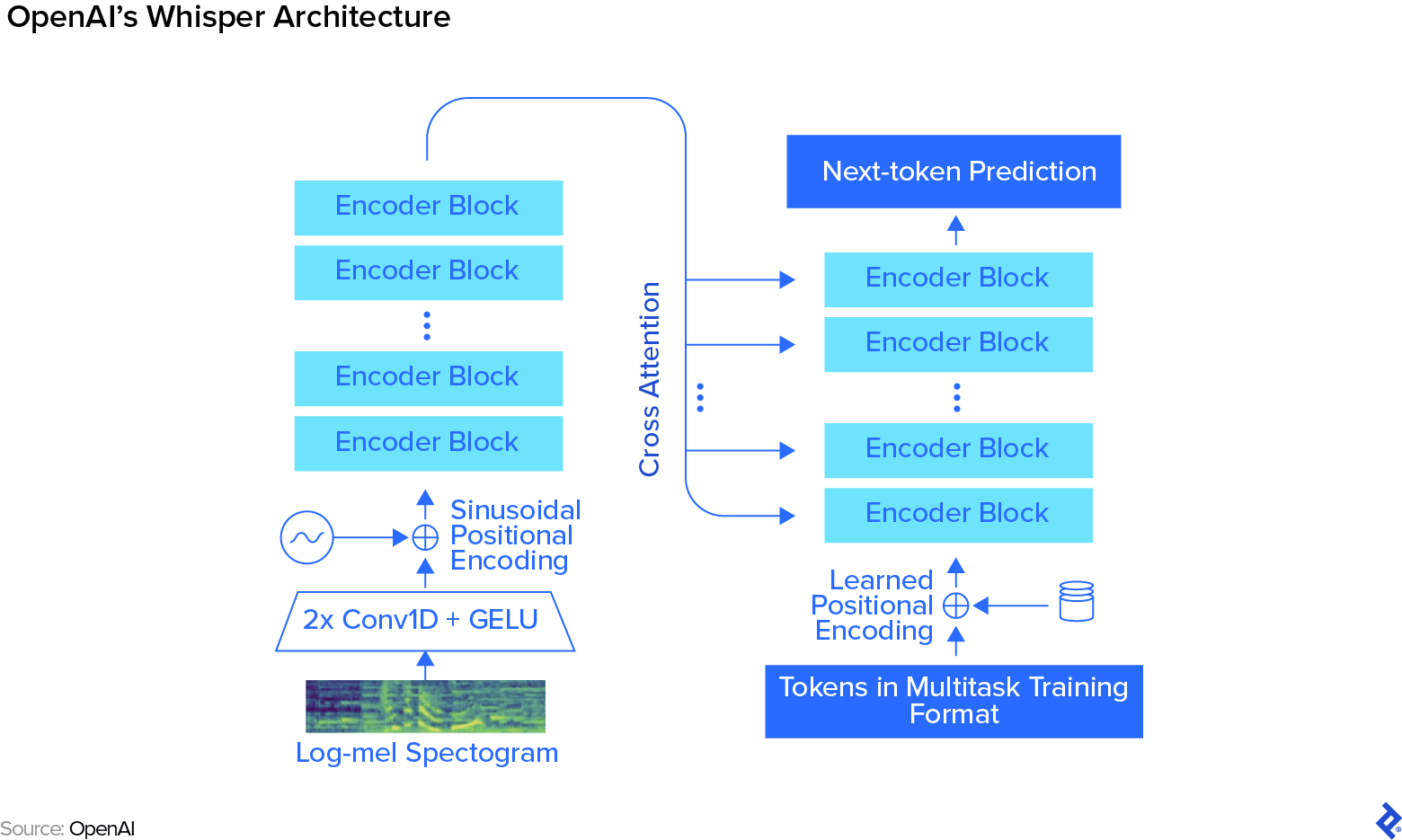
Pedori: With an end-to-end mannequin, every little thing occurs as if it’s inside a magic field that was educated by being fed a large quantity of coaching knowledge; in Whisper’s case, it’s 680,000 hours of audio. First, the audio knowledge is transformed right into a log-mel spectrogram—a diagram that represents the audio’s frequency spectrum over time—utilizing acoustic processing. That’s the toughest half for the developer—every little thing else occurs contained in the neural community. At its core, it’s a transformer mannequin with completely different blocks of consideration.
Most individuals simply use the mannequin as a black field that you could go audio to, understanding that you just’ll obtain phrases on the opposite finish. It often performs very properly, nonetheless, being a black field, it may be just a little tougher to right the system when it doesn’t, requiring further tinkering that may be time-consuming.
What AI algorithms do you like to your work with ASR today?
Pedori: Whisper from OpenAI and NeMo from Nvidia are each transformer-based fashions which can be among the many hottest instruments in the marketplace. The sort of algorithm has revolutionized the sector, making pure language processing much more agile. Prior to now, deep studying strategies for ASR concerned lengthy short-term reminiscence (LSTM) recurrent neural networks, in addition to convolutional neural networks. These carried out admirably, nonetheless, transformers are state-of-the-art. They’re very simple to parallelize, so you may feed them an enormous quantity of information and they’re going to scale seamlessly.
Demir: That’s an essential motive why we’ve primarily centered on Whisper on this dialog. It’s not the one transformer accessible, after all. What makes Whisper completely different is the best way it handles enormous quantities of imperfect, weakly supervised knowledge; for Whisper, 680,000 hours is the equal of 78 years price of spoken voice, all of it fed into the system without delay. After getting the mannequin educated, you may enhance its accuracy by loading pre-trained weights and fine-tuning the community. High quality-tuning is the method of additional coaching a mannequin relying on what conduct you wish to see because of this—for instance, you would customise your mannequin to boost precision for terminologies inside a sure sector, or optimize it for a selected language.
What options are essential for high-performing automated speech recognition methods?
Pedori: Given a selected ASR system, the primary “knobs” we’ve to regulate are phrase error price (WER) along with the dimensions and pace of the mannequin. Usually, an even bigger mannequin might be slower than a smaller one. That is virtually the identical for each machine studying system. Not often is a system correct, cheap, and quick; you may usually obtain two of those qualities, however seldom all three.
You’ll be able to resolve should you’re going to run your ASR system regionally or by way of API, after which get one of the best WER you may for that configuration. Or you may outline a WER for an utility upfront after which attempt to get the mannequin that’s the greatest match for the job. Typically, you may need to intention for “adequate,” as a result of discovering one of the best strategy takes a number of engineering time.
How have current advances in AI affected these key options?
Pedori: Transformer-based fashions present pre-trained blocks which can be fairly “good” and extra resilient to background noise, however they’re tougher to regulate and fewer customizable. Total, AI has made it a lot simpler to implement ASR, as a result of fashions like Whisper and NeMo work fairly properly out of the field. By now, they will obtain nearly real-time correct transcriptions on a conveyable system, relying on the specified WER and the presence of accents within the speech.
Present Use Instances and the Way forward for ASR
Now let’s focus on the present and future purposes of automated speech recognition in numerous sectors, together with challenges that have to be overcome.
What industries are being revolutionized by ASR?
Pedori: ASR has made it a lot simpler to work together with gadgets and companies by way of voice—in contrast to the extra fitful experiences of yore, the place it was vital to provide a verbal audio sign to instruct the system to take one step, then comply with up with a second sign to inform it to take one other. ASR has typically opened audio as much as most pure language processing strategies. From a consumer or buyer expertise perspective, this implies you may combine speech recognition capabilities into your workflows, getting transcripts of your physician visits or simply changing voicemails into textual content messages.
Audio-based automated transcription is changing into extraordinarily widespread—consider authorized transcription and documentation, on-line programs, content material creation in media and leisure, and customer support, to call a number of makes use of. However ASR is excess of only a transcription instrument. Voice assistants have gotten a part of our day-to-day lives, and safety know-how is advancing by integrating voice biometrics for authentication. Computerized speech recognition additionally helps accessibility by offering subtitles and voice consumer interfaces for people with disabilities.
People usually wish to work together by way of using their voices. Along with massive language fashions, we will now perceive a consumer’s voice fairly properly.
What present challenges do builders face in automated speech recognition know-how, and the way are they being addressed?
Pedori: If the essential end-to-end system works to your use case out of the field, you may put one thing collectively for a consumer in a number of days or perhaps a few hours. However the second an end-to-end system is inadequate and it’s a must to tinker with it, then the necessity to spend a few months accumulating knowledge and doing coaching runs arises. That’s primarily as a result of the fashions are fairly huge. An answer for this hang-up is “information distillation,” which is a means of eradicating the components of the mannequin that you just don’t want with out dropping efficiency, often known as teacher-student coaching.
Demir: Throughout distillation a brand new, smaller community (the “pupil” mannequin) tries to be taught from the unique, extra advanced mannequin (the “trainer”). This enables for a extra nimble mannequin that gleans data instantly from the unique and makes the method extra reasonably priced with out lack of efficiency. It’s comparable in a method to a researcher spending years studying a few specific subject after which instructing what they’ve realized to the scholars at school in a matter of hours. The scholar mannequin is educated utilizing predictions gathered from the trainer mannequin. This coaching knowledge, or “information,” teaches the coed mannequin to behave in a way just like that of the trainer mannequin. We optimize the coed mannequin by handing the identical audio enter and output to each fashions after which measuring the efficiency distinction between them.
Pedori: One other technical problem is accent independence. When Whisper was launched, the very first thing I did was make a Telegram bot that transcribed lengthy audio messages, as a result of I favor having messages in textual content type reasonably than listening to them. The issue was that the bot’s efficiency various enormously relying on whether or not the sender spoke English natively or as a second language. With a local English speaker, the transcription was good. When it was me or my worldwide mates talking, the bot turned just a little “imaginative.”
What developments on this discipline are you most enthusiastic about?
Demir: I’m excited to see smaller ASR fashions with comparable efficiency metrics. It’d be thrilling to see one thing like a one-megabyte mannequin. As we talked about, we’re “compressing” the fashions with distillation already. So it’ll be superb to see how far we will go by progressively compressing an enormous quantity of data into a number of weights throughout the community.
Pedori: I additionally stay up for higher diarization—higher attribution of who’s talking—as a result of that’s a blocker in a few of my initiatives. However the largest factor on my want listing can be having an ASR system that may do on-line studying: a system that might self-teach to know a selected accent, for instance. I can’t see that taking place with present architectures, although, as a result of the coaching and inference—the steps the place the mannequin applies what it has realized throughout coaching—phases are very separate.
Demir: The world of machine studying appears to be very unpredictable. We’re speaking about transformers proper now, however that structure didn’t even exist after I began my PhD in 2010. The world is altering and adapting in a short time, so it’s onerous to foretell what sort of new and thrilling architectures could be developing on the horizon.
The technical content material offered on this article was reviewed by Nabeel Raza.
[ad_2]