

{kind=link}
[ad_1]
This can be a collaborative publish from Bread Finance and Databricks. We thank co-author Christina Taylor, Senior Knowledge Engineer–Bread Finance, for her contribution.
Bread, a division of Alliance Knowledge Methods, is a technology-driven funds firm that integrates with retailers and companions to personalize cost choices for his or her clients. The Bread platform permits retailers to supply extra methods to pay over time, serving up the suitable choices on the proper time, empowering retailers to enhance conversion charges and elevate average-order-value. Bread at the moment providers over 400 retailers — notably GameStop (Canada), SoulCycle, and Equinox (US) — and continues to develop. The platform is pushed by massive information use circumstances similar to monetary reporting, fraud detection, credit score danger, loss estimation and a full-funnel suggestion engine.
The Bread platform, operating on Amazon Internet Companies (AWS) Cloud, consists of a number of dozen microservices. Every microservice represents part of a consumer or service provider’s journey, for instance: A buyer selects a cost possibility or applies for a mortgage; a service provider manages the transaction lifecycle or tracks settlement particulars. Each microservice writes to its personal Postgres database, and the databases are remoted from one another by design. For inner enterprise evaluation and exterior partnership reporting, we want a centralized repository the place all information from totally different providers come collectively for the primary time.
Present implementation
Our first iteration of ingestion was a knowledge sync Python module that dumped all databases and tables nightly as CSV information, copied the information into Snowflake warehouse’s uncooked schema, and overwrote present tables each night time. We then used dbt (Knowledge Construct Instrument) and a customized decryption module — additionally run as python containers — to rework the information and make them reporting prepared. See the diagram under.
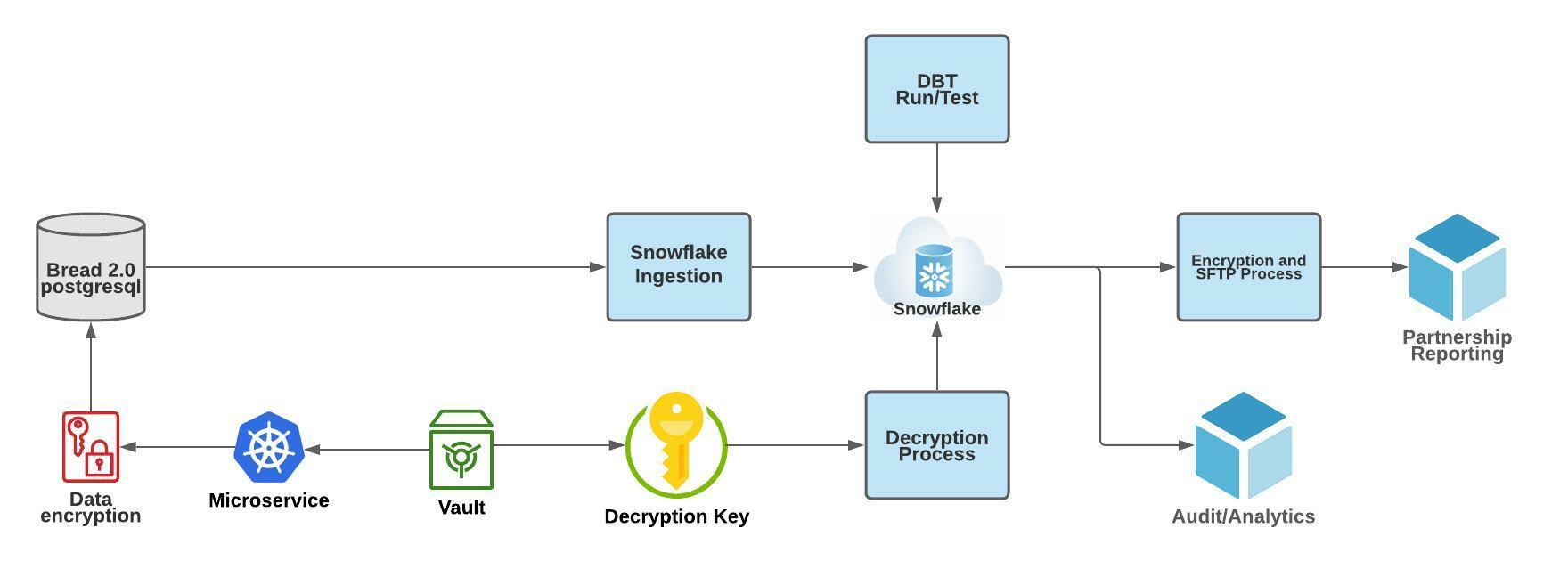
Challenges
Whereas the above ingestion workflow efficiently enabled reporting, there have been just a few important challenges. Essentially the most urgent one was scalability. Our Python module was run by a KubernetesPodOperator on an Airflow cluster in our AWS Cloud. It was subjected to the compute assets (~1GB CPU, ~500 MB reminiscence; 3 occasions the default) allotted to the pod, and general additional capability provisioned by the Airflow cluster. As whole information quantity grew from Gigabytes to Terabytes, the time it took to run the information sync job in a single deployment had additionally grown from minutes to hours, straining pod assets and creating latency for downstream information transformation. We would have liked a greater answer that might scale with our enterprise because the variety of transactions and companions will increase.
The second problem was schema evolution. Microservices proceed to evolve and schema adjustments can happen each week. Whereas we might “routinely” reply by dropping and recreating the tables in Snowflake, we had neither information of the change nor time to replace the downstream information fashions. In consequence, the transformation jobs usually error on schema change. We would have liked an answer that might warn us of schema adjustments and was extra fault-tolerant.
The final problem was velocity. As our crew and utilization each grew, there was an growing want for well timed ingestion. Whereas Day -1 updates could also be adequate for reporting, inner BI functionalities — particularly danger and fraud analytics — required contemporary information from our purposes. We would have liked an answer that gives close to real-time information.
Proposal
To summarize, we would have liked a platform to offer:
- Scalable computing unbiased of reminiscence restrictions of kubernetes pods
- Storage possibility which provided easy however secure schema evolution
- Capability to transition from batch to streaming with one-line code adjustments
Thankfully, Delta Lake operating on Databricks supplied the answer to all the above. We got down to construct 1) A proper change information seize course of as a substitute of naive information dump, 2) Apache SparkTM as a substitute of Python modules for ingestion, and three) Databricks as a substitute of Snowflake for computing. We additionally needed to proceed supporting information fashions and customers on Snowflake, till we might absolutely migrate to Databricks.
Lakehouse for a transaction enrichment pipeline
The imaginative and prescient of a lakehouse is to ship on the enterprise use circumstances described within the first paragraph on this article. The secret is to set a basis in Delta Lake, empowering information science and analytics engineering to run jobs and analyze information the place it exists with out incurring prices on egress/ingress. Moreover, since Bread is at all times seeking to optimize for information freshness, the core capabilities needed to contain a strong engine for dependable and speedy ingestion.
DMS & Auto Loader for change information ingestion
Impressed by this weblog, we selected AWS DMS (Database Migration Companies) for database snapshotting and alter information seize. The supply was our microservices that are backed by Postgres databases (RDS); the goal was a set of Amazon S3 buckets. We then ingested the DMS information with Auto Loader and repeatedly upserted change units into Delta Lake. We additionally refactored exterior jobs utilizing the newly accessible Databricks SQL Connector. The next sections clarify our rationale and implementation in larger technical element.
DMS configuration
In our setup, for every microservice, there’s a corresponding DMS process and S3 bucket. The migration consists of three main phases:
- The snapshot of present information (full load)
- The appliance of cached adjustments
- Ongoing replication (CDC)
We configured the additional connection attributes as such
cdcInsertsOnly=false;compressionType=GZIP;dataFormat=parquet;datePartitionEnabled=true;DatePartitionSequence=YYYYMMDD;includeOpForFullLoad=trueparquetTimestampInMillisecond=truetimestampColumnName=timestamp;DatePartitionDelimiter=NONE;
Given the above configuration, full load information are written to <microservice_bucket>/<schema_name>/<table_name>/LOAD*.parquet
CDC information are written to <microservice_bucket>/<schema_name>/<table_name>/yymmdd/*.parquet
The additional connection attributes partition the change information by date and add an “Op” column with “I”, “U”, or “D” attainable values, indicating if the change is an insert, replace, or delete operation.
An essential customization for us entails limitations utilizing S3 as a DMS goal. A few of our supply desk columns retailer massive binary objects (LoB). When utilizing S3 as a goal, full LoB mode shouldn’t be supported. We should specify a Lob MaxSize within the DMS process setting; DMS LoB columns will seem as Spark StringType. The MaxLobSize parameter is 32 (kb) by default. Primarily based on our calculation, we have to improve the worth to stop string truncation.
SELECT max(pg_column_size(col_name)) from source_table; ------- 17268DMS Replication handles every character as a double-byte character. Due to this fact, discover the size of the longest character textual content within the column
(max_num_chars_text)and multiply by 2 to specify the worth for Restrict LOB dimension to. On this case, Restrict LOB dimension is the same asmax_num_chars_textmultiplied by 2. Since our information consists of 4-byte characters, multiply by 2 once more:17268 * 4 ~ 70 kbSpark jobs
For every microservice, there’s a Snapshot Spark job that traverses the S3 DMS listing, finds all tables, masses the information into Databricks Delta Lake and creates preliminary tables. That is adopted by CDC ingestion spark jobs that find all tables, discover the newest state of every file, and merge the modified information into the corresponding Delta tables. Every time we run CDC ingestion, we additionally hold monitor of the schema and retailer the present model on S3.
When ingesting DMS change information, it’s important to determine the first key of supply tables. For many of our microservices, the first key’s “ID”. Some tables don’t observe this naming conference, and others use composite main keys. Due to this fact, the important thing columns to merge into have to be declared explicitly or created. We concatenate composite main key columns.
// Snapshot information ingestion snapshotData .withColumn("newest", to_timestamp(col("timestamp"))) .drop("timestamp") .write .format("delta") .mode("overwrite") .possibility("overwriteSchema", "true") .possibility("path",deltaTablePath) .saveAsTable(deltaTableName) // Change information ingestion changeData.writeStream .format("delta") .foreachBatch( Platform.cdcMerge( tableName = deltaTableName, pkColName = pkColName, timestampColName = "timestamp" ) _ ) .outputMode("replace") .possibility("checkpointLocation", checkpointPath) .possibility("mergeSchema", "true") .set off(Set off.As soon as()) .begin() // Merge perform def cdcMerge(tableName: String, pkColName: String, timestampColName: String)( microBatchChangeData: DataFrame, batchId: Lengthy ): Unit = { DeltaTable .forName(tableName) .as("t") .merge( microBatchChangeData .remodel( findLatestChangeByKey( windowColName = pkColName, strTimeColName = strTimeColName ) ) .as("c"), s"c.${pkColName} = t.${pkColName}" ) .whenMatched("c.Op == 'D'") .delete() .whenMatched() .updateAll() .whenNotMatched("c.Op != 'D'") .insertAll .execute() }Observe: Relying on how microservices carry out updates — for example, when information are changed in place — there may be concurrent inserts and updates. On this case, discovering the newest change by key might require customized ordering. Moreover, change information can arrive out of order. We might obtain a DMS file containing the eventual delete operation earlier than the file with insert or replace. Particular dealing with similar to CDC timestamp marking and utilizing a “untimely delete flag” could also be wanted to stop insertion of really deleted information.
Why use Auto Loader?
Databricks Auto Loader can routinely ingest information on cloud storage into Delta Lake. It permits us to make the most of the bookkeeping and fault-tolerant conduct built-in Structured Streaming, whereas protecting the price down near batching.
Price financial savings
Why not a standard structured streaming job? Streaming job clusters are on 24/7. The cluster can scale up, however not down. Throughout testing, we referred to as the cluster API and compelled the cluster to scale down each 2 hours. Compared, once we use the run as soon as set off to course of information at desired intervals (each 2 hours), our compute price decreased by greater than 90%, even with our naive scaler in place.
Streaming vs batch
How is utilizing Auto Loader totally different from merely operating a batch job? We do have batch jobs that load every day partitioned information from S3. Within the batch processing situation, we arrange an S3 sensor and a exchange the place logic to reprocess when obligatory. Structured Streaming, then again, commits all information created by the job to a log after every profitable set off. Within the occasion of failure, we are able to merely decide up the place we left off with out having separate processes to take away incorrect or duplicated information.
Notification vs listing itemizing mode
We’ve got seen DMS output many small information within the change information partition — sometimes a number of hundred in every day’s partition. Auto Loader’s notification mode can scale back the period of time taken by every Spark job itemizing file previous to ingestion. Nevertheless, on account of AWS limitations, file notification doesn’t have a particular SLA. We’ve got noticed that some information landed on S3 didn’t get found till the following day. As every enterprise day’s transaction have to be reported to our companions earlier than a cutoff time, notification mode shouldn’t be a dependable possibility for us.
Thankfully, in Databricks 9.0 and above, file itemizing has been tremendously optimized. Extra particulars on this enchancment may be discovered right here. In our situation, every job run solely takes ⅔ of the time in distinction to operating with DBR 8.4. The distinction in comparison with utilizing notification mode in 8.4 can be negligible. We now not have to sacrifice efficiency to ensure information freshness.
Use Databricks SQL connector to decrypt PII for information scientists
To totally migrate to a Lakehouse, we have to refactor a number of jobs operating on exterior techniques related to Snowflake, notably PII decryption on Amazon ECS. A subset of transformation depends on decrypted information and is important to BI work. We should reduce migration dangers and forestall disruption to enterprise features.
The ECS cluster is configured with entry to non-public keys for decryption. The keys are shared with microservices and saved in Vault. The job writes pandas dataframes to Snowflake and replaces present information every night time. Nonetheless, we have to resolve the next challenges:
- How will we hold the present ECS setup and secrets and techniques administration technique?
- Is it attainable to jot down to Delta Lake with out putting in Apache Spark as a dependency?
Because of Databricks SQL connector, we’re ready so as to add the databricks-sql-connector Python library to ECS, thereby utilizing a pyodbc connection beneath the hood to allow a easy information stream writing pandas dataframe to delta lake. Extra particulars on this connector may be discovered right here.
from databricks import sql for s in vary(0, conn_timeout): whereas True: attempt: connection = sql.join( server_hostname=getenv("DATABRICKS_HOST"), http_path=getenv("SQL_CONN"), access_token=getenv("DATABRICKS_TOKEN"), ) besides Exception as err: logger.warning(err) logger.data("retrying in 30s") sleep(30) proceed breakDatabricks SQL Connector is newly launched and an excellent match for distant connection to Databricks SQL or Clusters
The connector supplied sufficient flexibility so we’re capable of decrypt in chunks and upsert the information into Delta Lake, resulting in a efficiency enchancment over decrypting all information and changing your entire desk in Snowflake.
num_records = df.form[0] batch_num = math.ground(num_records / batch_size) cursor = connection.cursor() for i in vary(batch_num + 1): pdf = df.iloc[i * batch_size : (i + 1) * batch_size] insert_values = pdf.to_records(index=False, index_dtypes=None, column_dtypes=None).tolist() question = f"""MERGE INTO {database_name}.{delta_table_name} as Goal USING (SELECT * FROM (VALUES {",".be a part of([str(i) for i in insert_values])}) AS s ({key_col}, {",".be a part of(val_cols)})) AS Supply ON Goal.id=Supply.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *""" cursor.execute(question)Spark connector vs exterior tables
To assist Snowflake reporting work and consumer queries throughout migration, we examined utilizing Delta Lake Integration with Snowflake exterior tables. Finally, we opted for utilizing the Spark connector to repeat Delta tables into Snowflake previous to excessive profile, time-sensitive reporting duties. Listed here are our essential causes for transferring off exterior tables:
- Frequent schema adjustments: Though we configured auto refresh utilizing S3 notifications and queue system, Snowflake can not assist automated schema merge or replace as Delta Lake does. CREATE OR REPLACE and exterior desk auto refresh turned incompatible.
- Efficiency issues: Exterior tables have confirmed to be roughly 20% slower in comparison with copying the information over with Spark Connector.
- Inconsistent views of partitioned, vacuumed, and optimized tables: Sustaining exterior tables turned blockers for Delta Lake optimization.
- Lack of documentation and references: Exterior tables configuration may be complicated and experimental in nature; complete and correct documentation proved difficult to seek out.
- Lack of functionalities inside Snowflake: Very restricted potential to audit and debug exterior desk freshness and validity points.
Future information science instructions
As we productionize DMS/CDC ingestion and Databricks SQL connector, we centralize all our uncooked information in Delta Lake forming a single supply of firm info. We at the moment are able to construct out the Lakehouse imaginative and prescient, transferring computation and question to Databricks SQL, and paving the best way for close to real-time information science and analytics work. Under is the illustration of our platform pipeline (strong line for present state; dotted line for future state):
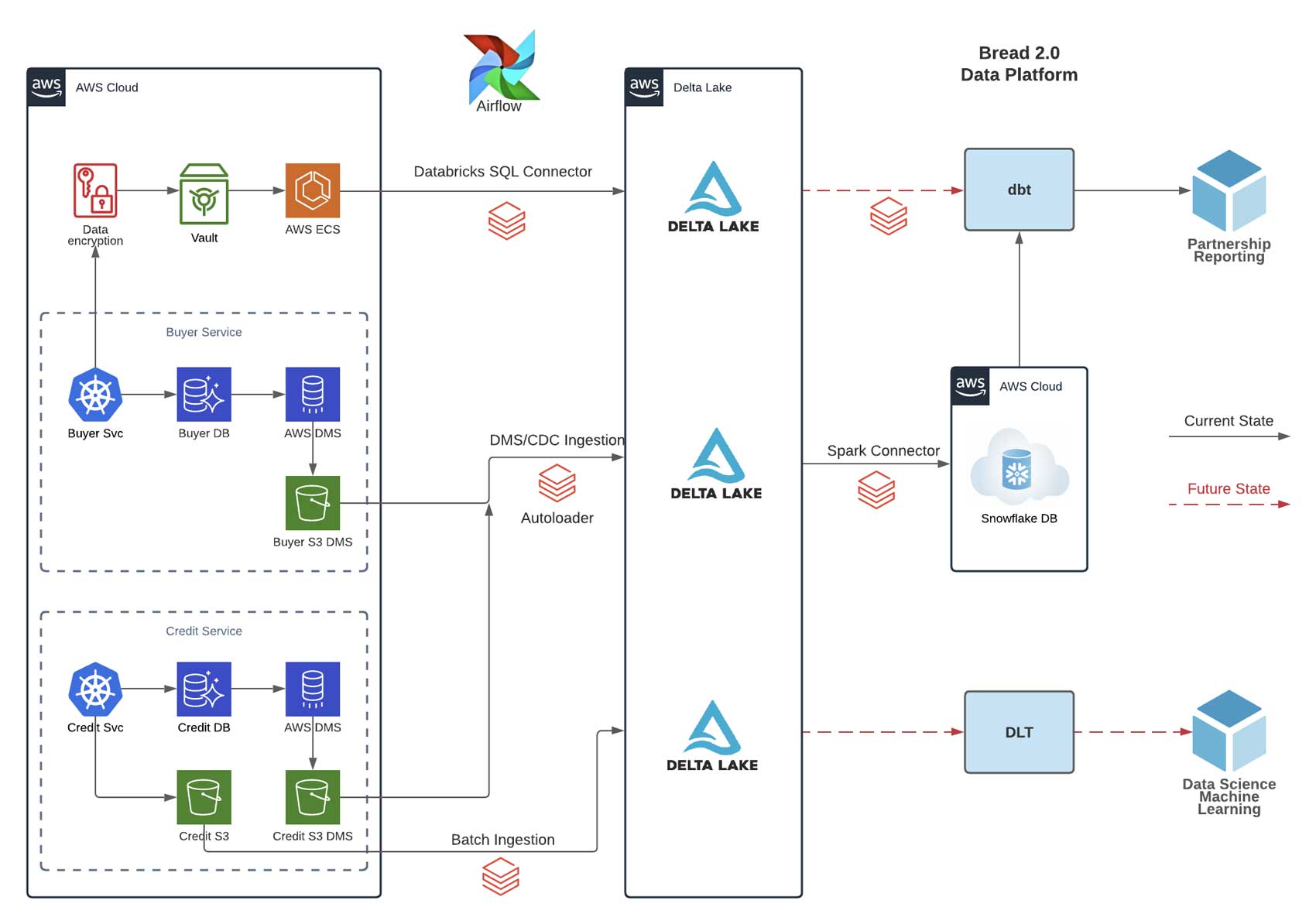
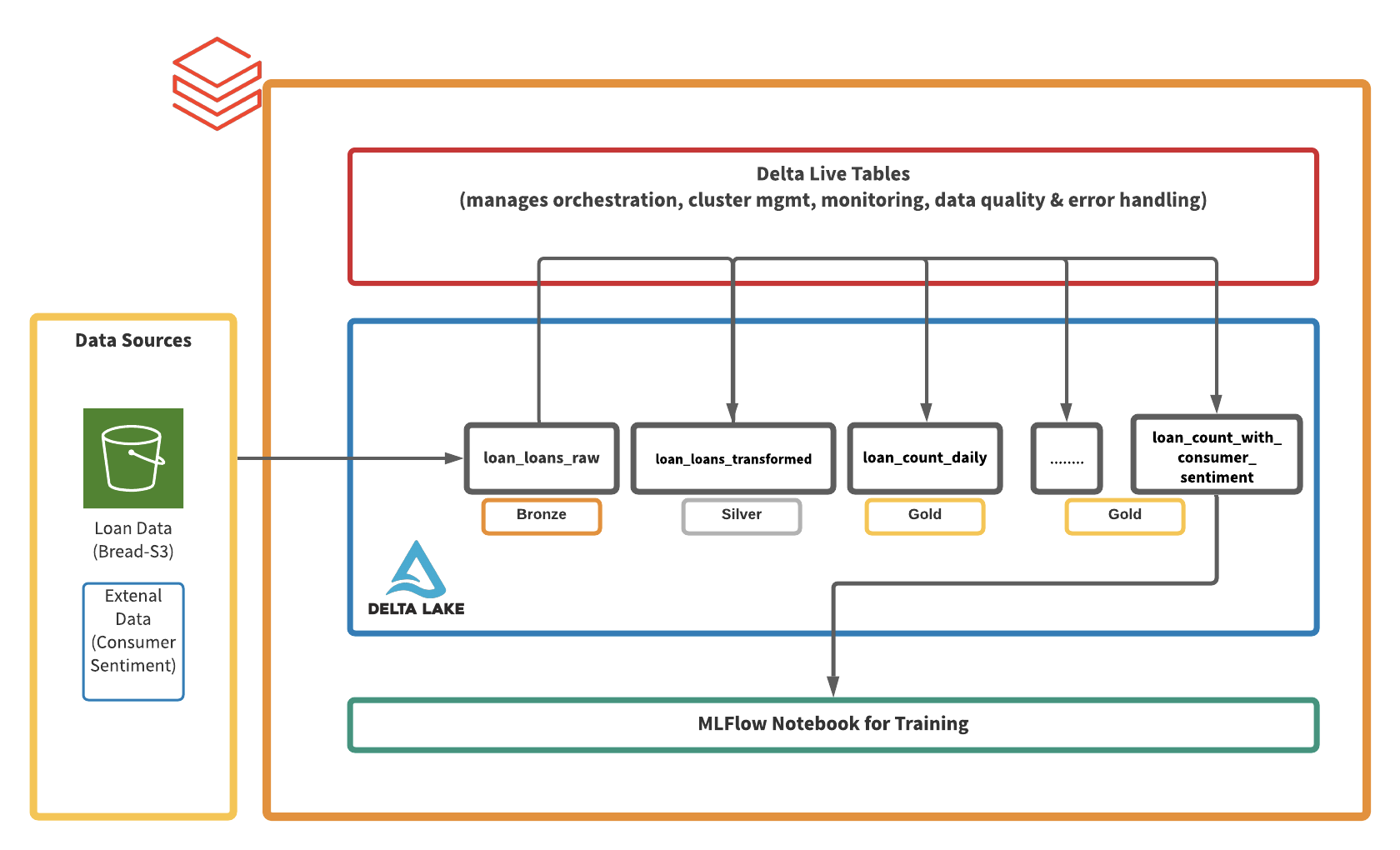
Delta Reside Tables + expectations for fast prototyping
Our present BI evaluation stream requires Knowledge Engineers to jot down spark jobs and deploy dbt fashions. To speed up ML improvement, we explored Delta Reside Tables operating on Photon, the next-generation question engine. Knowledge Engineers and Analysts collaborated intently and successfully combining Python and SQL. We had been notably excited by how rapidly we had been capable of ingest uncooked mortgage information saved on S3, be a part of exterior information units (e.g. client sentiment), validate information high quality, experiment with ML fashions in a pocket book surroundings, and visualize the leads to our BI instruments.
Under is an illustration of our Pipeline, from S3 information to Looker Dashboards delivered by Slackbot. Following are the principle causes we need to use DLT for future Knowledge Science work:
Velocity
In only a matter of hours, we are able to transfer from uncooked information to actionable insights and predictions. We are able to even repeatedly stream information from S3, and construct in expectations for validation.
Democratization
Analysts and information scientists can work straight on an end-to-end pipeline with out intensive assist from engineering. We are able to additionally collaborate and blend languages in a single pipeline.
Unification
All levels of the deployment exist in a single place, from information load, orchestration to machine studying. The pipeline lives with its execution engine.
Conclusion
On this weblog, we demonstrated how Bread is constructing a resilient, scalable information platform with Databricks Delta Lake: We use AWS DMS and Databricks Auto Loader jobs to incrementally seize adjustments from RDS information sources and repeatedly merge CDC information into Delta Lake. We additionally showcased tips on how to migrate jobs exterior to Databricks utilizing the native Databricks SQL connector. As soon as we full constructing the centralized information lake, our subsequent steps shall be making the most of Photon SQL Analytics endpoints and DLT pipelines to allow close to real-time BI and ML work with a lot less complicated configurations and fewer engineering dependency.
[ad_2]